
Atlas血缘分析在数据仓库中的实战案例

Hi,我是王知无,一个大数据领域的原创作者。 放心关注我,获取更多行业的一手消息。
目录
一、应用
1.1 执行SQL
1.2 手写的数据地图
1.3 atlas血缘分析
1.4 打标签
1.4.1 CLASSIFICATION分类
1.4.2 GLOSSARY词汇表
1.5 字段搜索
1.5.1查看表字段
1.5.2 追踪字段关系
二、安装
2.1 编译安装
2.1.1 下载源码
2.1.2 组件修改版本
2.1.3 修改报错代码
2.1.4 编译
2.1.5 编译包
2.1.6 复制包
2.1.7 解压
2.2 部署
2.2.1 修改配置
2.2.2 配置环境变量
三、运行
3.1 启动
3.2 访问
四、配置 HOOK
4.1 Hive Hook
4.1.1 设置Atlas配置目录
4.1.2 设置环境变量
4.1.3 把压缩包上传
4.1.4 解压包
4.1.5 添加Hive的第三方依赖包
4.1.6 导入Hive数据
4.1.7 压缩配置文件到 Jar
4.1.8 软连接 Atlas hook 文件
4.1.9 修改hive-site.xml,配置Hive Hook
4.1.10 重启Hive
4.2 Sqoop Hook
4.2.1 设置Atlas配置目录
4.2.2 设置环境变量
4.2.3 把压缩包上传
4.2.4 解压包
4.2.5 压缩配置文件到 Jar
4.2.6 软连接 Sqoop hook 文件
4.2.7 修改sqoop-site.xml,配置Sqoop Hook
一、应用
1.1 执行SQL
--创建临时表(取出最新一条访问记录)
DROP TABLE IF EXISTS tmp.tmp_ng;
CREATE TABLE tmp.tmp_ng STORED AS parquet AS
SELECT userid,
pageid,
pagetype,
os,
terminal_type,
pagetime
FROM (
SELECT uid userid,
CAST(pageid AS INT) pageid,
pagetype,
os,
terminal_type,
pagetime,
row_number() OVER(
PARTITION BY uid,
pageid
ORDER BY pagetime DESC
) rk
FROM dw.dw_nginxlog
WHERE dt = '2020-11-02'
) t1
WHERE rk = 1 --用户访问各个页面的及设备
;
--统计三个页面的访问及设备
INSERT OVERWRITE TABLE dwd.dwd_hive_fact_nginx_visit_ext_dt PARTITION(dt = '2020-11-03')
SELECT zbid,
userid,
os,
terminal_type
FROM (
SELECT zbid,
userid,
os,
terminal_type,
row_number() OVER(
PARTITION BY zbid,
userid
ORDER BY pagetime DESC
) rk
FROM (
SELECT tp.zbid,
t1.userid,
t1.os,
t1.terminal_type,
t1.pagetime
FROM (
SELECT userid,
pageid,
os,
terminal_type,
pagetime
FROM tmp.tmp_ng
WHERE pagetype = 1 --话题类型
) t1
LEFT JOIN (
SELECT zbid,
topicid
FROM dwd.dwd_minisns_zbtopics_ds
WHERE dt = '2020-11-02'
) tp --快照表
ON t1.pageid = tp.topicid
UNION ALL
SELECT tp.zbid,
t2.userid,
t2.os,
t2.terminal_type,
t2.pagetime
FROM (
SELECT userid,
pageid,
os,
terminal_type,
pagetime
FROM tmp.tmp_ng
WHERE pagetype = 2 --频道类型
) t2
LEFT JOIN dw.dw_zbchannel tp ON t2.pageid = tp.channelid
) t3
) t4
WHERE rk = 1;
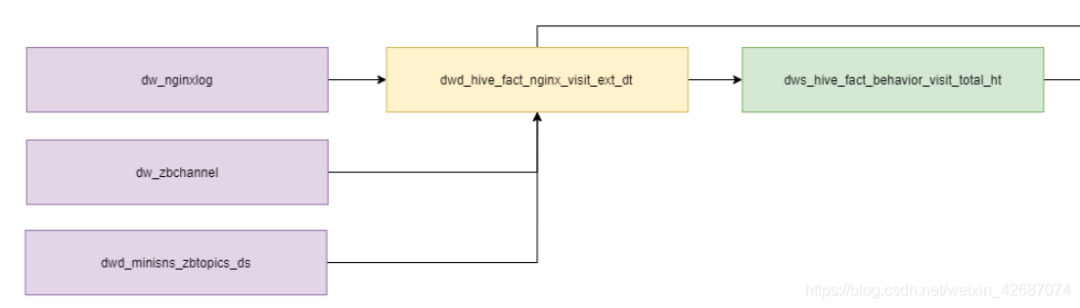
1.2 手写的数据地图
1.3 atlas血缘分析
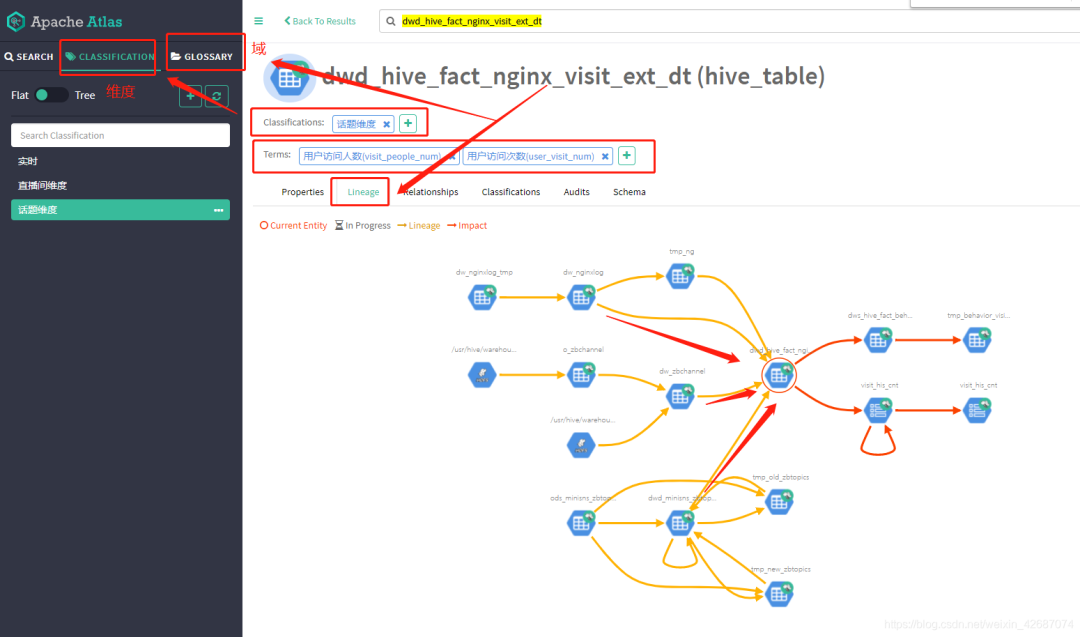
说明:通过对比,Atlas能够更加准确地解析所有脚本SQL语句,在全局角度能够看到上下游关系,不过自己手动维护的好处的是能够更加方便地迭代维护。可以通过自己对表的理解划分到不同的域和维度,方便维护。
1.4 打标签
1.4.1 CLASSIFICATION分类
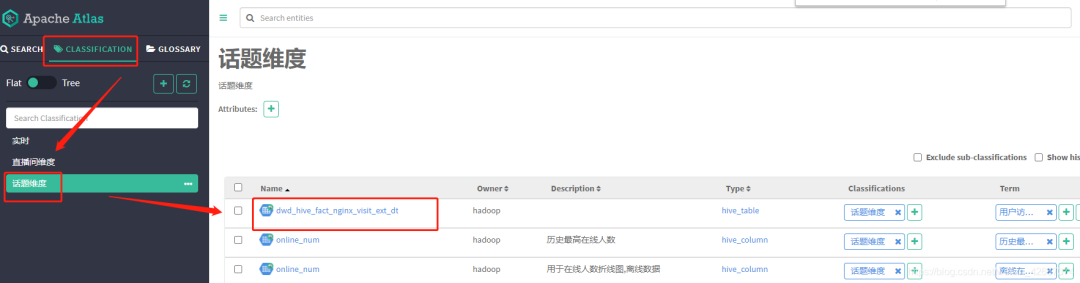
说明:按自己项目的需求划分不同得维度
1.4.2 GLOSSARY词汇表
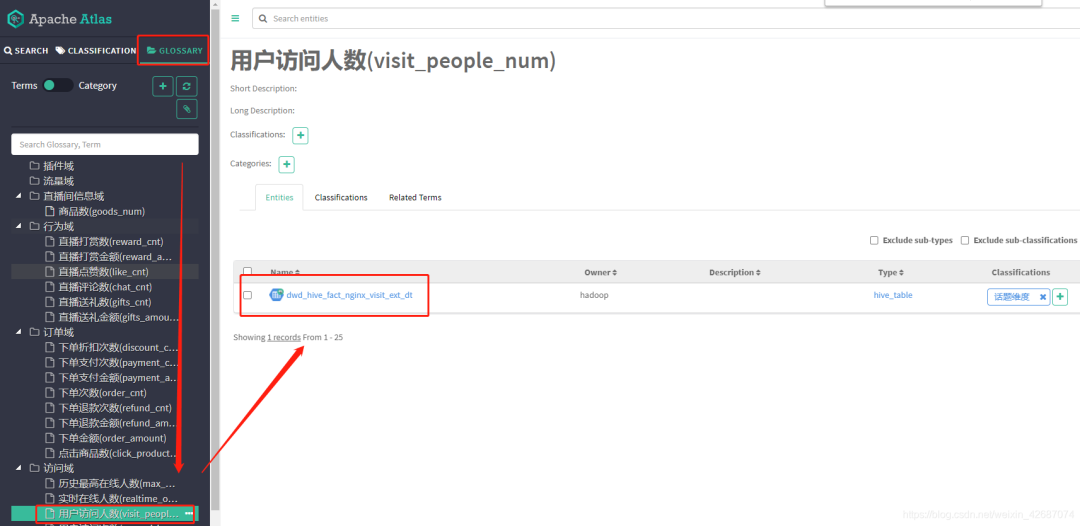
说明:一个数据仓库项目有很多域,域下面还有很多层次,可以按自己项目需求规划。
1.5 字段搜索
1.5.1查看表字段
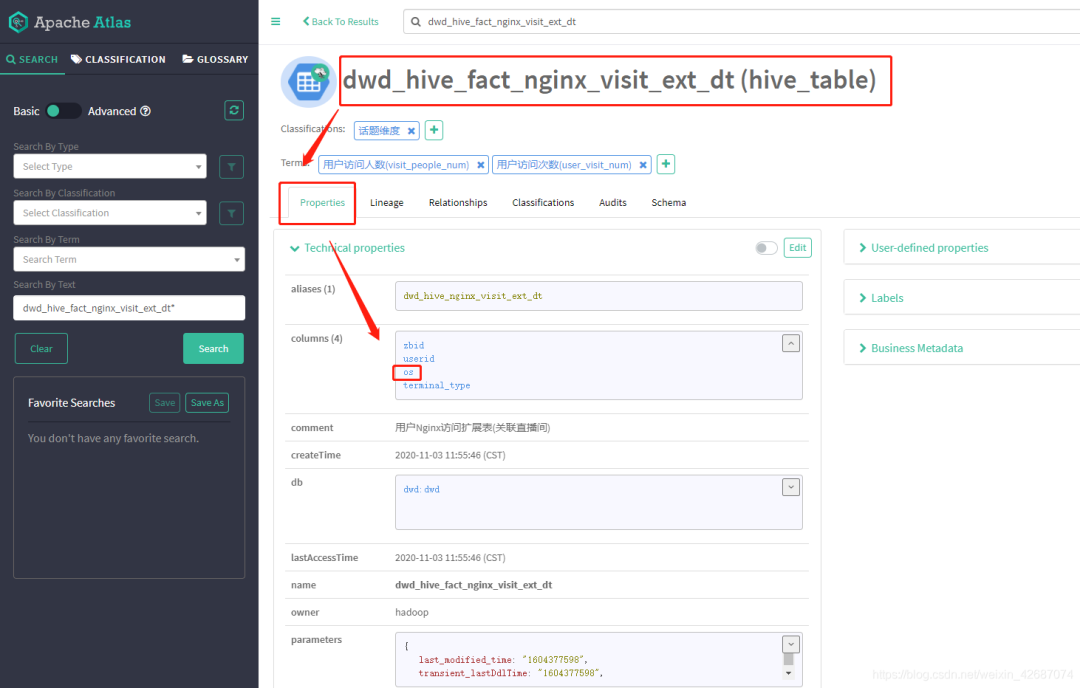
1.5.2 追踪字段关系
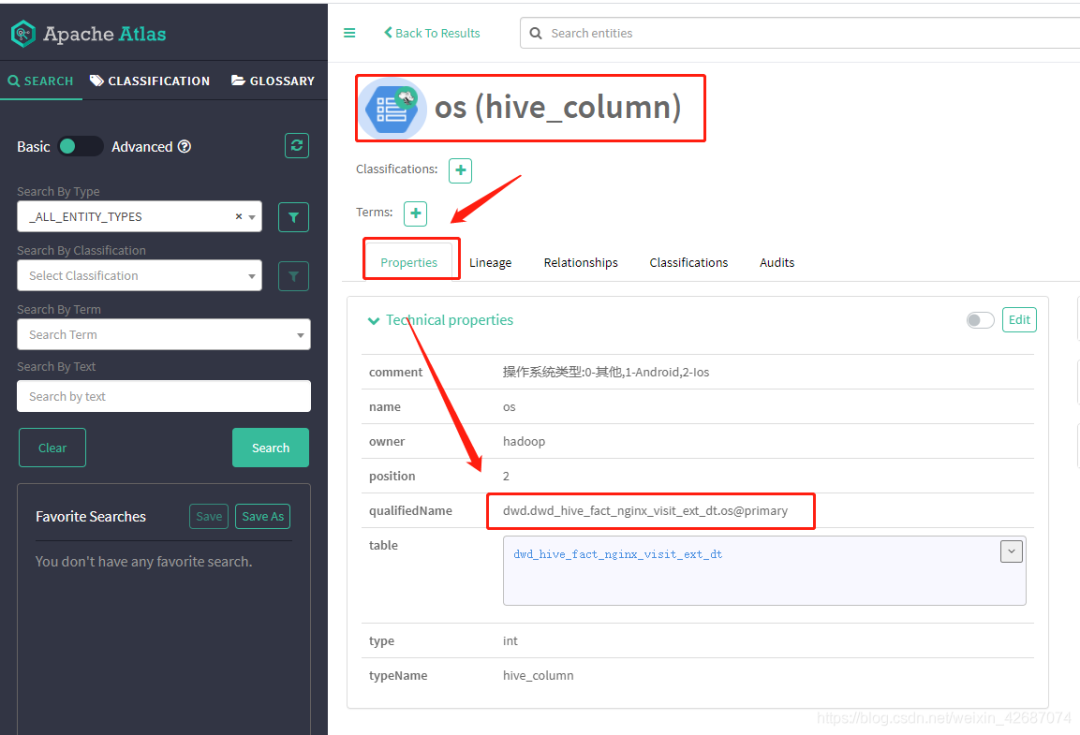
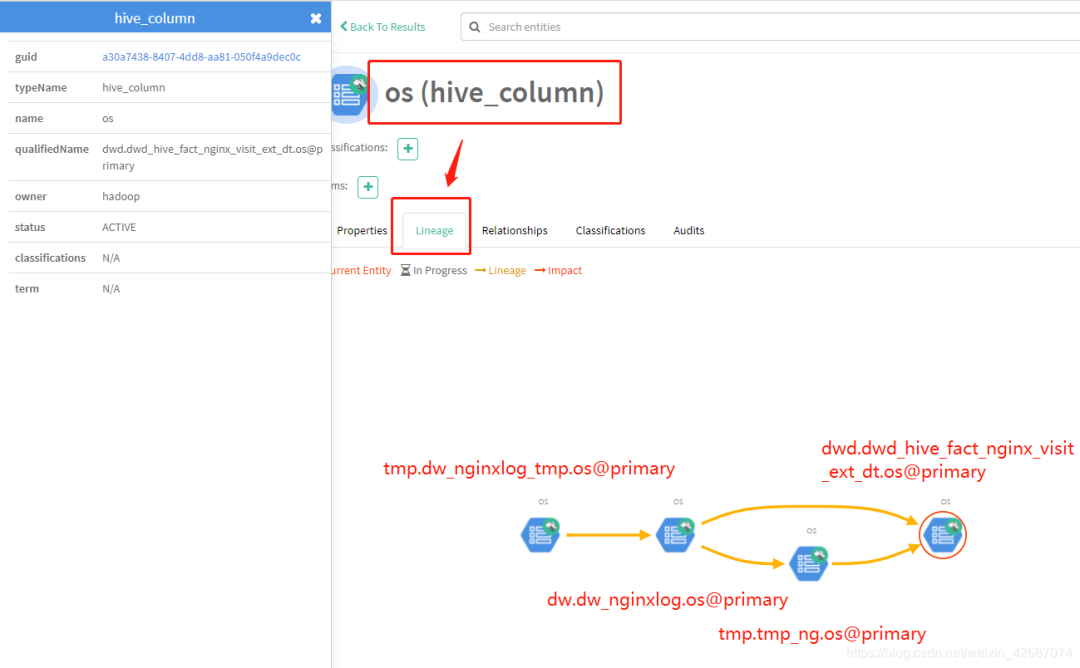
说明:强大地血缘关系可以直接查看出整条字段的数据链路。
二、安装
2.1 编译安装
2.1.1 下载源码
git clone --branch branch-2.0 https://gitee.com/mirrors/apache-atlas.git apache-atlas_branch-2.0
2.1.2 组件修改版本
2.8.5
1.4.9
2.0.0
2.3.5
3.4.6
0.8
1.4.6.2.3.99.0-195
1.2.0
7.1.0
2.6.5
2.6.5
1.6
注意:
去除 pom.xml 的 hbase-zookeeper 依赖
2.1.3 修改报错代码
hbase2.X --> hbase1.X
ColumnFamilyDescriptor --> HColumnDescriptor
TableDescriptor --> HTableDescriptor
2.1.4 编译
export MAVEN_OPTS="-Xms2g -Xmx2g"
mvn clean package -Pdist -Dmaven.test.skip=true -Dmaven.javadoc.skip=true -Dmaven.source.skip=true
2.1.5 编译包
distro/target/apache-atlas-{project.version}-bin.tar.gz
distro/target/apache-atlas-{project.version}-falcon-hook.tar.gz
distro/target/apache-atlas-{project.version}-hbase-hook.tar.gz
distro/target/apache-atlas-{project.version}-hive-hook.gz
distro/target/apache-atlas-{project.version}-impala-hook.gz
distro/target/apache-atlas-{project.version}-kafka-hook.gz
distro/target/apache-atlas-{project.version}-server.tar.gz
distro/target/apache-atlas-{project.version}-sources.tar.gz
distro/target/apache-atlas-{project.version}-sqoop-hook.tar.gz
distro/target/apache-atlas-{project.version}-storm-hook.tar.gz
2.1.6 复制包
mkdir -p /opt/package/atlas/
安装 nc
yum install nc -y
nc -l 33880 > /opt/package/atlas/apache-atlas-2.2.0-SNAPSHOT-bin.tar.gz
nc 10.0.11.10 33880 < /data/build/apache-atlas/distro/target/apache-atlas-2.2.0-SNAPSHOT-bin.tar.gz
2.1.7 解压
mkdir -p /opt/service/atlas/
rm -rf /opt/service/atlas/apache-atlas-2.2.0-SNAPSHOT
tar -zxf /opt/package/atlas/apache-atlas-2.2.0-SNAPSHOT-bin.tar.gz -C /opt/service/atlas/
2.2 部署
2.2.1 修改配置
进入conf 目录
vim atlas-env.sh
export JAVA_HOME=/usr/local/jdk
export HBASE_CONF_DIR=/usr/local/service/hbase/conf
export ATLAS_SERVER_HEAP="-Xms2048m -Xmx15360m -XX:MaxNewSize=5120m -XX:MetaspaceSize=100M -XX:MaxMetaspaceSize=512m"
vim atlas-application.properties
# hbase 配置
atlas.graph.storage.hbase.table=apache_atlas_janus_test
atlas.graph.storage.hostname=10.0.11.6
# 使用 elasticsearch 存储索引
atlas.graph.index.search.backend=elasticsearch
atlas.graph.index.search.index-name=test_janusgraph
# elasticsearch 配置
# elasticsearch 地址
atlas.graph.index.search.hostname=10.0.12.47,10.0.12.47:9201,10.0.12.47:9202
atlas.graph.index.search.elasticsearch.client-only=true
atlas.graph.index.search.elasticsearch.http.auth.type=basic
atlas.graph.index.search.elasticsearch.http.auth.basic.username=elastic
atlas.graph.index.search.elasticsearch.http.auth.basic.password=Qaz@4321
# kafak 配置
atlas.notification.embedded=false
# atlas.kafka.data=${sys:atlas.home}/data/kafka
atlas.kafka.zookeeper.connect=10.0.11.6:2181
atlas.kafka.bootstrap.servers=10.0.12.95:9092
atlas.kafka.zookeeper.session.timeout.ms=400
atlas.kafka.zookeeper.connection.timeout.ms=200
atlas.kafka.zookeeper.sync.time.ms=20
atlas.kafka.auto.commit.interval.ms=1000
atlas.kafka.hook.group.id=atlas
atlas.kafka.enable.auto.commit=false
atlas.kafka.auto.offset.reset=earliest
atlas.kafka.session.timeout.ms=30000
atlas.kafka.offsets.topic.replication.factor=2
atlas.kafka.poll.timeout.ms=1000
atlas.notification.hook.topic.name=ATLAS_HOOK_TEST
atlas.notification.entities.topic.name=ATLAS_ENTITIES_TEST
atlas.notification.hook.consumer.topic.names=ATLAS_HOOK_TEST
atlas.notification.entities.consumer.topic.names=ATLAS_ENTITIES_TEST
atlas.notification.create.topics=false
atlas.notification.replicas=2
atlas.notification.topics=ATLAS_HOOK_TEST,ATLAS_ENTITIES_TEST
atlas.notification.log.failed.messages=true
atlas.notification.consumer.retry.interval=500
atlas.notification.hook.retry.interval=1000
# 服务地址
atlas.rest.address=http://10.0.11.10:21000
# hbase zookeeper地址
atlas.audit.hbase.tablename=apache_atlas_entity_audit_test
atlas.audit.hbase.zookeeper.quorum=10.0.11.6
atlas.audit.hbase.zookeeper.property.clientPort=2181
atlas.ui.default.version=v2
vim atlas-log4j.xml
"perf_appender" class="org.apache.log4j.DailyRollingFileAppender">
"file" value="${atlas.log.dir}/atlas_perf.log" />
"datePattern" value="'.'yyyy-MM-dd" />
"append" value="true" />
"org.apache.log4j.PatternLayout">
"ConversionPattern" value="%d|%t|%m%n" />
"org.apache.atlas.perf" additivity="false">
"debug" />
"perf_appender" />
2.2.2 配置环境变量
vim /etc/profile
export ATLAS_HOME=/opt/service/atlas/apache-atlas-2.2.0-SNAPSHOT
export PATH=$PATH:$ATLAS_HOME/bin
export JAVA_TOOL_OPTIONS="-Datlas.conf=/opt/service/atlas/apache-atlas-2.2.0-SNAPSHOT/conf"
source /etc/profile
三、运行
3.1 启动
atlas_start.py
说明:第一次启动,开始初始化安装,需要大约一个小时
3.2 访问
http://localhost:21000/
用户名:admin
密码:admin
四、配置 HOOK
4.1 Hive Hook
说明:每个Hive节点都配置
4.1.1 设置Atlas配置目录
mkdir -p /opt/service/atlas/apache-atlas-2.2.0-SNAPSHOT/conf
把安装Atlas节点 atlas-application.properties , atlas-env.sh , atlas-log4j.xml 拷贝放在conf目录下
4.1.2 设置环境变量
vim /etc/profile
export ATLAS_HOME=/opt/service/atlas/apache-atlas-2.2.0-SNAPSHOT
export JAVA_TOOL_OPTIONS="-Datlas.conf=/opt/service/atlas/apache-atlas-2.2.0-SNAPSHOT/conf"
source /etc/profile
4.1.3 把压缩包上传
mkdir -p /opt/package/atlas/
#把压缩包上传到 /opt/package/atlas/ 目录下
安装nc
yum install nc -y
nc -l 33880 > /opt/package/atlas/apache-atlas-2.2.0-SNAPSHOT-hive-hook.tar.gz
nc 10.0.12.114 33880 < /data/build/apache-atlas/distro/target/apache-atlas-2.2.0-SNAPSHOT-hive-hook.tar.gz
4.1.4 解压包
mkdir -p /opt/service/atlas/apache-atlas-2.2.0-SNAPSHOT
unalias rm
rm -rf /opt/service/atlas/apache-atlas-2.2.0-SNAPSHOT/apache-atlas-hive-hook-2.2.0-SNAPSHOT
tar -zxf /opt/package/atlas/apache-atlas-2.2.0-SNAPSHOT-hive-hook.tar.gz -C /opt/service/atlas/apache-atlas-2.2.0-SNAPSHOT
4.1.5 添加Hive的第三方依赖包
第三方依赖包目录: $HIVE_HOME/auxlib
4.1.5.1 elasticsearch-hive 依赖:
elasticsearch-hadoop-hive-7.1.0.jar
移除 elasticsearch-hadoop.jar
4.1.5.2 Hive-kudu 依赖:
hive-kudu-handler-1.10.0.jar
4.1.6 导入Hive数据
cd /opt/service/atlas/apache-atlas-2.2.0-SNAPSHOT/apache-atlas-hive-hook-2.2.0-SNAPSHOT
./hook-bin/import-hive.sh
说明:输入用户名和密码,大约两个小时就导完,视表的量决定
4.1.7 压缩配置文件到 Jar
cd $ATLAS_HOME/conf/
zip -u $ATLAS_HOME/apache-atlas-hive-hook-2.2.0-SNAPSHOT/hook/hive/atlas-plugin-classloader-2.2.0-SNAPSHOT.jar atlas-application.properties
4.1.8 软连接 Atlas hook 文件
ln -s /opt/service/atlas/apache-atlas-2.2.0-SNAPSHOT/apache-atlas-hive-hook-2.2.0-SNAPSHOT/hook/hive/atlas-plugin-classloader-2.2.0-SNAPSHOT.jar /usr/local/service/hive/lib/atlas-plugin-classloader-2.2.0-SNAPSHOT.jar
ln -s /opt/service/atlas/apache-atlas-2.2.0-SNAPSHOT/apache-atlas-hive-hook-2.2.0-SNAPSHOT/hook/hive/hive-bridge-shim-2.2.0-SNAPSHOT.jar /usr/local/service/hive/lib/atlas-hive-bridge-shim-2.2.0-SNAPSHOT.jar
ln -s /opt/service/atlas/apache-atlas-2.2.0-SNAPSHOT/apache-atlas-hive-hook-2.2.0-SNAPSHOT/hook/hive/atlas-hive-plugin-impl /usr/local/service/hive/lib/atlas-hive-plugin-impl
4.1.9 修改hive-site.xml,配置Hive Hook
hive.exec.post.hooks
org.apache.atlas.hive.hook.HiveHook
hive.metastore.event.listeners
org.apache.atlas.hive.hook.HiveMetastoreHook
4.1.10 重启Hive
4.2 Sqoop Hook
说明:每个Hive节点都配置
4.2.1 设置Atlas配置目录
mkdir -p /opt/service/atlas/apache-atlas-2.2.0-SNAPSHOT/conf
#把安装Atlas节点 atlas-application.properties , atlas-env.sh , atlas-log4j.xml 拷贝放在conf目录下
4.2.2 设置环境变量
vim /etc/profile
export ATLAS_HOME=/opt/service/atlas/apache-atlas-2.2.0-SNAPSHOT
export JAVA_TOOL_OPTIONS="-Datlas.conf=/opt/service/atlas/apache-atlas-2.2.0-SNAPSHOT/conf"
source /etc/profile
4.2.3 把压缩包上传
mkdir -p /opt/package/atlas/
#把压缩包上传到 /opt/package/atlas/ 目录下
安装nc
yum install nc -y
nc -l 33880 > /opt/package/atlas/apache-atlas-2.2.0-SNAPSHOT-sqoop-hook.tar.gz
nc 10.0.12.114 33880 < /data/build/apache-atlas/distro/target/apache-atlas-2.2.0-SNAPSHOT-sqoop-hook.tar.gz
4.2.4 解压包
mkdir -p /opt/service/atlas/apache-atlas-2.2.0-SNAPSHOT
unalias rm
rm -rf /opt/service/atlas/apache-atlas-2.2.0-SNAPSHOT/apache-atlas-sqoop-hook-2.2.0-SNAPSHOT
tar -zxf /opt/package/atlas/apache-atlas-2.2.0-SNAPSHOT-sqoop-hook.tar.gz -C /opt/service/atlas/apache-atlas-2.2.0-SNAPSHOT
4.2.5 压缩配置文件到 Jar
cd $ATLAS_HOME/conf/
zip -u $ATLAS_HOME/apache-atlas-sqoop-hook-2.2.0-SNAPSHOT/hook/sqoop/atlas-plugin-classloader-2.2.0-SNAPSHOT.jar atlas-application.properties
4.2.6 软连接 Sqoop hook 文件
ln -s /opt/service/atlas/apache-atlas-2.2.0-SNAPSHOT/apache-atlas-sqoop-hook-2.2.0-SNAPSHOT/hook/sqoop/atlas-plugin-classloader-2.2.0-SNAPSHOT.jar /usr/local/service/sqoop/lib/atlas-plugin-classloader-2.2.0-SNAPSHOT.jar
ln -s /opt/service/atlas/apache-atlas-2.2.0-SNAPSHOT/apache-atlas-sqoop-hook-2.2.0-SNAPSHOT/hook/sqoop/sqoop-bridge-shim-2.2.0-SNAPSHOT.jar /usr/local/service/sqoop/lib/atlas-sqoop-bridge-shim-2.2.0-SNAPSHOT.jar
ln -s /opt/service/atlas/apache-atlas-2.2.0-SNAPSHOT/apache-atlas-sqoop-hook-2.2.0-SNAPSHOT/hook/sqoop/atlas-sqoop-plugin-impl /usr/local/service/sqoop/lib/atlas-sqoop-plugin-impl
4.2.7 修改sqoop-site.xml,配置Sqoop Hook
sqoop.job.data.publish.class
org.apache.atlas.sqoop.hook.SqoopHook
