
使用pandas进行数据快捷加载

导读:在已经准备好工具箱的情况下,我们来学习怎样使用pandas对数据进行加载、操作、预处理与打磨。
让我们先从CSV文件和pandas开始。

import pandas as pd
Iris_filename=’datasets-uci-iris.csv’
Iris=pd.read_csv(iris_filename,sep=’_’,decimal=’_’,heade=None,
names=[‘sepal_length’,‘sepal_width’
‘petal_length’,‘petal_width’
‘target’])import urllib
url=”http://aima.cs.berkeley.edu/data/iris.csv”
set1=urllib.request.Request(ur1)
iris_p=urllib.request.urlopen(set1)
iris_other=pd.read_csv(iris_p,sep=',',decimal='.',
header=None, names=[‘sepal_length’,‘sepal_width’
‘petal_length’,‘petal_width’
‘target’ ])
iris_other.head()iris.head()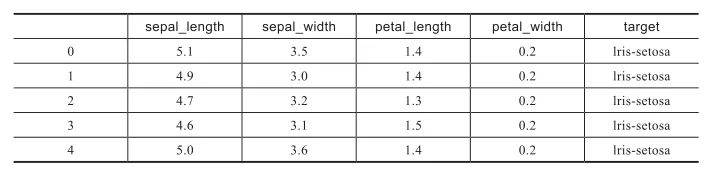
iris.tail()iris.head(2)iris.columns
Index([‘sepal_length’,‘sepal_width’
‘petal_length’,‘petal_width’
‘target’ ],dtype=‘object’ )
y=iris[‘target’ ]
y
0 Iris-setosa
1 Iris-setosa
2 Iris-setosa
3 Iris-setosa
...
149 Iris-virginica
Name:target,dtype:object
x =iris[[ ‘sepal_length’,‘sepal_width’ ]]
x
[150 rows x 2 columns]
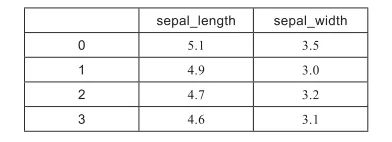
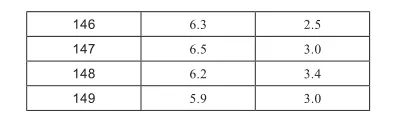
print (X.shape)
#输出:(150,2)
print (y.shape)
#输出:(150,)
评论