
手把手教你用Python打造一个语音合成系统
/前言/
平时我们聊天的时候,也许会想着录制一些自己的声音,而且还想有点特色,也就是所谓的变声,今天我们要说的就是这个变声器的制作,说的高大上点就是语音合成系统。
这个语音合成系统,能实现个性化语音的录制与存储。
/软件依赖/
使用sublime text 3 开发,申请百度开放平台账号进行开发。
/具体实现/
1、打开百度开放这平台创建一个应用拿到关键参数,如图所示:
2、因为我们使用Python开发一款智能语音合成系统,所以需要Python SDK ,可以在下图中找到:
3、找到之后可以看看它的使用说明。
4、然后创建一个应用,步骤依次如下图所示:

5、之后如下图所示:
6、再按照下图所示进行操作:
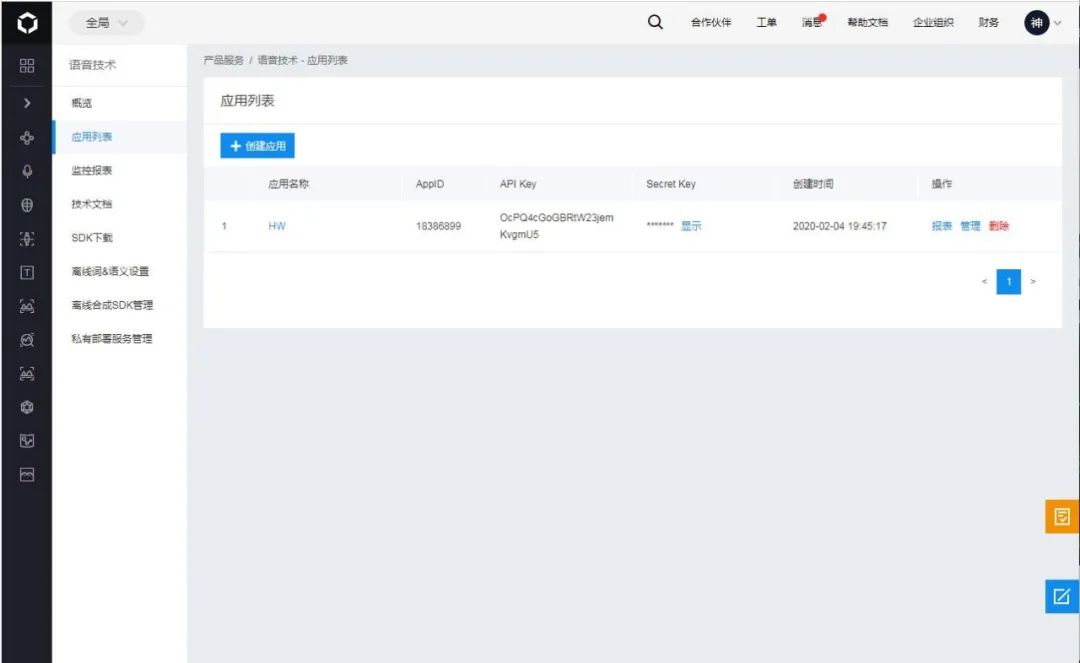
7、这样就拿到了三个重要的参数:
APP_ID:应用id
API_KEY:应用钥匙
SECRET_KEY:安全码
拿到以上关键参数之后,接下来就可以开始淦了!
/下载和配置百度语音客户端/
1、下载百度Python api
pip install baidu-aip2、配置百度语音客户端,具体步骤如下。
3、新建AipSpeech,代码如下。
from aip import AipSpeech""" 你的 APPID AK SK """APP_ID = '你的 App ID'API_KEY = '你的 Api Key'SECRET_KEY = '你的 Secret Key'client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
4、配置AipSpeech。如果用户需要配置AipSpeech的网络请求参数(一般不需要配置),可以在构造AipSpeech之后调用接口设置参数,目前只支持以下参数:
| 接口 | 说明 |
|---|---|
| setConnectionTimeoutInMillis | 建立连接的超时时间(单位:毫秒 |
| setSocketTimeoutInMillis | 通过打开的连接传输数据的超时时间(单位:毫秒) |
5、建立链接,生成音频文件,如下图所示。
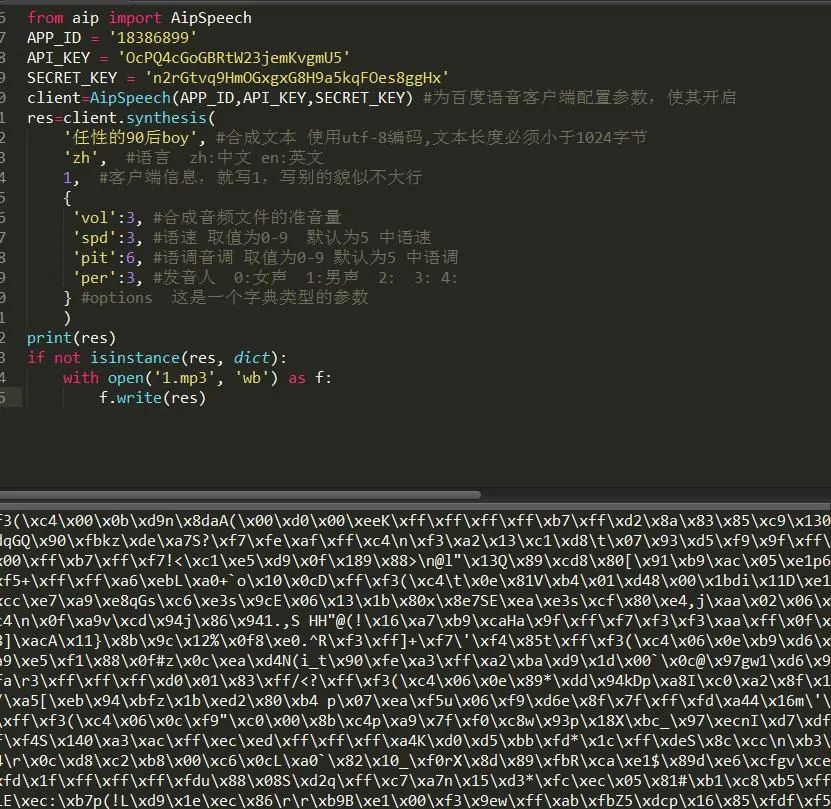
6、可以看出,成功生成音频文件会返回二进制文件流。这样还只是生成一个最简单的音频文件,我们还可以将他生成多种声音,参数如下表所示:
| 参数 | 类型 | 描述 | 是否必须 |
|---|---|---|---|
| text | String | 合成的文本,使用UTF-8编码, 请注意文本长度必须小于1024字节 | 是 |
| cuid | String | 用户唯一标识,用来区分用户, 填写机器 MAC 地址或 IMEI 码,长度为60以内 | 否 |
| spd | String | 语速,取值0-9,默认为5中语速 | 否 |
| pit | String | 音调,取值0-9,默认为5中语调 | 否 |
| vol | String | 音量,取值0-15,默认为5中音量 | 否 |
| per | String | 发音人选择, 0为女声,1为男声, 3为情感合成-度逍遥,4为情感合成-度丫丫,默认为普通女 | 否 |
这就是人工智能中的语音合成技术,调用百度的SDK,只用了几分钟,就完成了一年的开发量。
7、当然有失败就避免不了成功,一般请求失败会有这几种情况:
1)错误返回格式
若请求错误,服务器将返回的JSON文本包含以下参数:
error_code:错误码。
error_msg:错误描述信息,帮助理解和解决发生的错误。
2)错误码
| 错误码 | 含义 |
|---|---|
| 500 | 不支持的输入 |
| 501 | 输入参数不正确 |
| 502 | token验证失败 |
| 503 | 合成后端错误 |
看到上面这些参数是不是想跃跃欲试了了。哈哈,那就赶紧解放我们的双手吧!
/程序实现/
因为我们是要将它打造成一个语音合成的系统,所以当然得有界面才好看,具体实现如下。
1、编写程序主界面,具体代码实现如下。
class play:def __init__(self):self.root=tk.Tk() #初始化窗口self.root.title("语音合成系统") #窗口名称self.root.geometry("700x700") #设置窗口大小self.root.resizable(width=True,height=True)#设置窗口是否可变,宽不可变,高可变,默认为Trueself.lb=tk.Label(self.root,text='请选择语音类型')#标签self.tt=tk.Text(self.root,width=80,height=30) #多行文本框self.cb=ttk.Combobox(self.root, width=12) #下拉列表框#设置下拉列表框的内容self.cb['values']=('请选择-----','甜美型','萝莉型','大叔型','精神小伙型')self.cb.current(0) #将当前选择状态置为0,也就是第一项self.cb.bind("<>" ,self.go) #绑定go函数,然后触发事件self.lb1=tk.Label(self.root,text='请输入文件名:')self.e=tk.Entry(self.root,width=30,show=None, font=('Arial', 12)) #文本框self.b1=tk.Button(self.root, text='生成音频文件', width=10,height=1,command=self.sc) #按钮#各个组件的位置self.b1.place(x=200,y=520)self.lb.place(x=30,y=30)self.cb.place(x=154,y=30)self.e.place(x=130,y=490)self.lb1.place(x=30,y=490)self.tt.place(x=30,y=60)self.root.mainloop() #启动主页面
这样就算完成了程序的主界面了。
2、一起来看下它长啥样,如下图所示:
小伙伴们,是不是觉得很简洁大气呢?
3、绑定下拉列表框事件
在这里,我们需要对如何获取下拉列表框的选项要了解。言归正传,直接上代码:
def go(self,*arg): # *arg是为了接受多个如同列表的参数,还有个**kwarg能接受如同字典的参数#百度apiself.APP_ID = '18386899'self.API_KEY = 'OcPQ4cGoGBRtW23jemKvgmU5'self.SECRET_KEY = 'n2rGtvq9HmOGxgxG8H9a5kqFOes8ggHx'self.client = AipSpeech(self.APP_ID,self.API_KEY,self.SECRET_KEY)#初始化端口建立连接if self.cb.get()=='请选择-----':self.tt.delete('1.0','end') #清除多行文本框的内容elif self.cb.get()=='甜美型': #获取下拉列表框的选项来设置不同的音,下同self.res=self.client.synthesis(self.tt.get('0.0','end'),'zh',1,{'vol':3,'spd':3,'pit':4,'per':0})return self.res #返回音频信息 ,下同elif self.cb.get()=='萝莉型':self.res=self.client.synthesis(self.tt.get('0.0','end'),'zh',1,{'vol':2,'spd':2,'pit':3,'per':0})return self.reselif self.cb.get()=='大叔型':self.res=self.client.synthesis(self.tt.get('0.0','end'),'zh',1,{'vol':5,'spd':7,'pit':6,'per':1})return self.reselif self.cb.get()=='精神小伙型':self.res=self.client.synthesis(self.tt.get('0.0','end'),'zh',1,{'vol':7,'spd':8,'pit':8,'per':1})return self.res
4、判断内容的大小并生成文件
百度语音api里有个限制,就是单个音频生成是有限制的,不能超过1024字节。鉴于此,所以需要在这里做个判断:
def sc(self):self.go() #引入go函数,不然下面的self.res 没法调用aa=self.tt.get('0.0','end') #多行文本框内容为空ab=os.path.dirname(sys.argv[0])+os.sep+self.e.get()+'.mp3'#文件名的地址,与程序同目录if len(aa)>=1024: #判断长度是否超过1024messagebox.showerror(title = '出错了!',message='^_^最多不超过1024个字节^_^')else:if not os.path.exists(ab): #如果没有这个文件则创建with open(ab,'wb') as f:f.write(self.res) #将音频信息写入到文件#生成结束给一个提示messagebox.showinfo(title = '完毕!', message='生成完毕,文件在程序目录下')else:messagebox.showerror(title='出错了!',message='文件名已存在') #有这个文件就提示
5、接下来,我们只需将这几个功能写入到一个类中即可,然后启动这个类。
play()6、当我输入一段话后,大家可以看到它就生成了一个音频文件。而且读取的时候和我们输入的内容一模一样,比如我输入一段代码,见下图:
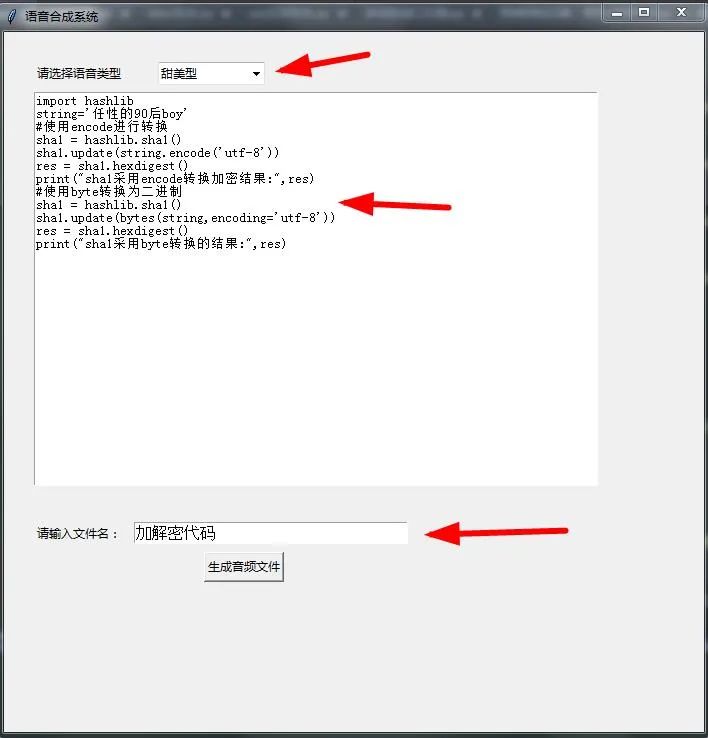
7、之后会得到下图所示的情形。
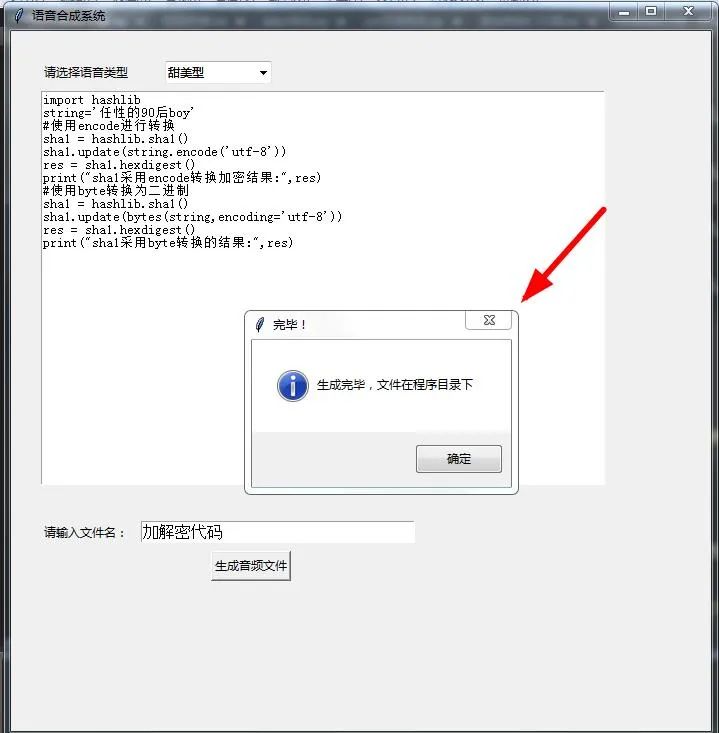
8、最后的效果如下图所示。
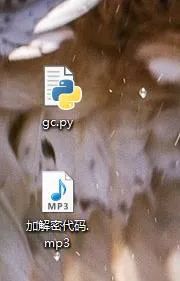
完美收工,哈哈哈!
/小结/
1、本文基于Python编程语言,结合百度开放平台,通过调用其接口,打造了一款简易的语音合成系统,方法行之有效,欢迎小伙伴们积极尝试。
2、需要本文代码的小伙伴可以在后台回复“语音合成”四个字进行获取。
想学习更多关于Python的知识,可以参考学习网址:http://pdcfighting.com/,点击阅读原文,可以直达噢~
------------------- End -------------------
PS:公号内回复「Python」即可进入Python 新手学习交流群,一起 100 天计划!
老规矩,兄弟们还记得么,右下角的 “在看” 点一下,如果感觉文章内容不错的话,记得分享朋友圈让更多的人知道!


【神秘礼包获取方式】