
【NLP】Pyhon+讯飞开放平台:手把手带你写一个智能语音播报系统
微信扫码登陆讯飞开放平台:https://www.xfyun.cn/
完成个人认证。

在控制台创建应用,注意应用名称全库查重,很容易跟别人重复。

可查看到python调用需要用到的APPID,APISecret,APIKey等信息。

整个语音合成系统逻辑如下:

No BB,Show Code:
先安装需要的库,用来和讯飞的服务器建立连接、播放声音。

下载官方python3代码学习:

demo.pcm文件一定要放到你的代码目录下。
(一)首先调用需要的库:
import websocketimport datetimeimport hashlibimport base64import hmacimport jsonfrom urllib.parse import urlencodeimport sslfrom wsgiref.handlers import format_date_timefrom datetime import datetimefrom time import mktimeimport _thread as threadimport osimport waveimport tkinter as tkfrom tkinter import ttkimport timefrom playsound import playsoundimport sys
(二)设置一些系统参数和函数并用tkinter把交互界面写好
STATUS_FIRST_FRAME = 0 # 第一帧的标识STATUS_CONTINUE_FRAME = 1 # 中间帧标识STATUS_LAST_FRAME = 2 # 最后一帧的标识PCM_PATH = "./demo.pcm"class TtsPlay:def __init__(self):#初始化函数self.vcn = 'xiaoyan'self.APP_ID = '自行填入' # 请填上自己的appidself.API_KEY = '自行填入' # 请填上自己的appkeyself.SECRET_KEY = '自行填入' # 请填上自己的appsecretself.fname = ""self.root = tk.Tk() # 初始化窗口self.root.title("智能语音播报系统") # 窗口名称self.root.geometry("600x550") # 设置窗口大小self.root.resizable(0, 0) # 为了方便固定窗口大小self.tk_lb = tk.Label(self.root, text='请选择语音发音人') # 标签self.tk_text = tk.Text(self.root, width=77, height=30) # 多行文本框self.tk_cb_vcn = ttk.Combobox(self.root, width=12) # 下拉列表框#设置下拉列表框的内容self.tk_cb_vcn['values'] = ("甜美女声-小燕", "亲切男声-许久", "知性女声-小萍", "可爱童声-许小宝", "亲切女声-小婧")self.tk_cb_vcn.current(0) # 将当前选择状态置为0,也就是第一项self.tk_cb_vcn.bind("<>" , self.select_vcn)self.tk_tts_file = tk.Label(self.root, text='生成文件名')self.b1 = tk.Button(self.root, text='开始合成吧', width=10, height=1, command=self.xfyun_tts) # 按钮self.tk_play = tk.Button(self.root, text='直接播放吧', width=10, height=1, command=self.play_sound) # 按钮# 各个组件的位置self.tk_tts_file.place(x=30, y=500)self.b1.place(x=300, y=500)self.tk_play.place(x=400, y=500)self.tk_lb.place(x=30, y=30)self.tk_cb_vcn.place(x=154, y=30)self.tk_text.place(x=30, y=60)self.root.mainloop()def select_vcn(self, *args):#选择下拉框设置发音人if self.tk_cb_vcn.get() == '甜美女声-小燕':self.vcn = "xiaoyan"elif self.tk_cb_vcn.get() == '亲切男声-许久':self.vcn = "aisjiuxu"elif self.tk_cb_vcn.get() == '知性女声-小萍':self.vcn = "aisxping"elif self.tk_cb_vcn.get() == '可爱童声-许小宝':self.vcn = "aisbabyxu"elif self.tk_cb_vcn.get() == '亲切女声-小婧':self.vcn = "aisjinger"def xfyun_tts(self): # 进行语音合成tts_text = self.tk_text.get('0.0', 'end') # 获取文本内容# 前后的空格以及换行符tts_text = tts_text.strip('\r\n')tts_text = tts_text.strip('\n')tts_text = tts_text.strip(' ')if not tts_text:tk.messagebox.showinfo("提示", "请输入文本内容")returnfname = time.strftime("%Y%m%d%H%M%S", time.localtime())self.fname = os.path.dirname(sys.argv[0]) + "/" + fname + ".wav"self.tk_tts_file["text"] = self.fnametext2wav(self.APP_ID, self.SECRET_KEY, self.API_KEY, tts_text, self.vcn, self.fname)def play_sound(self):# 播放音频函数playsound(self.fname)
(三)利用官方例程把与讯飞开放平台的互动写好
class Ws_Param(object):# 初始化def __init__(self):self.tts_vcn = ""self.tts_business_args = ""self.tts_common_args = ""self.tts_text_data = ""self.APPID = ""self.APIKey = ""self.APISecret = ""def set_tts_params(self, text, vcn):self.tts_vcn = vcn# 业务参数(business),更多个性化参数可在官网查看self.tts_business_args = {"aue": "raw", "auf": "audio/L16;rate=16000", "vcn": self.tts_vcn, "tte": "utf8"}# 使用小语种须使用以下方式,此处的unicode指的是 utf16小端的编码方式,即"UTF-16LE"”# self.tts_text_data = {"status": 2, "text": str(base64.b64encode(self.Text.encode('utf-16')), "UTF8")}self.tts_text_data = {"status": 2, "text": str(base64.b64encode(text.encode('utf-8')), "UTF8")}def set_params(self, appid, api_seccret, api_key):if appid != "":self.APPID = appid# 公共参数(common)self.tts_common_args = {"app_id": self.APPID}if api_key != "":self.APIKey = api_keyif api_seccret != "":self.APISecret = api_seccret# 生成urldef create_url(self):url = 'wss://tts-api.xfyun.cn/v2/tts'# 生成RFC1123格式的时间戳now = datetime.now()date = format_date_time(mktime(now.timetuple()))# 拼接字符串signature_origin = "host: " + "ws-api.xfyun.cn" + "\n"signature_origin += "date: " + date + "\n"signature_origin += "GET " + "/v2/tts " + "HTTP/1.1"# 进行hmac-sha256进行加密signature_sha = hmac.new(self.APISecret.encode('utf-8'), signature_origin.encode('utf-8'),digestmod=hashlib.sha256).digest()signature_sha = base64.b64encode(signature_sha).decode(encoding='utf-8')authorization_origin = "api_key=\"%s\", algorithm=\"%s\", headers=\"%s\", signature=\"%s\"" % (self.APIKey, "hmac-sha256", "host date request-line", signature_sha)authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8')# 将请求的鉴权参数组合为字典v = {"authorization": authorization,"date": date,"host": "ws-api.xfyun.cn"}url = url + '?' + urlencode(v)return urldef on_message(ws, message):try:message = json.loads(message)code = message["code"]sid = message["sid"]audio = message["data"]["audio"]audio = base64.b64decode(audio)status = message["data"]["status"]print(code, sid, status)if status == 2:print("ws is closed")ws.close()if code != 0:err_msg = message["message"]print("sid:%s call error:%s code is:%s" % (sid, err_msg, code))else:with open(PCM_PATH, 'ab') as f:f.write(audio)except Exception as e:print("receive msg,but parse exception:", e)# 收到websocket错误的处理def on_error(ws, error):print("### error:", error)# 收到websocket关闭的处理def on_close(ws):print("### closed ###")# 收到websocket连接建立的处理def on_open(ws):def run(*args):d = {"common": wsParam.tts_common_args,"business": wsParam.tts_business_args,"data": wsParam.tts_text_data,}d = json.dumps(d)print("------>开始发送文本数据")ws.send(d)if os.path.exists(PCM_PATH):os.remove(PCM_PATH)thread.start_new_thread(run, ())def text2wav(appid, api_secret, api_key, text, vcn, fname):wsParam.set_params(appid, api_secret, api_key)wsParam.set_tts_params(text, vcn)websocket.enableTrace(False)ws_url = wsParam.create_url()ws = websocket.WebSocketApp(ws_url, on_message=on_message, on_error=on_error, on_close=on_close)ws.on_open = on_openws.run_forever(sslopt={"cert_reqs": ssl.CERT_NONE})pcm2wav(PCM_PATH, fname)def pcm2wav(fname, dstname):with open(fname, 'rb') as pcmfile:pcmdata = pcmfile.read()print(len(pcmdata))with wave.open(dstname, "wb") as wavfile:wavfile.setparams((1, 2, 16000, 0, 'NONE', 'NONE'))wavfile.writeframes(pcmdata)wsParam = Ws_Param()
(四)在main函数运行tkinter用户界面,或者直接上传text转换为wav文件
if __name__ == "__main__":a=TtsPlay()
跑起来吧,小宝贝儿:
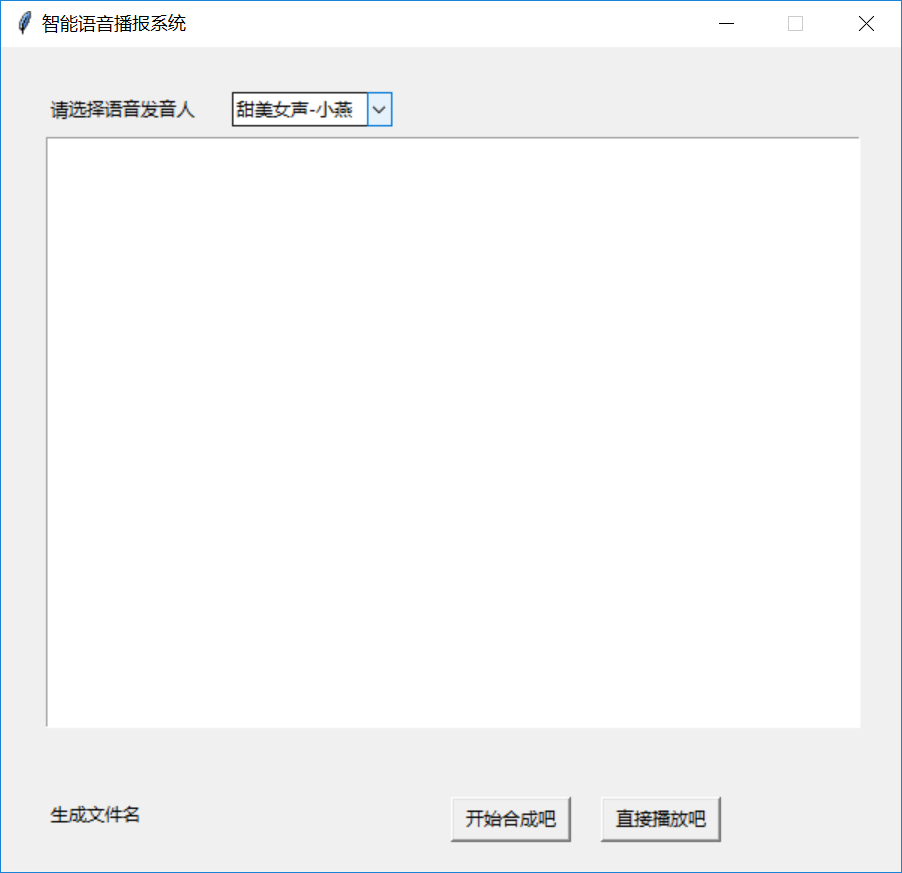
我们选择知性女声:

录入“十不干”点击合成。
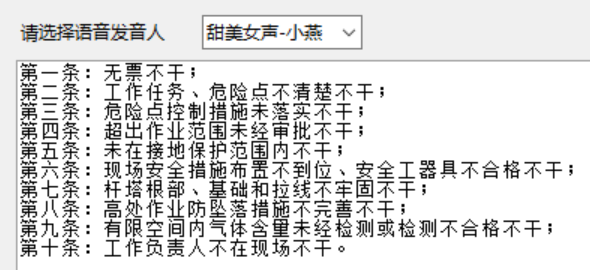
在程序文件目录自动生成了wav文件,点击直接播放,就可以听到美女声音了。

各种公司都开始训练自己的AI模型,然后拿出来卖钱,未来个人开发用户可以利用这些AI模型方便给自己赋能,大大地降低了了人工智能的开发学习门槛。把精力放到应用层面而不是模型训练层面。
如果公司购买了语音模型,并且有私有云,就可以把tkinter界面的代码改为html前端代码,通过私有云将语音模型的能力共享给全公司员工。
PS:好多人借鉴别人的代码直接抄,殊不知别人故意留了些bug,直接抄根本跑不通,好歹把自己的代码调通了再发吧。
在这里,永远只有我跑通测试完善的应用代码,关注我,我们下期应用再见。
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 机器学习交流qq群955171419,加入微信群请扫码:
评论