
理解关联规则算法
一、基础概念
1、算法概述
2、应用场景
3、几个概念

01)支持度


02)置信度



03)提升度
04)频繁项集
如果一个项集是 非频繁项集,那么它的所有超集也是非频繁项集
{Battery} is infrequent → {Milk, Battery} is infrequent
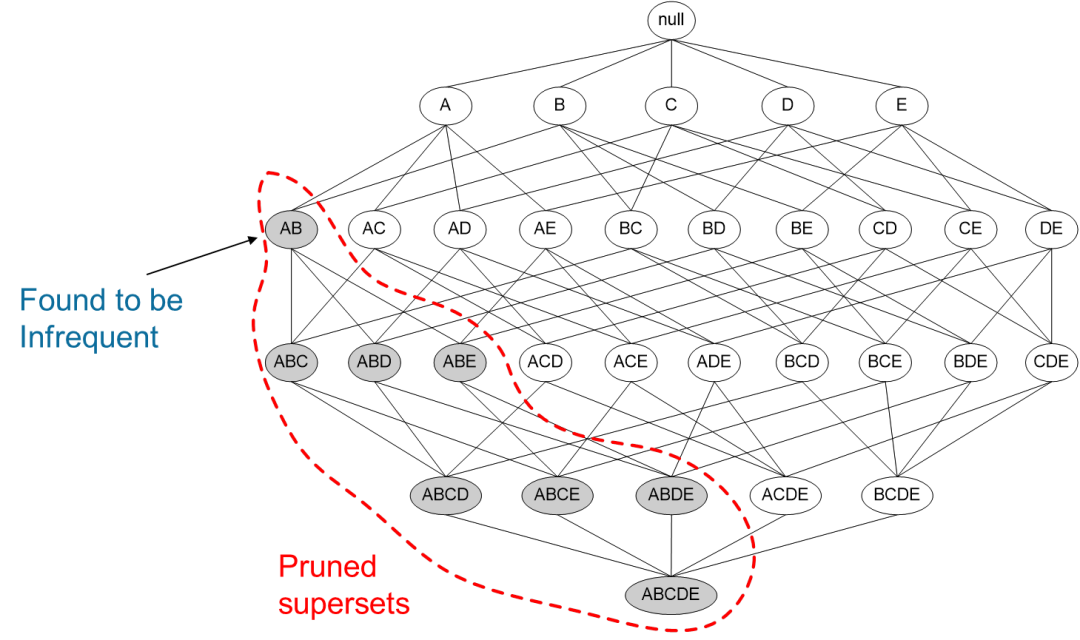
如图所示,我们发现{A,B}这个项集是非频繁的,那么{A,B}这个项集的超集,{A,B,C},{A,B,D}等等也都是非频繁的,这些就都可以忽略不去计算。
运用Apriori算法的思想,我们就能去掉很多非频繁的项集,大大简化计算量。
二、算法介绍
这里用的是Python举例,用的包是apriori,当然R语言等其他语言,也有对应的算法包,原来都是一样的。
#包安装pip install efficient-apriori#加载包from efficient_apriori import apriori# 构造数据集data = [('牛奶','面包','尿不湿','啤酒','榴莲'),('可乐','面包','尿不湿','啤酒','牛仔裤'),('牛奶','尿不湿','啤酒','鸡蛋','咖啡'),('面包','牛奶','尿不湿','啤酒','睡衣'),('面包','牛奶','尿不湿','可乐','鸡翅')]#挖掘频繁项集和频繁规则itemsets, rules = apriori(data, min_support=0.6, min_confidence=1)#频繁项集print(itemsets){1: {('啤酒',): 4, ('尿不湿',): 5, ('牛奶',): 4, ('面包',): 4}, 2: {('啤酒', '尿不湿'): 4, ('啤酒', '牛奶'): 3, ('啤酒', '面包'): 3, ('尿不湿', '牛奶'): 4, ('尿不湿', '面包'): 4, ('牛奶', '面包'): 3}, 3: {('啤酒', '尿不湿', '牛奶'): 3, ('啤酒', '尿不湿', '面包'): 3, ('尿不湿', '牛奶', '面包'): 3}}itemsets[1] #满足条件的一元组合{('啤酒',): 4, ('尿不湿',): 5, ('牛奶',): 4, ('面包',): 4}itemsets[2]#满足条件的二元组合{('啤酒', '尿不湿'): 4,('啤酒', '牛奶'): 3,('啤酒', '面包'): 3,('尿不湿', '牛奶'): 4,('尿不湿', '面包'): 4,('牛奶', '面包'): 3}itemsets[3]#满足条件的三元组合{('啤酒', '尿不湿', '牛奶'): 3, ('啤酒', '尿不湿', '面包'): 3, ('尿不湿', '牛奶', '面包'): 3}#频繁规则print(rules)[{啤酒} -> {尿不湿}, {牛奶} -> {尿不湿}, {面包} -> {尿不湿}, {啤酒, 牛奶} -> {尿不湿}, {啤酒, 面包} -> {尿不湿}, {牛奶, 面包} -> {尿不湿}]
三、挖掘实例
每个导演都有自己的偏好、比如周星驰有星女郎,张艺谋有谋女郎,且巩俐经常在张艺谋的电影里面出现,因此,每个导演对演员的选择都有一定的偏爱,我们以宁浩导演为例,分析下选择演员的一些偏好,没有找到公开的数据集,自己手动扒了一部分,大概如下,有些实在有点多,于是简化下进行分析

可以看到,我们一共扒了9部电影,计算的时候,支持度的时候,总数就是9.
#把电影数据转换成列表data = [['葛优','黄渤','范伟','邓超','沈腾','张占义','王宝强','徐峥','闫妮','马丽'],['黄渤','张译','韩昊霖','杜江','葛优','刘昊然','宋佳','王千源','任素汐','吴京'],['郭涛','刘桦','连晋','黄渤','徐峥','优恵','罗兰','王迅'],['黄渤','舒淇','王宝强','张艺兴','于和伟','王迅','李勤勤','李又麟','宁浩','管虎','梁静','徐峥','陈德森','张磊'],['黄渤','沈腾','汤姆·派福瑞','马修·莫里森','徐峥','于和伟','雷佳音','刘桦','邓飞','蔡明凯','王戈','凯特·纳尔逊','王砚伟','呲路'],['徐峥','黄渤','余男','多布杰','王双宝','巴多','杨新鸣','郭虹','陶虹','黄精一','赵虎','王辉'],['黄渤','戎祥','九孔','徐峥','王双宝','巴多','董立范','高捷','马少骅','王迅','刘刚','WorapojThuantanon','赵奔','李麒麟','姜志刚','王鹭','宁浩'],['黄渤','徐峥','袁泉','周冬雨','陶慧','岳小军','沈腾','张俪','马苏','刘美含','王砚辉','焦俊艳','郭涛'],['雷佳音','陶虹','程媛媛','山崎敬一','郭涛','范伟','孙淳','刘桦','黄渤','岳小军','傅亨','王文','杨新鸣']]
#算法应用itemsets, rules = apriori(data, min_support=0.5, min_confidence=1)print(itemsets){1: {('徐峥',): 7, ('黄渤',): 9}, 2: {('徐峥', '黄渤'): 7}}print(rules)[{徐峥} -> {黄渤}]
通过上述分析可以看出:
在宁浩的电影中,用的最多的是黄渤和徐峥,黄渤9次,支持度100%,徐峥7次,支持度78%,('徐峥', '黄渤') 同时出现7次,置信度为100%,看来有徐峥,必有黄渤,真是宁浩必请的黄金搭档。
当然,这个数据量比较小,基本上肉眼也能看出来,这里只是提供一个分析案例,巩固下基础知识,大规模的数据,人眼无法直接感知的时候,算法的挖掘与发现,就显得特别有意义了。
推荐阅读:
Python中的高效迭代库itertools,排列组合随便求
万字长文详解|Python库collections,让你击败99%的Pythoner
↓扫描关注本号↓
评论