
5 分钟掌握 Python 关联规则分析
1. 关联规则
1.1 基本概念
项集:item的集合,如集合{牛奶、麦片、糖}是一个3项集,可以认为是购买记录里物品的集合。 频繁项集:顾名思义就是频繁出现的item项的集合。如何定义频繁呢?用比例来判定,关联规则中采用支持度和置信度两个概念来计算比例值 支持度:共同出现的项在整体项中的比例。以购买记录为例子,购买记录100条,如果商品A和B同时出现50条购买记录(即同时购买A和B的记录有50),那边A和B这个2项集的支持度为50% 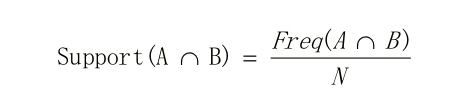
置信度:购买A后再购买B的条件概率,根据贝叶斯公式,可如下表示: 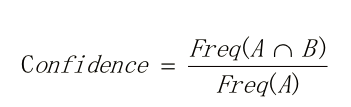
提升度:为了判断产生规则的实际价值,即使用规则后商品出现的次数是否高于商品单独出现的评率,提升度和衡量购买X对购买Y的概率的提升作用。如下公式可见,如果X和Y相互独立那么提升度为1,提升度越大,说明X->Y的关联性越强 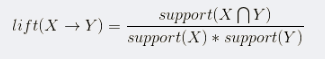
1.2 关联规则Apriori算法
发现频繁项集 找出关联规则
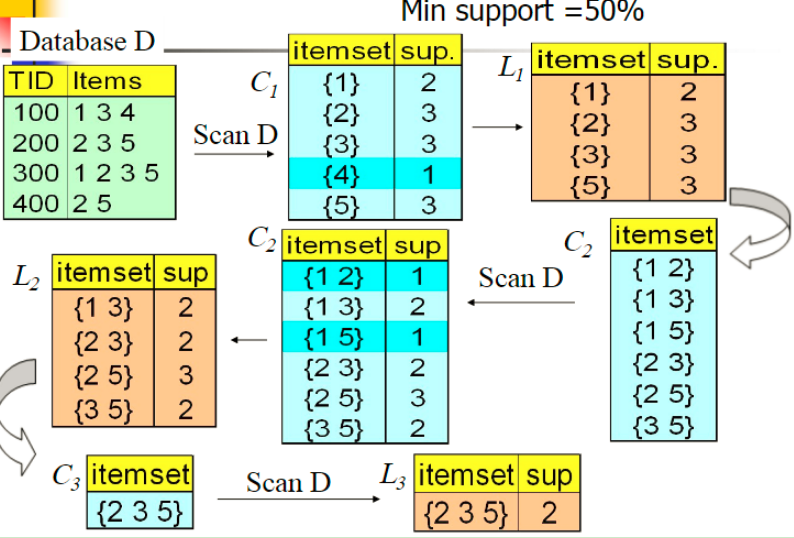
图中有4个记录,记录项有1,2,3,4,5若干 首先先找出1项集对应的支持度(C1),可以看出4的支持度低于最小支持阈值,先剪掉(L1)。 从1项集生成2项集,并计算支持度(C2),可以看出(1,5)(1,2)支持度低于最小支持阈值,先剪掉(L2) 从2项集生成3项集,(1,2,3)(1,2,5)(2,3,5)只有(2,3,5)满足要求 没有更多的项集了,就定制迭代
2. mlxtend实战关联规则
2.1 安装
pip install mlxtend
2.2 简单的例子
来看下数据集: import pandas as pd
item_list = [['牛奶','面包'],
['面包','尿布','啤酒','土豆'],
['牛奶','尿布','啤酒','可乐'],
['面包','牛奶','尿布','啤酒'],
['面包','牛奶','尿布','可乐']]
item_df = pd.DataFrame(item_list)数据格式处理,传入模型的数据需要满足bool值的格式 from mlxtend.preprocessing import TransactionEncode
te = TransactionEncoder()
df_tf = te.fit_transform(item_list)
df = pd.DataFrame(df_tf,columns=te.columns_)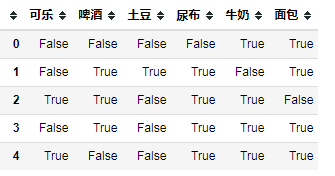
计算频繁项集 from mlxtend.frequent_patterns import apriori
# use_colnames=True表示使用元素名字,默认的False使用列名代表元素, 设置最小支持度min_support
frequent_itemsets = apriori(df, min_support=0.05, use_colnames=True)
frequent_itemsets.sort_values(by='support', ascending=False, inplace=True)
# 选择2频繁项集
print(frequent_itemsets[frequent_itemsets.itemsets.apply(lambda x: len(x)) == 2])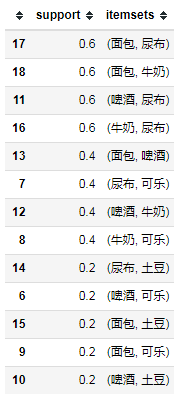
计算关联规则 from mlxtend.frequent_patterns import association_rules
# metric可以有很多的度量选项,返回的表列名都可以作为参数
association_rule = association_rules(frequent_itemsets,metric='confidence',min_threshold=0.9)
#关联规则可以提升度排序
association_rule.sort_values(by='lift',ascending=False,inplace=True)
association_rule
# 规则是:antecedents->consequents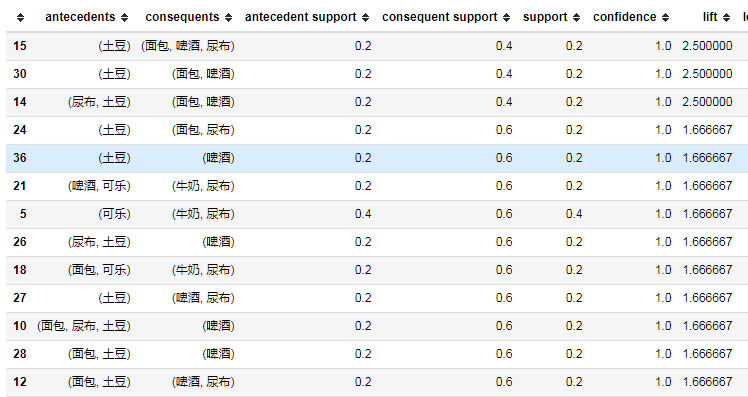
3. 总结
关联规则用于分析数据集各项之间的关联关系,想一想啤酒和尿布的故事 三个重要概念:支持度,置信度和提升度 Apriori通过迭代先找1项集,用支持度过滤项集,逐步找出所有k项集 用置信度或提升度来选择满足的要求的规则 mlxtend对数据要求转换成bool值才可用
作者简介:wedo实验君, 数据分析师;热爱生活,热爱写作
赞 赏 作 者

更多阅读
特别推荐

点击下方阅读原文加入社区会员
评论