
效果提升4倍!这样做模型预测才是真香啊!
↓推荐关注↓
大家好,前两天有粉丝问有关算法预测的问题。今天我们就以股价预测为例,分享一下两种预测方法:
常规方式股票预测 全新方式股票预测
经过验证,全新方式预测效果是常规方式的4倍,喜欢本文记得点赞、收藏、关注。
1. 常规方式股票预测
1.1 数据集介绍
本文使用的股价数据集来自GitHib:https://github.com/pierpaolo28/Data-Visualization/blob/master/Dash/stock_data.csv。
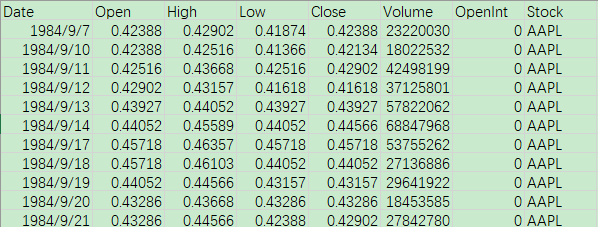
下载数据集后,查看其内容,可以看到数据集中包含时间、开盘时股价等一系列相关信息,本文需要预测的是股价当天的最终价格,即 Close 列的数据:
1.2 模型分析
为了预测股价,我们根据以下思路构建神经网络模型:
按照时间发生顺序对数据集进行排序 以前五个股票价格数据作为输入,第六个股票价格数据作为输出 滑动时间窗口,在模型的下一个输入使用第二个到第六个数据,并将第七个数据作为输出,依此类推,直到到达最后一个数据点 由于我们需要预测的是一个连续值,因此损失函数使用均方误差值 此外,我们还将在下个环节尝试利用文本数据集成到历史股票价格数据中,以预测第二天股价的情况
1.3 使用神经网络进行股价预测
根据以上模型的思路,接下来,我们使用 Keras 实现神经网络模型用于预测股价。
1.导入相关的包和数据集:
import pandas as pd
data2 = pd.read_csv('content/stock_data.csv')
2.按照前述分析准备数据集,其中输入是前五天的股票价格,输出是第六天的股票价格:
x = []
y = []
for i in range(data2.shape[0]-5):
x.append(data2.loc[i:(i+4)]['Close'].values)
y.append(data2.loc[i+5]['Close'])
import numpy as np
x = np.array(x)
y = np.array(y)
3.准备训练和测试数据集,构建模型:
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)
from keras.layers import Dense
from keras.models import Sequential
model = Sequential()
model.add(Dense(100, input_dim=5, activation='relu'))
model.add(Dense(1, activation='linear'))
4.建立模型并进行编译:
model.compile(optimizer='adam', loss='mean_squared_error')
model.summary()
看以看到,模型的简要信息输出如下:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param
=================================================================
dense (Dense) (None, 100) 600
_________________________________________________________________
dense_1 (Dense) (None, 1) 101
=================================================================
Total params: 701
Trainable params: 701
Non-trainable params: 0
_________________________________________________________________
可以看到,训练集股价的均方误差值约为 320,而预测集股价的均方误差值约为 330,以这种方式预测股价存在较大的问题。
在下一部分中,我们将学习如何在模型中将股价价格数据与新闻标题的文本数据集成在一起的方式进行预测。
2.全新方式股价预测
2.1 模型分析
在本节中,我们将股票历史价格数据与我们要预测股价的公司最近的相关新闻标题相集成,以提高股价预测的准确性。
我们将整合来自多个来源的数据——结构化(历史股价)数据和非结构化(新闻标题)数据——进行股价预测。
模型构建策略如下:
将非结构化文本转换为结构化格式的方式类似于在新闻分类中所使用方式 通过神经网络传递文本信息,并提取隐藏层输出 最后,将隐藏层的输出传递到输出层,其中输出层具有一个节点 以类似的方式,将输入的历史价格数据通过神经网络传递,以提取隐藏层输出,然后将其传递到输出层,输出层具有一个节点 将两个神经网络的输出相乘以得到最终输出 最小化最终输出的平方误差值
2.2 结合新闻数据预测股价
根据以上策略,模型实现程序如下。
1.从Guardian(https://content.guardianapis.com)提供的 API 中获取标题数据,如下所示:
from bs4 import BeautifulSoup
import urllib, json
dates = []
titles = []
for i in range(100):
try:
url = 'https://content.guardianapis.com/search?from-date=2010-01-01§ion=business&page-size=200&order-by=newest&page='+str(i+1)+'&q=amazon&api-key=207b6047-a2a6-4dd2-813b-5cd006b780d7'
response = urllib.request.urlopen(url)
encoding = response.info().get_content_charset('utf8')
data = json.loads(response.read().decode(encoding))
for j in range(len(data['response']['results'])):
dates.append(data['response']['results'][j]['webPublicationDate'])
titles.append(data['response']['results'][j]['webTitle'])
except:
break
2.提取标题和日期后,对数据进行预处理,以将日期值转换为日期格式,如下所示:
import pandas as pd
data = pd.DataFrame(dates, titles)
data = data.reset_index()
data.columns = ['title','date']
data['date']=data['date'].str[:10]
data['date']=pd.to_datetime(data['date'], format = '%Y-%m-%d')
data = data.sort_values(by='date')
data_final = data.groupby('date').first().reset_index()
3.对于要预测股价的每个日期,我们获得相应日期的公司的相关新闻标题,接下来整合两个数据源,如下所示:
data2['Date'] = pd.to_datetime(data2['Date'],format='%Y-%m-%d')
data3 = pd.merge(data2,data_final, left_on = 'Date', right_on = 'date', how='left')
4.合并数据集后,我们将继续对文本数据进行规范化,首先对数据进行如下处理:
将文本中的所有单词都转换为小写字母,以便可以将 Text和text单词被视为相同值删除标点符号,使诸如 text.和text被视为相同文本删除停用词,例如 a和and,它们不会为文本增加过多上下文
import nltk
import re
stop = nltk.corpus.stopwords.words('english')
def preprocess(text):
text = str(text)
text=text.lower()
text=re.sub('[^0-9a-zA-Z]+',' ',text)
words = text.split()
words2=[w for w in words if (w not in stop)]
words4=' '.join(words2)
return(words4)
data3['title'] = data3['title'].apply(preprocess)
5.用连字符 “-” 替换标题中的空值:
data3['title']=np.where(data3['title'].isnull(),'-','-'+data3['title'])
6.现在我们已经预处理了文本数据,为每个单词分配一个 ID。完成此任务后,我们可以按照与新闻分类中类似的方法执行文本分析,如下所示:
docs = data3['title'].values
from collections import Counter
counts = Counter()
for i,review in enumerate(docs):
counts.update(review.split())
words = sorted(counts, key=counts.get, reverse=True)
vocab_size=len(words)
word_to_int = {word: i for i, word in enumerate(words, 1)}
7.既然我们已经对所有单词进行了编码,那么我们在原始文本中将其替换为相应的索引值:
encoded_docs = []
for doc in docs:
encoded_docs.append([word_to_int[word] for word in doc.split()])
def vectorize_sequences(sequences, dimension=vocab_size):
results = np.zeros((len(sequences), dimension+1))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1.
return results
vectorized_docs = vectorize_sequences(encoded_docs)
现在我们已经对文本进行了编码,接下来,我们将两个数据源集成在一起,以进行更好的预测。
8.首先,准备训练和测试数据集,如下所示:
x1 = np.array(x)
x2 = np.array(vectorized_docs[5:])
y = np.array(y)
x1_train = x1[:2100,:]
x2_train = x2[:2100, :]
y_train = y[:2100]
x1_test = x1[2100:,:]
x2_test = x2[2100:,:]
y_test = y[2100:]
通常,当模型有多个输入或多个输出时,我们将使用函数式 API 构建模型,本例中模型有多个输入,因此将使用函数式 API。
9.本质上,函数式 API 打破了顺序构建模型的过程,可以按照数据流的计算顺序构建模型:
from keras.layers import Dense, Input
from keras import Model
import keras.backend as K
input1 = Input(shape=(vectorized_docs.shape[1],))
model = (Dense(100, activation='relu'))(input1)
model = (Dense(1, activation='tanh'))(model)
在前面的代码中,没有使用顺序建模过程,而是使用 Dense 层定义了层与层之间的连接。输入的形状为 2406,因为在上述过滤过程之后剩下 2406 个不同的词。
10.利用时间窗口策略,取5个股票价格作为输入并构建另一模型:
input2 = Input(shape=(5,))
model2 = (Dense(100, activation='relu'))(input2)
model2 = (Dense(1, activation='linear'))(model2)
11.将上述两个模型的输出相乘,得到最终结果:
from keras.layers import multiply
out = multiply([model, model2])
12.我们已经定义了输入、输出,接下来,就可以按照以下方式构建模型:
model = Model([input1, input2], out)
model.summary()
以上代码中,我们使用 “Model” 层定义了输入(作为列表传递)和输出,模型的概要信息输出如下:
__________________________________________________________________________________________________
Layer (type) Output Shape Param
==================================================================================================
input_1 (InputLayer) (None, 2406) 0
__________________________________________________________________________________________________
input_2 (InputLayer) (None, 5) 0
__________________________________________________________________________________________________
dense_1 (Dense) (None, 100) 240700 input_1[0][0]
__________________________________________________________________________________________________
dense_3 (Dense) (None, 100) 600 input_2[0][0]
__________________________________________________________________________________________________
dense_2 (Dense) (None, 1) 101 dense_1[0][0]
__________________________________________________________________________________________________
dense_4 (Dense) (None, 1) 101 dense_3[0][0]
__________________________________________________________________________________________________
multiply_1 (Multiply) (None, 1) 0 dense_2[0][0]
dense_4[0][0]
==================================================================================================
Total params: 241,502
Trainable params: 241,502
Non-trainable params: 0
__________________________________________________________________________________________________
接下来,将模型架构进行可视化,如下:
plot_model(model, show_shapes=True, show_layer_names=True, to_file='model.png')
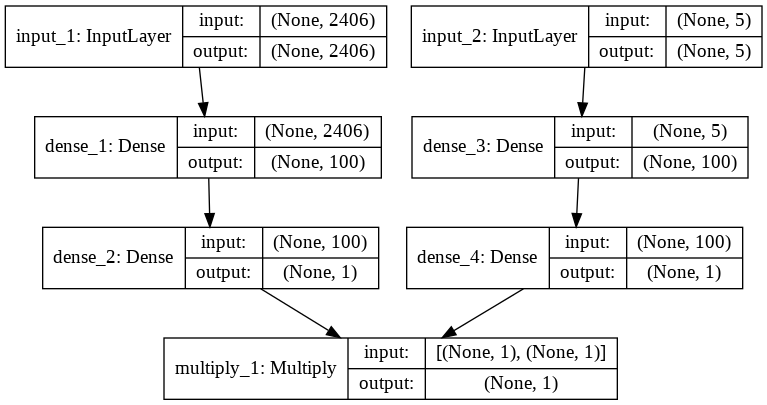
编译并拟合模型:
model.compile(optimizer='adam', loss='mean_squared_error')
model.fit(x=[x2_train, x1_train], y=y_train,
epochs=100,
batch_size=32,
validation_data=([x2_test, x1_test], y_test),
verbose=1)
前面的模型在训练集上产生的均方误差仅约为70,并且可以看出模型过拟合,因为训练数据集的损失远低于测试数据集的损失。
小结
本节通过股价预测为例,学习了函数式API方式来构建复杂神经网络,准确率提升将近4倍。
长按或扫描下方二维码,后台回复:加群,即可申请入群。一定要备注:来源+研究方向+学校/公司,否则不拉入群中,见谅!
(长按三秒,进入后台)
推荐阅读
