
【CTR预估】互联网大厂CTR预估前沿进展
文 | Ruhjkg@知乎
编 | 小鹿鹿lulu
 前言
前言
CTR(click through rate)预估模型是广告推荐领域的核心问题。早期主要是使用LR(线性回归)+人工特征工程的机器学习方法,但是存在人工组合特征工程成本较高,不同任务难以复用的问题。后来随着FM因子分解机的出现,提出了使用二阶特征自动交叉的方法,缓解了人工组合特征的难题。之后2014年Facebook使用GBDT+LR方案,提出了树模型构建组合特征的思路。2015年后,由于深度学习的流行,业界主流的CTR模型从采用经典DNN模型演变到结合浅层的Wide&deep模型,再到结合二阶特征交叉的DeepFM模型,深度学习开始全面应用在CTR预估问题上。
时间进入2020年,CTR预估模型又有了很多新的发展,比如使用新的特征交互方式,CTR模型统一的benchmark,用户行为序列建模和用户的多兴趣建模,多任务学习,CTR模型知识蒸馏,CTR模型的增量训练,CTR模型debias,多模态学习与对抗,跨域迁移CTR建模,隐式反馈数据建模,NAS在CTR上应用,等等。接下来,本文会对2020年CTR模型的最新进展进行全面的梳理和解析。
高阶特征交互
自从Transformer 提出以来,Attention逐渐成为CTR模型里高阶特征交互的重要方式。18年AutoInt提出将Multi-head self-attention 应用在CTR模型里,它在增强模型的可解释性的同时并且具备高阶特征交叉的能力,19年微博团队提出的FiBiNet,这篇文章使用Squeeze-Excitation network (Senet) 结构学习动态特征的重要性以及使用用双线性函数来更好的建模交叉特征。以及阿里的BST直接使用transformer对用户行为序列建模。
AFN
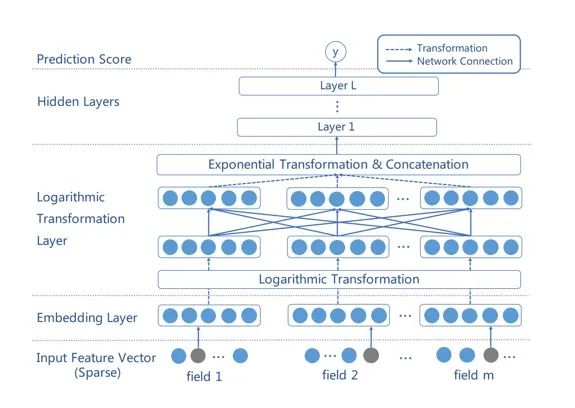
Adaptive Factorization Networks是AAAI20的工作, 由于之前的CTR模型为了增强模型的预测效果利用了二阶特征交互,甚至高阶特征交互。然而这些高阶特征交互往往带来昂贵的计算量导致模型陷入局部最优解,同时构造出来交叉特征有些相关性比较小对于模型来说相当于引进噪声影响模型性能。因此本文提出了AFN(自适应因子网络)学习特征组合的阶数,可以自适应调整不同阶的特征组合。
论文题目:
Adaptive Factorization Network: Learning Adaptive-Order Feature Interactions
论文地址:
https://arxiv.org/abs/1909.03276
InterHAt
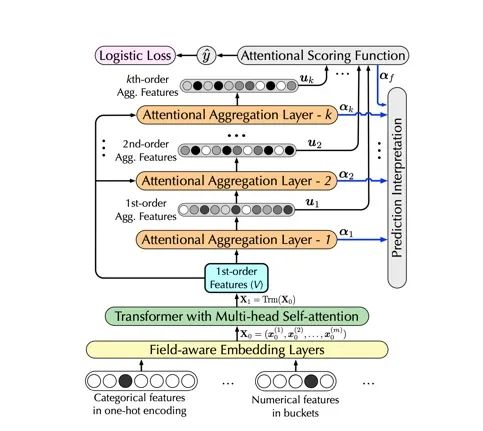
InterHAt是在WSDM20上发表的工作,文中指出现存的CTR模型有三个主要缺点,第一缺乏可解释性,第二高阶特征交叉效率比较低,第三不同的语义子空间特征交互的多义性容易被忽视。因此本文提出使用带有多头注意力机制的transformer用于特征表示学习,再利用分层注意力策略来预测CTR并且同时提供结果的可解释性。InterHAt通过高效的注意力聚集策略捕获高阶特征交互。
论文题目:
Interpretable Click-through Rate Prediction through Hierarchical Attention
论文地址:
https://dl.acm.org/doi/pdf/10.1145/3336191.3371785
LorentzFM
LorentzFM是AAAI20的工作。这篇文章提出的动机:由于之前CTR模型为了学习到复杂的特征交互需要大量的训练参数从而导致内存使用过高以及计算效率低下,因此提出了一种名为LorentzFM的新模型交互,它利用了双曲空间中两个特征之间距离是否违背三角不等式来构造特征交互,同时双曲三角形特殊的几何特性使得学习不需要所有的顶层深度学习层,大大减少参数数量(20%~80%)。
论文题目:
Learning Feature Interactions with Lorentzian Factorization Machine
论文地址:
https://arxiv.org/pdf/1911.09821.pdf
CAN
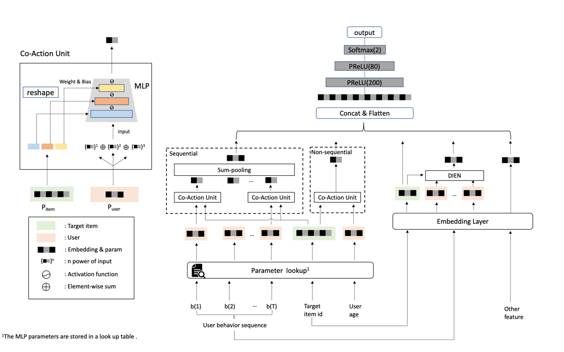
CAN这项工作是阿里定向组今年11月发表在arxivs上的,主要以一种新的方式重新思考高阶特征交互。本文首先提出特征协同的概念,这是指特征对最终预测的集体影响。然后使用二维笛卡尔积的方式来对item ID做特征协同建模会带来参数量的急剧上升,为了解决这个问题,本文提出了Co-Action Net 使用模型化的方案建模Co-action。其具体的建模的方案是:把Co-action 希望建模的两个ID, 一端信息作为输入,另一端信息作为MLP的参数,用MLP输出来表达co-action信息。
论文题目:
CAN: Revisiting Feature Co-Action for Click-Through Rate Prediction
论文地址:
https://arxiv.org/pdf/2011.05625.pdf
KFAtt-freq
这篇是京东广告搜索组NIPS 20 的工作。在电商场景中,用户经常出现历史行为中没有表现过的新的兴趣,以及对不同品类商品行为频次严重不均衡,针对这两个问题,这篇文章提出一套基于卡尔曼滤波的attention的算法用于对新用户行为建模。主要是为了克服用户行为中频次差异巨大的问题。
论文题目:
Kalman Filtering Attention for User Behavior Modeling in CTR Prediction
论文地址:
https://arxiv.org/pdf/2010.00985.pdf
NON
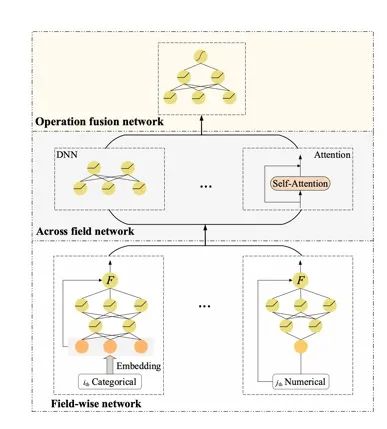
这篇论文是第四范式在SIGIR20上发表的文章,文章指出大部分基于神经网络和FM的CTR模型虽然可以融合不同的特征embedding直接并线性组合,但是没有考虑到域内信息,而且不同数据泛化新较差。因此提出network on network(NON)解决这个问题。
论文题目:
Network On Network for Tabular Data Classification in Real-world Applications
论文地址:
https://arxiv.org/abs/2005.10114
CTR模型benchmark
一直以来,大多数CTR预测任务缺乏一个标准的benchmark和统一的评价标准,因此在这些研究中,这导致了不可复现甚至不一样的实验结果。而今年9月华为诺亚提出一个可再现的开放benchmark FuxiCTR , 文章实验结果表明许多做高阶特征交叉的CTR模型的差异并没有论文当中提到地那么大。
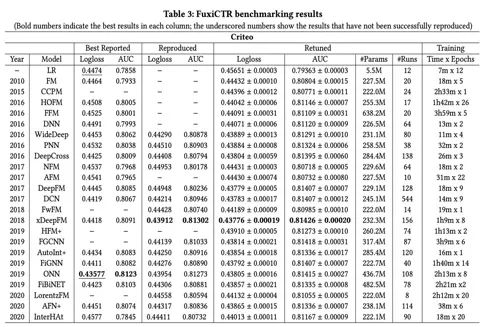
论文题目:
FuxiCTR: An Open Benchmark for Click-Through Rate Prediction
论文地址:
https://arxiv.org/abs/2009.05794
用户行为序列建模用户兴趣
关于用户行为序列建模,最开始是youtube那篇文章直接把用户观看过得视频序列做mean pooling 作为用户历史兴趣的表达,而在DIN中,将attention的思想引入到行为序列建模中,将target item 和行为序列中的item做一个attention,得到一个weight, 然后进行加权求和来表征用户的兴趣。在之后DIEN中使用GRU对用户兴趣进行抽取和使用AUGRU来表示用户兴趣的演化过程。但是RNN方式对用户行为序列进行串行计算,耗时相对还是比较高,后来阿里BST文章使用transformer来建模用户的行为序列。更进一步,通过观察用户行为,发现用户在每个会话中的行为是相近的,而在不同会话中差别是很大的,考虑这种跟Session相结合的用户行为序列,阿里提出一篇DSIN工作。
DHAN
这篇工作是阿里SIGIR20的工作,文章指出用户兴趣往往遵从一种层级的模式,从higher-level的属性(如品类,价格区间,品牌)到具体lower-level属性(如item),而之前关于用户兴趣抽取的模型如DIN忽视了这种层次结构用户兴趣建模。
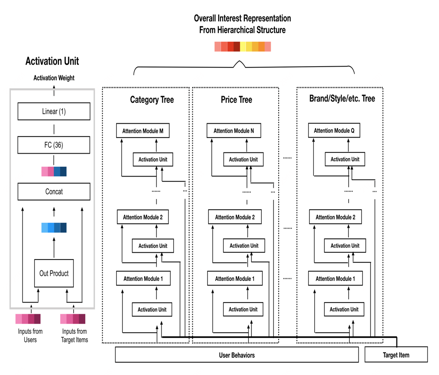
论文题目:
Deep Interest with Hierarchical Attention Network for Click-Through Rate Prediction
论文地址:
https://arxiv.org/pdf/2005.12981.pd
SIM
这篇是阿里今年6月放出来对于用户行为序列建模的研究。为了解决对长用户行为建模线上耗时大的问题,阿里这篇SIM通过两阶段的方式,来对用户终身行为序列进行建模,第一个阶段,通过GSU模块,从用户行为序列中找到K个与目标物品最为相关的序列集合,第二个阶段对前一个阶段得到的较短行为序列通过exact search unit 模块来进行精准建模用户兴趣。
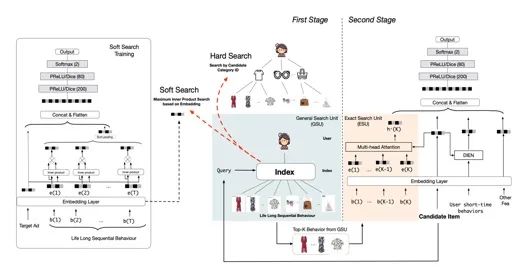
论文题目:
Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction
论文地址:
https://arxiv.org/abs/2006.05639
UBR4CTR
这篇是SIGIR20的工作,从用户的行为序列当中捕获用户的兴趣对于CTR模型来说是很有必要的,但是把长行为序列喂给模型对于在线推理面临着高响应延迟的问题,同时用户的长行为序列也存在着很多噪声。而当前工业界的解决方案是对用户长行为序列进行截断只把用户最近的行为序列喂给模型训练,这会导致模型学习不到用户周期性的兴趣以及行为序列里的长期依赖性。为了解决这个问题,本文提出User behavior Retrieval for CTR(UBR4CTR)框架从数据角度从整个用户历史行为记录搜索最相关和最合适的行为序列。
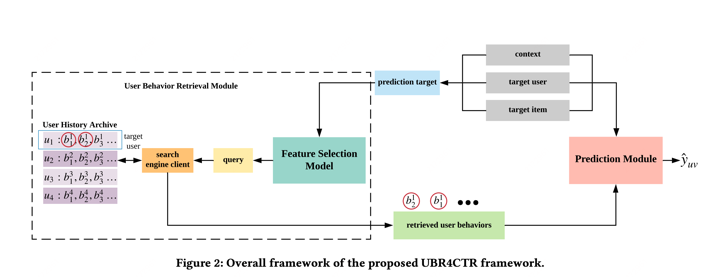
论文题目:
User Behavior Retrieval for Click-Through Rate Prediction
论文地址:
https://arxiv.org/pdf/2005.14171.pdf
DTS
阿里优酷团队在AAAI20的工作, 文中指出用户的兴趣会随着时间而动态变化,因此有必要考虑CTR模型当中的连续时间信息来跟踪用户的兴趣趋势。在这篇paper中,DTS模型通过在一个常微分方程(ODE)中引入时间信息,使用神经网络根据用户历史行为连续建模用户的兴趣演变。
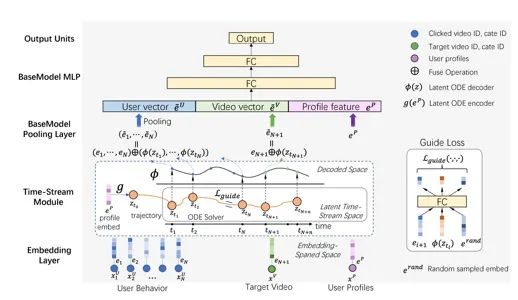
论文题目:
Deep Time-Stream Framework for Click-through Rate Prediction by Tracking Interest Evolution
论文地址:
https://arxiv.org/abs/2001.03025
DMIN
本文是阿里发表在CIKM20的工作。从用户行为序列中抽取用户的兴趣的工作很多,本文指出用户在一个时间点的兴趣是多样的,而潜在的主要兴趣是通过用户行为表示。这篇文章提出使用DMIN模型来捕获用户潜在的多兴趣,DMIN网络主要由两部分组成,Behavior refiner layer 使用multi-head attention 对用户历史行为提炼,第二部分使用Multi-interest extractor layer 实现用户多兴趣的抽取。
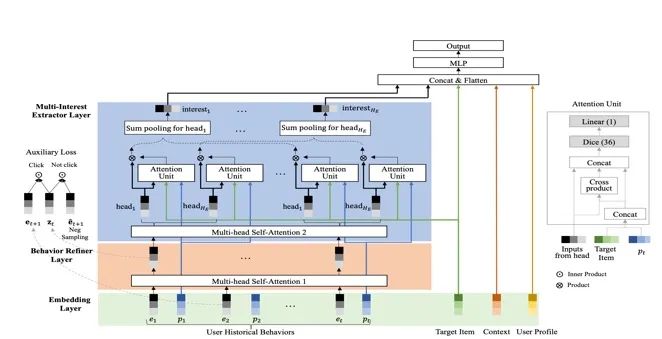
论文题目:
Deep Multi-Interest Network for Click-through Rate Prediction
论文地址:
https://dl.acm.org/doi/pdf/10.1145/3340531.3412092
TIEN
本篇论文是阿里发表在CIKM20的工作。之前用来建模用户兴趣的CTR模型大都是从用户行为序列出发,但是缺乏对候选物品更丰富的建模。比如电商开展的促销活动会让某些热销商品成为用户的短期新兴趣。在上述场景下,仅仅使用用户行为序列通常无法预测用户产生的新兴趣,不仅因为用户行为当中有过时的兴趣,同时预测用户新的兴趣严重依赖于物品的演化过程。本文提出基于时间感知的深度物品演化网络(Deep Time-Aware item evolution network)来解决上述问题。
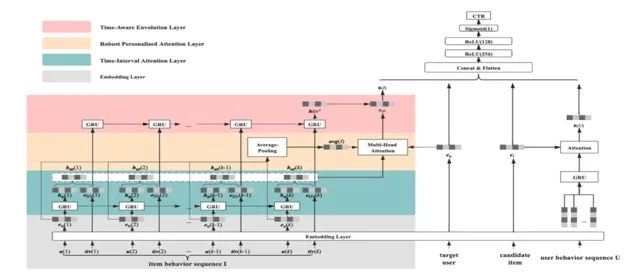
论文题目:
Deep Time-Aware Item Evolution Network for Click-Through Rate Prediction
论文地址:
https://dl.acm.org/doi/abs/10.1145/3340531.3411952
基于position-bias 建模
PAL
本文是华为RecSys19的文章。大部分的CTR模型都是基于用户反馈进行数据收集训练的,往往这些收集到的训练数据存在位置偏差,准确来说对于不同的广告展示位置,点击率是不同的,展示位置越靠前,点击率越高,因此在建模的过程中有必要对这一部分位置信息进行建模。PAL(position-bias aware learning framework) 在分析将位置信息作为特征输入不足后,提出一种将位置作为模块单独预测的方法。
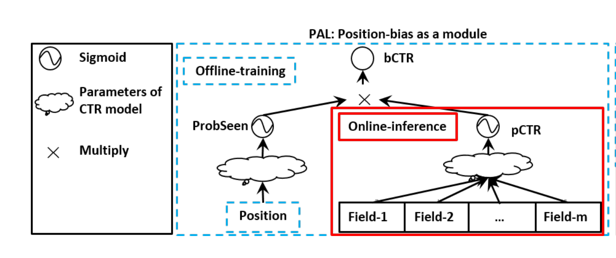
论文题目:
PAL: a position-bias aware learning framework for CTR prediction in live recommender systems
论文地址:
https://dl.acm.org/doi/10.1145/3298689.3347033
多任务学习(MTL)
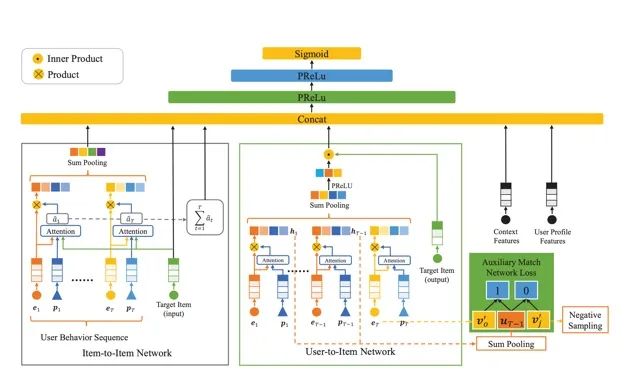
DMR
DMR(Deep Match to Rank)是阿里在AAAI20的工作,主要是将基于协同过滤思想的matching融入ranking阶段的CTR预估模型,以此提高了模型的个性化能力,这属于用多任务的想法来做CTR 预估一种。
论文题目:
Deep Match to Rank Model for Personalized Click-Through Rate Prediction
论文地址:
https://ojs.aaai.org//index.php/AAAI/article/view/5346
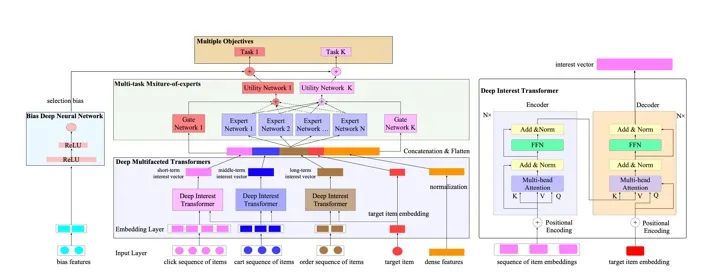
DMT
这篇是京东和百度发表在CIKM20的论文。通常现有的推荐算法通过优化单个任务来对商品进行排名,例如基于用户的点击行为,但是他们很少同时关注用户的多种行为建模或者共同优化。本文认为基于用户多种类型的行为来建模用户不同兴趣并且执行多任务学习可以同时优化多个目标。因此提出DMT (Deep Multifaceted transformers)对用户的多种行为建模,它利用Multi-gate mixture of experts 去优化多个目标,此外还利用unbiased learning去减小selection bias。
论文题目:
Deep Multifaceted Transformers for Multi-objective Ranking in Large-Scale E-commerce Recommender Systems
论文地址:
https://dl.acm.org/doi/abs/10.1145/3340531.3412697
知识蒸馏和特征蒸馏
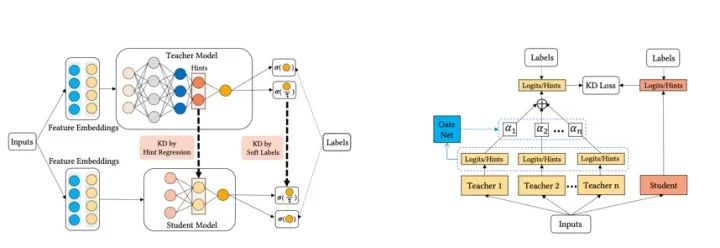
Ensembled CTR-KD
本篇论文是华为发表在CIKM20的工作。文中指出当前对于CTR预估的研究都在使用更加复杂的网络结构补捉特征之间的交叉信息,但是这些复杂模型耗时增加,难以应用在线上服务,本文提出使用知识蒸馏的策略轻量化CTR模型,同时为了提高模型性能,提出一种门机制用来ensemble CTR模型。
论文题目:
Ensembled CTR Prediction via Knowledge Distillation
论文地址:
https://dl.acm.org/doi/pdf/10.1145/3340531.3412704
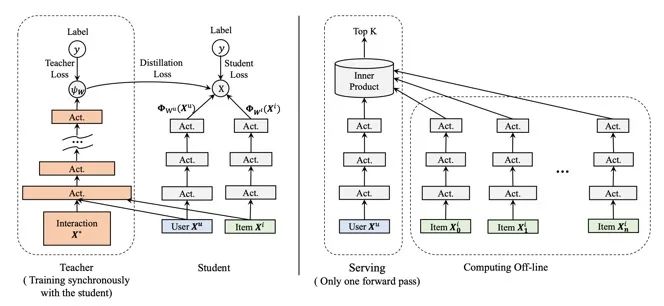
PFD
这篇是阿里KDD20的工作 。工业级推荐系统中,特征输入信号的强弱决定了模型和算法的上限,在实际应用中为了维护离线训练和在线预估的一致性,使得一些信号比较强的特征被排除在外,比如用户在商详页的停留时长。这种区分度高但是只能离线获取的特征我们称为优势特征。为了更加优雅地利用优势特征,本文提出优势特征蒸馏(Privileged feature Distillation)来解决这个问题。
论文题目:
Privileged Features Distillation at Taobao Recommendations
论文地址:
https://arxiv.org/abs/1907.05171%3Fcontext%3Dcs.IR
跨域迁移
MiNet
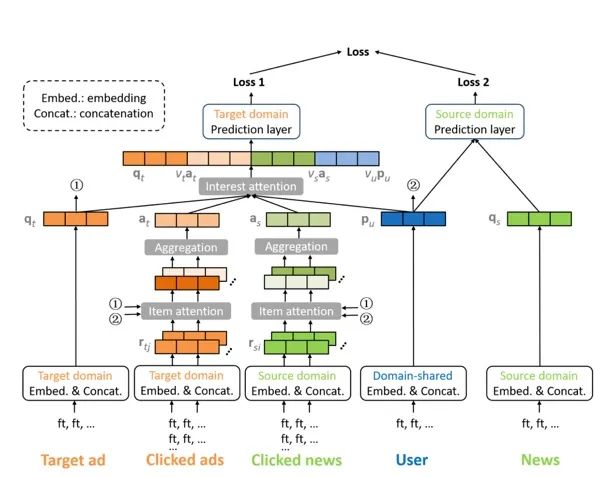
这篇工作是阿里CIKM20的工作,文中指出目前的CTR模型往往都是在单域上进行的,比如在广告点击率预测是,仅仅使用广告数据。但是在信息流推荐场景下,自然结果和广告是一起展示的,尽管内容相差较大,但用户在自然结果的浏览行为也会有助于广告预测点击。本文基于UC头条的应用场景,将新闻feed流作为源域,广告作为目标域,通过使用跨域数据来提高广告上的点击率预估效果。MiNet 采用跨域预估的主要优势主要是能够对冷启动起到一定的帮组。
论文题目:
MiNet: Mixed Interest Network for Cross-Domain Click-Through Rate Prediction
论文地址:
https://arxiv.org/abs/2008.02974
增量训练
IncCTR
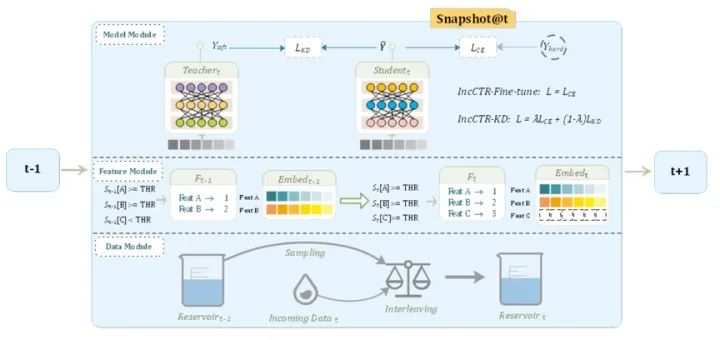
本篇是华为诺亚实验室今年9月份发表的论文。深度CTR模型需要大量的数据进行训练,同时需要不断的更新适应最新的数据分布。如果模型没有及时更新,则可能带来线上效果的衰减。为了保证线上模型的有效性,通常需要对模型进行天级别/小时级别的更新。模型的天级别更新通常使用规定时间窗口的数据对模型进行重新训练,这种做法耗时比价高,更新不及时,因此本文提出一种增量训练的方法。
论文题目:
A Practical Incremental Method to Train Deep CTR Models
论文地址:
https://arxiv.org/abs/2009.02147
多模态对抗训练
MARN
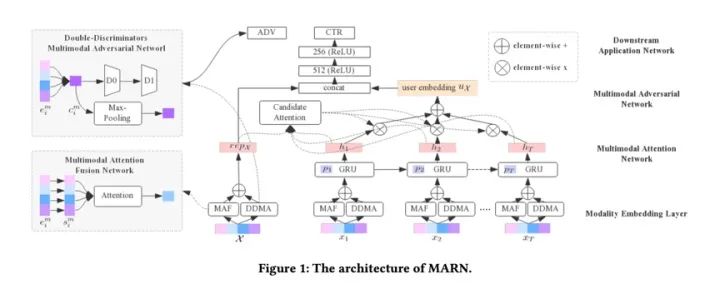
这篇是阿里发表在WWW20的工作。由于电商场景下包含多种异构模态的数据信息,此前的CTR模型比较少地研究从多模态数据里学习到一个好的item表示。它们通常做法仅仅只是把不同模态的特征concat 起来,每种模态赋予相同的权重,或者动态学习不同模态的权重。然而跨多种模态之间往往存在冗余信息,因此动态模态权重学习的方法仍然不能反映不同模态之间的重要性。本文提出一种多模态对抗表征网络(MARN)用于CTR预测任务当中。首先通过多模态注意力网络计算不同模态的权重,然后多模态对抗网络采取双判别策略学习模态不变性。最后结合两部分表征来作为多模态物品的表示。
论文题目:
Adversarial Multimodal Representation Learning for Click-Through Rate Prediction
论文地址:
https://arxiv.org/pdf/2003.07162.pdf
CSCNN
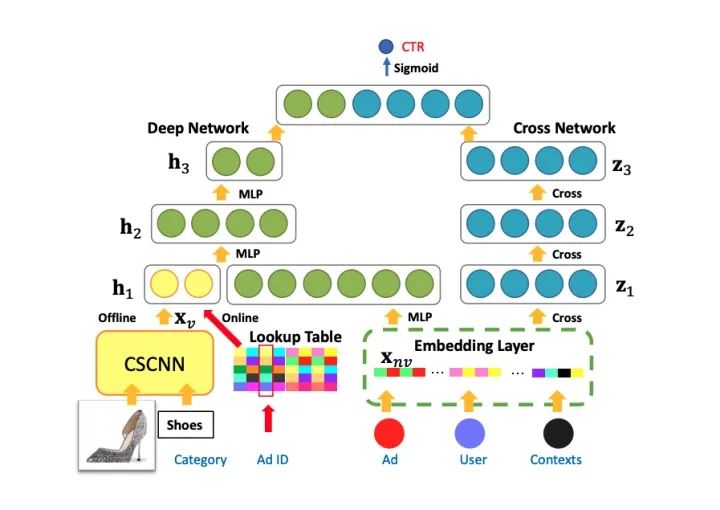
京东广告搜索组KDD20的工作。本文主要是将视觉信息融入CTR模型提高用户点击体验。现有的算法通常使用CNN提取视觉特征,然后对最终预测的CTR进行视觉和非视觉做late fusion 。本文主要贡献在于引入轻量级attention模块将类别信息输入CNN里用于提取视觉先验信息,第二 在线服务和非终端系统的低延迟。
论文题目:
Category-Specific CNN for Visual-aware CTR Prediction at JD.com
论文地址:
https://arxiv.org/pdf/2006.10337.pdf
门机制
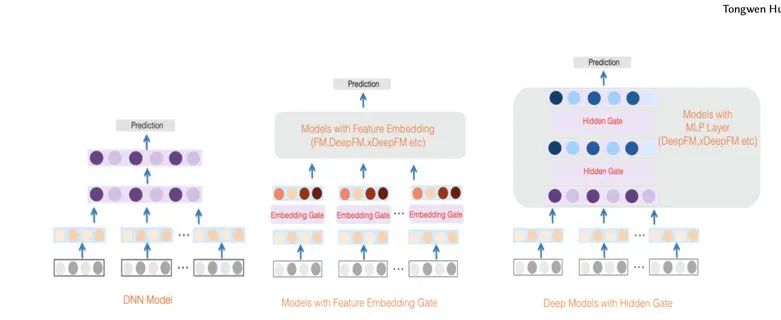
GateNet
本文是微博机器学习团队今年7月份的工作。在深度学习模型中,大都包括embedding layer和MLP hidden layer, 门机制在CV和NLP领域有广泛的应用。一些实验证明了门机制可以提升非凸神经网络的可训练性,本文提出GateNet探讨如何将门机制应用在深度学习CTR模型里。
论文题目:
GateNet:Gating-Enhanced Deep Network for Click-Through Rate Prediction
论文地址:
https://arxiv.org/pdf/2007.03519.pdf
隐式反馈数据建模
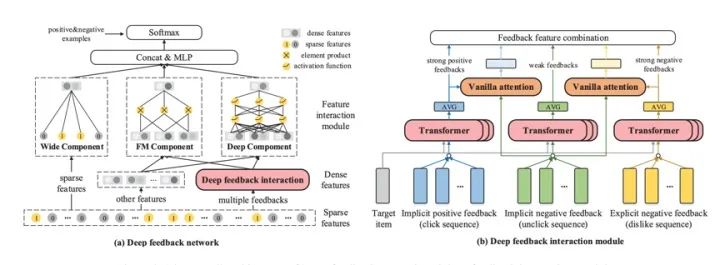
DFN
Deep Feedback network for Recommendation 这篇是微信团队在IJCAI20的工作。主要应用场景是微信看一看,在推荐系统中,我们可以用到的数据可以分为两类,即显式反馈数据和隐式反馈数据,之前大部分应用于推荐系统的深度学习模型往往是隐式正反馈(曝光点击数据),但隐式反馈往往不能代表用户的真正新区。因此本文提出充分利用显式/隐式以及正/负反馈,建模用户无偏的兴趣偏好。
论文题目:
Feedback Loop and Bias Amplification in Recommender Systems
论文地址:
https://arxiv.org/pdf/2007.13019.pdf
NAS 在CTR模型当中应用
facebook KDD20 的文章
Towards Automated Neural Interaction Discovery for Click-Through Rate Prediction
(https://arxiv.org/pdf/2007.06434.pdf)
华为诺亚 KDD20 的文章
AutoFIS: Automatic Feature Interaction Selection in Factorization Models for Click-Through Rate Prediction
(https://arxiv.org/abs/2003.11235)
往期精彩回顾
本站知识星球“黄博的机器学习圈子”(92416895)
本站qq群704220115。
加入微信群请扫码: