在几乎任何行业的所有用例中,实时数据都优于慢速数据。所以,问问你自己或者你的业务团队,他们希望或者需要在下一个项目如何消费和处理数据。静态数据和动态数据是有取舍的。因此,这两个概念是相辅相成的。基于此,现代云计算的基础设施在其架构中同时应用了这两个概念。《使用 Kafka 的无服务器事件流与亚马逊云科技 Lakehouse 的结合》(Serverless Event Streaming with Kafka combined with the AWS Lakehouse)是一个很好的资源,可以了解更多的信息。
但是,尽管将批处理系统连接到实时神经系统是可能的,但反过来说,将实时消费者连接到批处理存储就不太可能了。关于 《Kappa 与 Lambda 架构》(Kappa vs. Lambda Architecture)文章的讨论,将会给我们带来更多的见解。
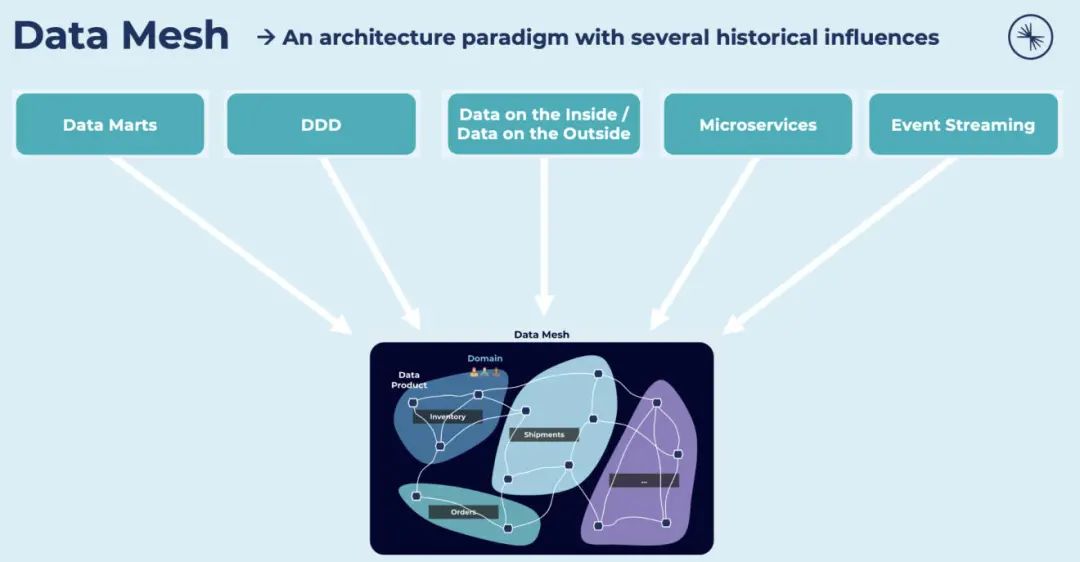
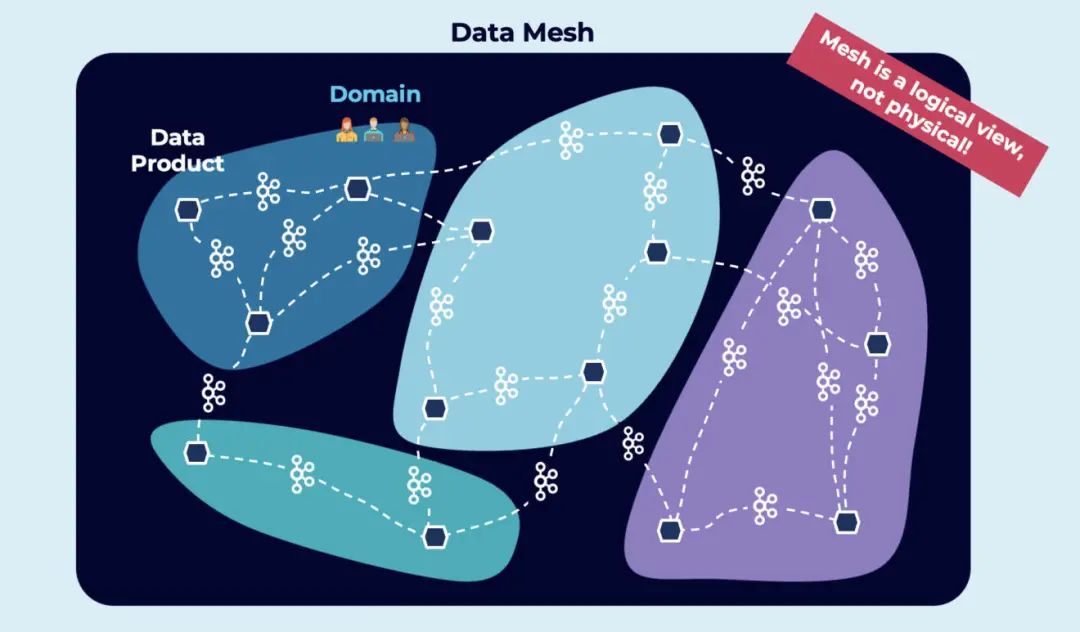
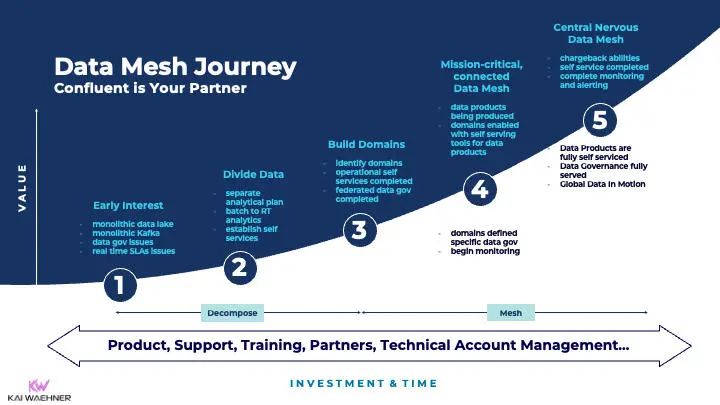
数据网格是一种实现模式(不同于微服务或域驱动设计),但应用于数据。ThoughtWorks 发明了这个词。你可以在网络上发现很多资源。Zhamak Dehghani 在 2021 年欧洲 Kafka 峰会上就“如何构建数据网格基础及其与事件流的关系”(How to build the Data Mesh Foundation and its Relation to Event Streaming) 做了精彩演讲。
Kafka API 是事件流的事实标准。我不再对此进行重复的讨论。在我们进入“Kafka + 数据网格”内容之前,这里有一些参考资料:
《为什么 Kafka 会像 Amazon S3 一样成为标准 API?》(Why Kafka became a Standard API like Amazon S3)
《事件流和 Kafka 供应商的比较,如 Red Hat、Cloudera、Confluent、Amazon MSK 的比较》(Comparison of event streaming and Kafka vendors like Red Hat, Cloudera, Confluent, Amazon MSK)
《Apache Kafka 与 Apache Pulsar》(Apache Kafka versus Apache Pulsar)
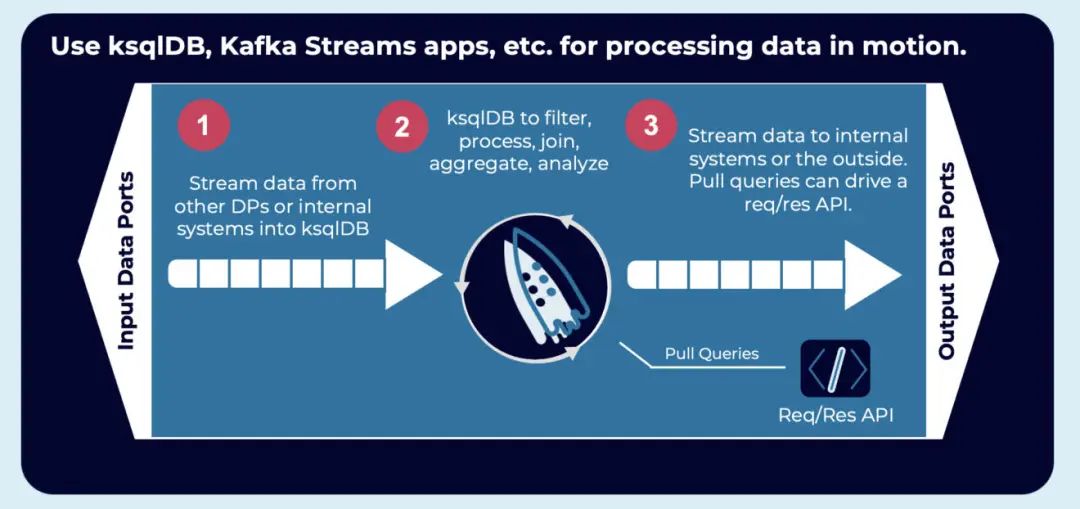
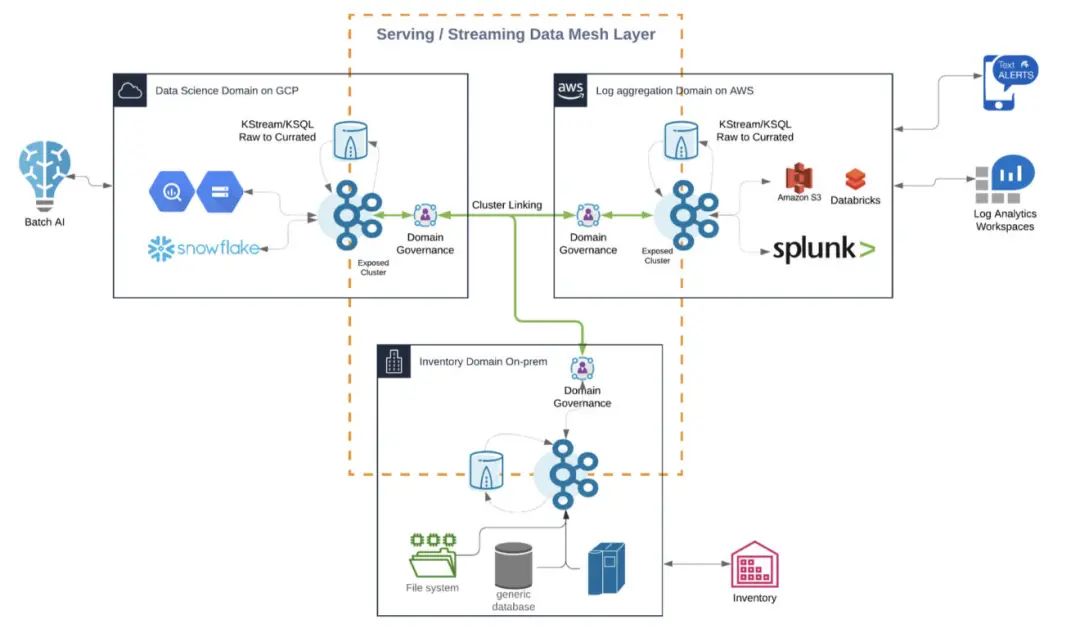
Kafka 支持的数据网格
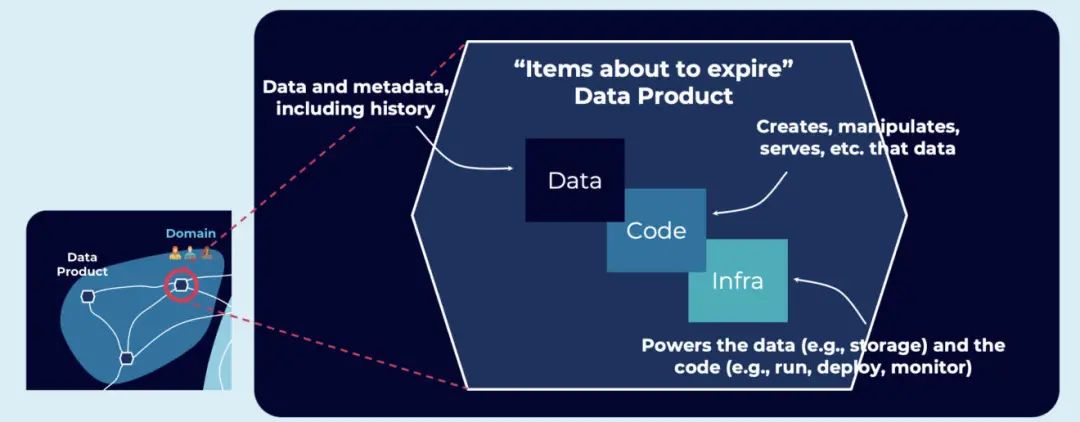
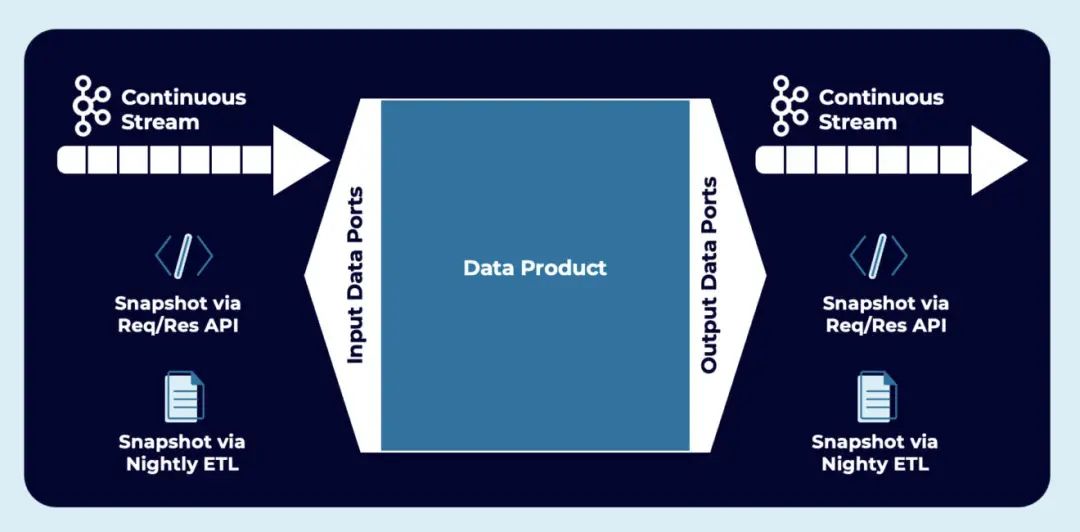
我强烈推荐大家观看 Ben Stopford 和 Michael Noll 关于《Apache Kafka 和数据网格》(Apache Kafka and the Data Mesh)的演讲。本文的几张截图也是来自那个演讲。为我的两位同事点赞!演讲探讨了数据网格的关键概念以及它们与事件流的关系:
我可以继续列举下去。许多数据产品都需要通过第三方进行大规模的实时访问。在这种情况下,有些 API 网关或 API 管理工具就会发挥作用。
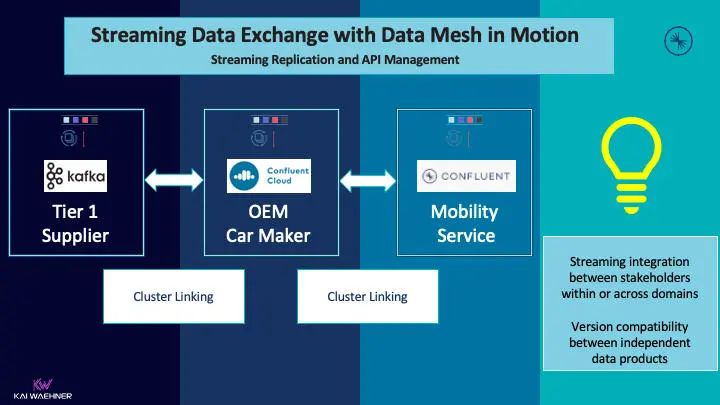
一个 由 Kafka 支持的流数据交换的现实世界的实例是移动服务 Here Technologies。他们公开了 Kafka API,可以直接从其映射服务中获取流数据(作为他们的 HTTP API 的一个替代选择):
但是,即便所有的合作伙伴都在自己的架构中使用 Kafka,那么直接向外界公开 Kafka API 并不一定总是正确的。Kafka 生态系统的某些技术能力(例如访问控制或连接到成千上万的设备),以及缺失的业务功能(如货币化或报告),使得事件流基础设施之上的 API 层在许多实际部署中发挥作用。
用于第三方集成和流 API 管理的开放 API
API 网关和 API 管理工具有很多种类,包括开源框架、商业产品和 SaaS 云产品。功能包括技术路由、访问控制、货币化和报告。
然而,大多数人仍然以 RPC 的方式实现开放 API 的概念。我猜 95% 以上的人还在使用 HTTP(S) 来使 API 能够被其他利益相关者(例如其他业务部门或外部各方)访问。如果数据需要实时地大规模处理,那么 RPC 在流数据网格架构中就没有什么意义了。
事件流和 API 管理之间仍然存在阻抗不匹配的问题。但是,现在情况有所好转。像 AsyncAPI 这样的规范,自称是“定义异步 API 的行业标准”,还有类似的方法为数据流世界带来了开放 API。我那篇名为《Kafka 与 MuleSoft、Kong 或 Apigee 等工具的 API 管理》(Kafka versus API Management with tools like MuleSoft, Kong, or Apigee)的论文,如果你愿意对此进行更深入的探讨,那么它依然是非常正确的。IBM API Connect 是最早通过 Async API 集成 Kafka 的厂商之一。
从 RPC 到流 API 的演变,一个很好的例子就是机器学习领域。《用 Kafka 原生模型部署流式机器学习》(Streaming Machine Learning with Kafka-native Model Deployment)探讨了 Seldon 等模型服务器如何在 HTTP 和 gRPC 请求—响应通信之外用原生 Kafka API 增强他们的产品: