
Pandas中的get_dummy()函数案例实战分享
回复“资源”即可获赠Python学习资料
大家好,我是皮皮。
一、前言
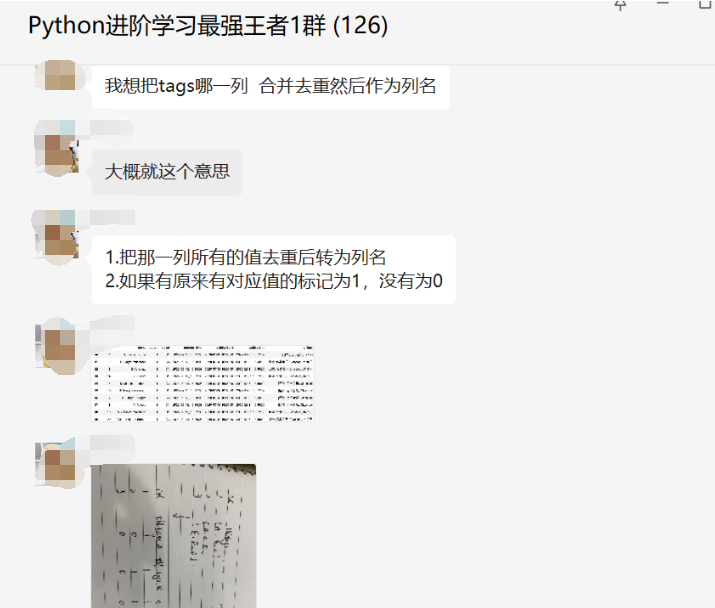
前几天在Python最强王者交流群【WYM】问了一个Pandas处理的问题,提问截图如下:
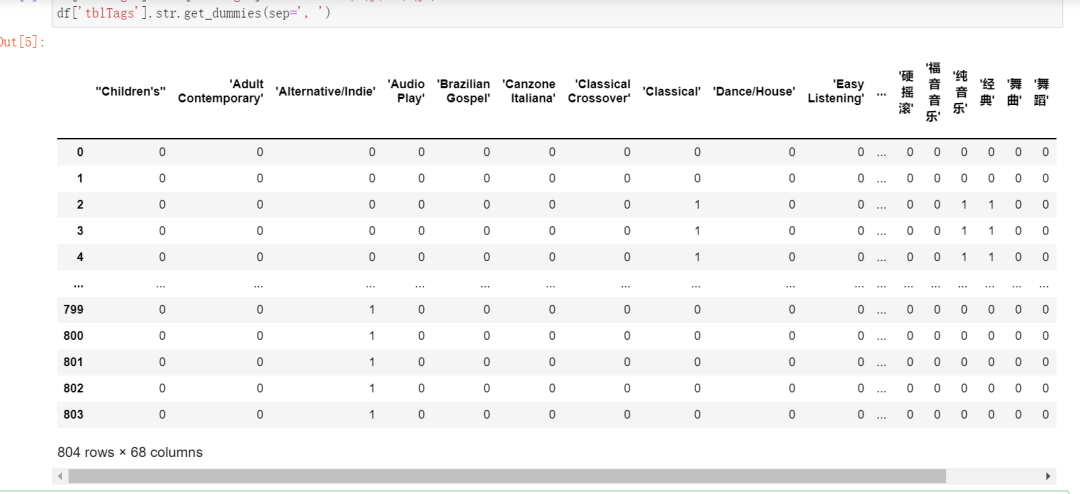
数据截图如下:
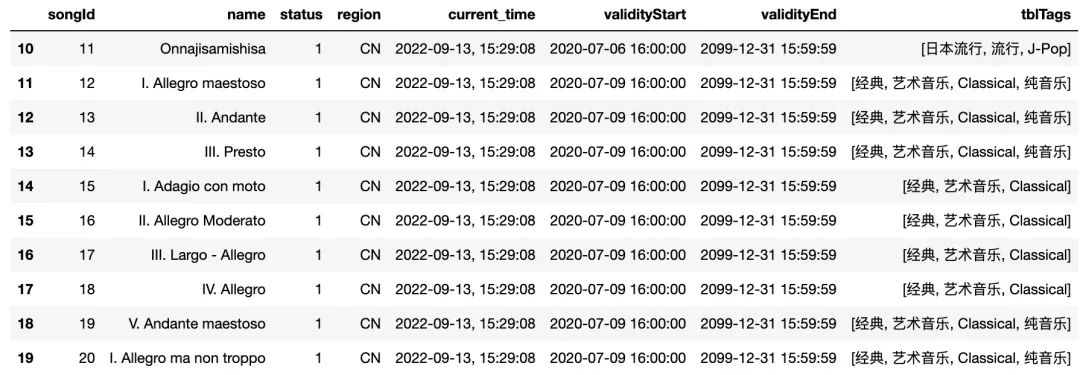

可能一开始理解起来还是有点困难的,需要多读一两遍才可以体会到那个意思。
二、实现过程
这里【郑煜哲·Xiaopang】给了一个思路,如下所示:
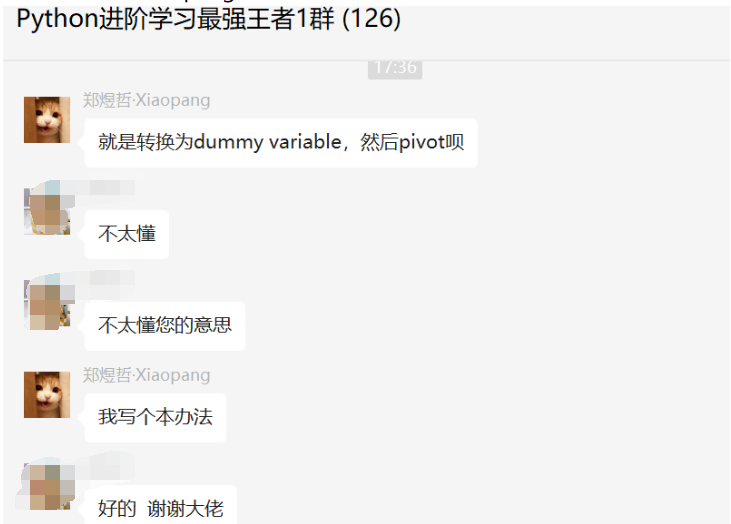
代码如下:
import pandas as pd
def my_func(x):
res = pd.Series(0, columns=labels)
if "x" in labels:
res["x"] = 1
elif "y" in labels:
res["y"] = 1
.....
return x.append(res)
df.apply(my_func, axis=0)
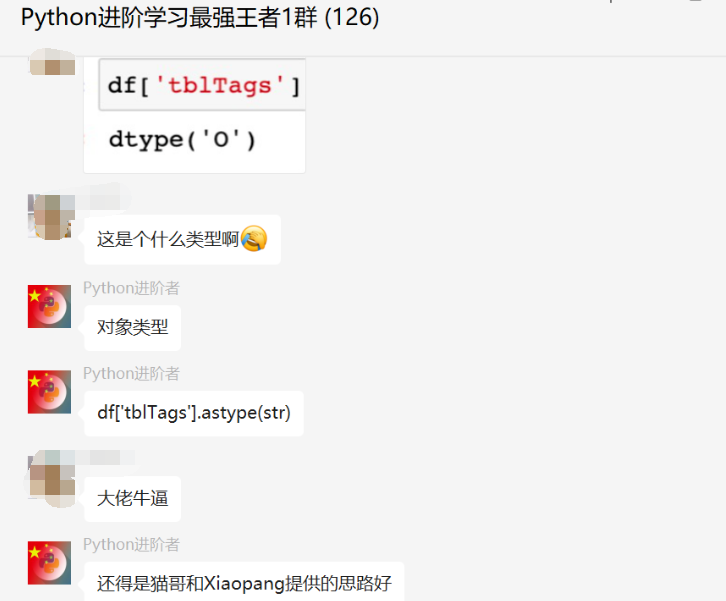
思路是没问题的,只不过实现起来还是没那么顺利。后来【猫药师Kelly】给了一个答案,如下所示:
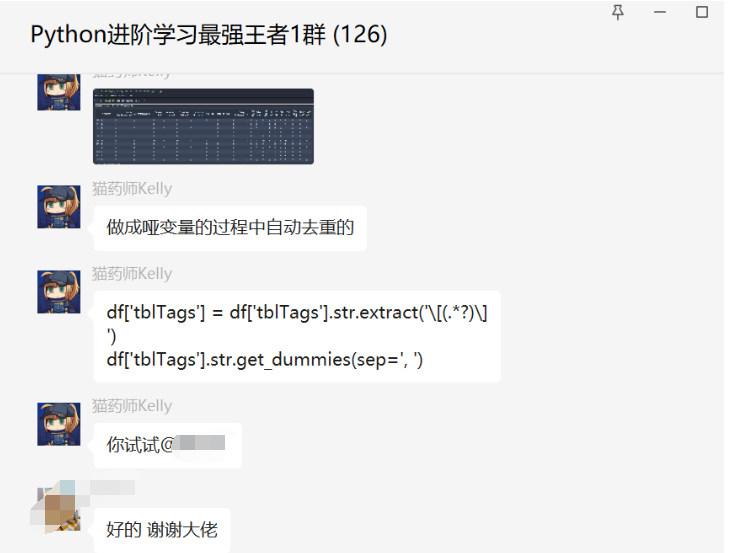
代码如下:
df['tblTags'] = df['tblTags'].str.extract('\[(.*?)\]')
df['tblTags'].str.get_dummies(sep=', ')
顺利地解决了粉丝的问题。
不过他自己的原始数据需要再处理下,不然的话,会报错。
如果DataFrame的某一列中含有k个不同的值,则可以派生出一个k列矩阵或DataFrame(其值全为1和0)。pandas有一个get_dummies()函数可以实现该功能。
他后面还咨询了另外一个问题。
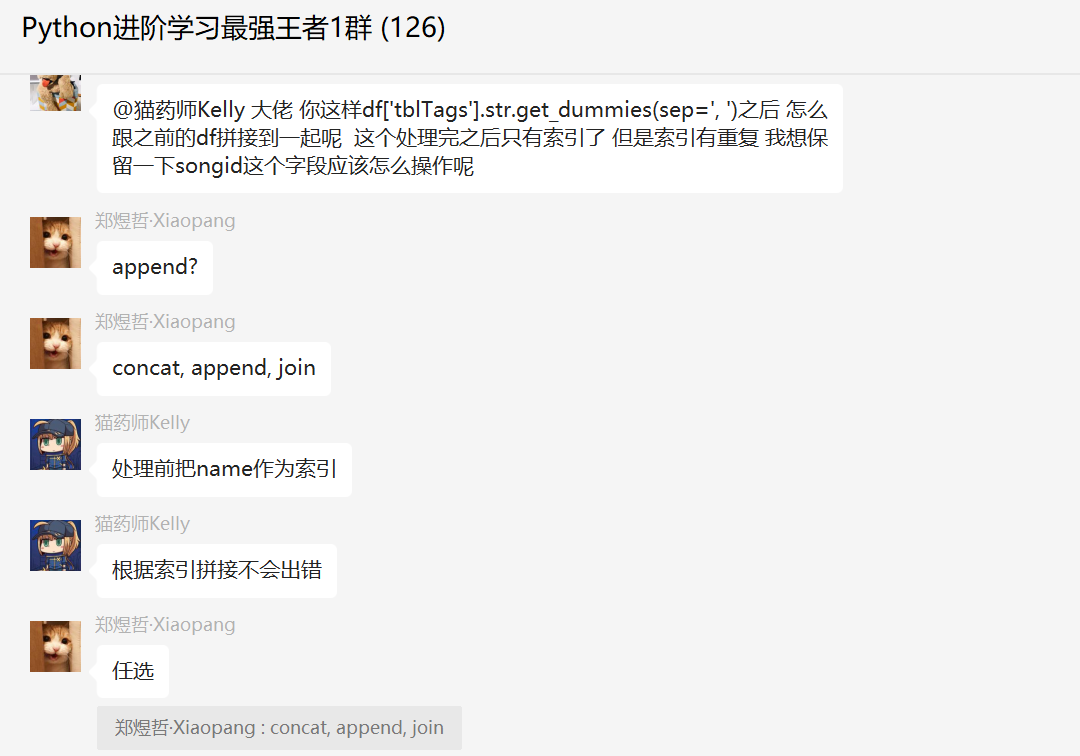
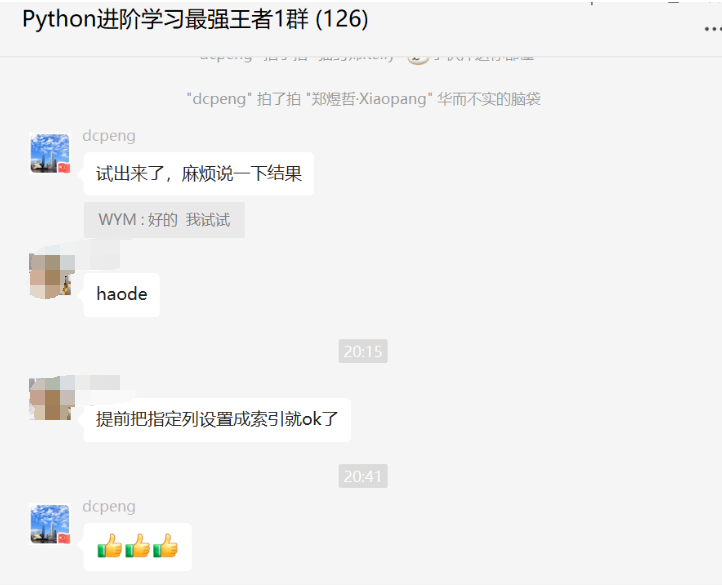
也得到就完美地解答。
三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Python基础的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【WYM】提问,感谢【郑煜哲·Xiaopang】、【猫药师Kelly】给出的思路和代码解析,感谢【dcpeng】等人参与学习交流。
大家在学习过程中如果有遇到问题,欢迎随时联系我解决(我的微信:pdcfighting),应粉丝要求,我创建了一些高质量的Python付费学习交流群,欢迎大家加入我的Python学习交流群!

有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
评论