
Kafka 生产者的使用和原理
本文将学习Kafka生产者的使用和原理,文中使用的kafka-clients版本号为2.6.0。下面进入正文,先通过一个示例看下如何使用生产者API发送消息。
public class Producer {
public static void main(String[] args) {
// 1. 配置参数
Properties properties = new Properties();
properties.put("bootstrap.servers", "localhost:9092");
properties.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
// 2. 根据参数创建KafkaProducer实例(生产者)
KafkaProducer producer = new KafkaProducer<>(properties);
// 3. 创建ProducerRecord实例(消息)
ProducerRecord record = new ProducerRecord<>("topic-demo", "hello kafka");
// 4. 发送消息
producer.send(record);
// 5. 关闭生产者示例
producer.close();
}
}
首先创建一个Properties实例,设置了三个必填参数:
bootstrap.servers:broker的地址清单;key.serializer:消息的键的序列化器;value.serializer:消息的值的序列化器。
由于broker希望接受的是字节数组,所以需要将消息中的键值序列化成字节数组。在设置好参数后,根据参数创建KafkaProducer实例,也就是用于发送消息的生产者,接着再创建准备发送的消息ProducerRecord实例,然后使用KafkaProducer的send方法发送消息,最后再关闭生产者。
关于KafkaProducer,我们先记住两点:
在创建实例的时候,需要指定配置; send方法可发送消息。
关于配置我们先只了解这三个必填参数,下面我们看下send方法,关于发送消息的方式有三种:
发送并忘记(fire-and-forget)
在发送消息给Kafka时,不关心消息是否正常到达,只负责成功发送,存在丢失消息的可能。上面给出的示例就是这种方式。
同步发送(sync)
send方法的返回值是一个Future对象,当调用其get方法时将阻塞等待Kafka的响应。如下:FuturerecordMetadataFuture = producer.send(record);
RecordMetadata recordMetadata = recordMetadataFuture.get();RecordMetadata对象中包含有消息的一些元数据,如消息的主题、分区号、分区中的偏移量、时间戳等。异步发送(async)
在调用
send方法时,指定回调函数,在Kafka返回响应时,将调用该函数。如下:producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e != null) {
e.printStackTrace();
} else {
System.out.println(recordMetadata.topic() + "-"
+ recordMetadata.partition() + ":" + recordMetadata.offset());
}
}
});onCompletion有两个参数,其类型分别是RecordMetadata和Exception。当消息发送成功时,recordMetadata为非null,而e将为null。当消息发送失败时,则反之。
下面我们认识下消息对象ProducerRecord,封装了发送的消息,其定义如下:
public class ProducerRecord<K, V> {
private final String topic; // 主题
private final Integer partition; // 分区号
private final Headers headers; // 消息头部
private final K key; // 键
private final V value; // 值
private final Long timestamp; // 时间戳
// ...其他构造方法和成员方法
}
其中主题和值为必填,其余非必填。例如当给出了分区号,则相当于指定了分区,而当未给出分区号时,若给出了键,则可用于计算分区号。关于消息头部和时间戳,暂不讲述。
在对生产者对象KafkaProducer和消息对象ProducerRecord有了认识后,下面我们看下在使用生产者发送消息时,会使用到的组件有生产者拦截器、序列化器和分区器。其架构(部分)如下:
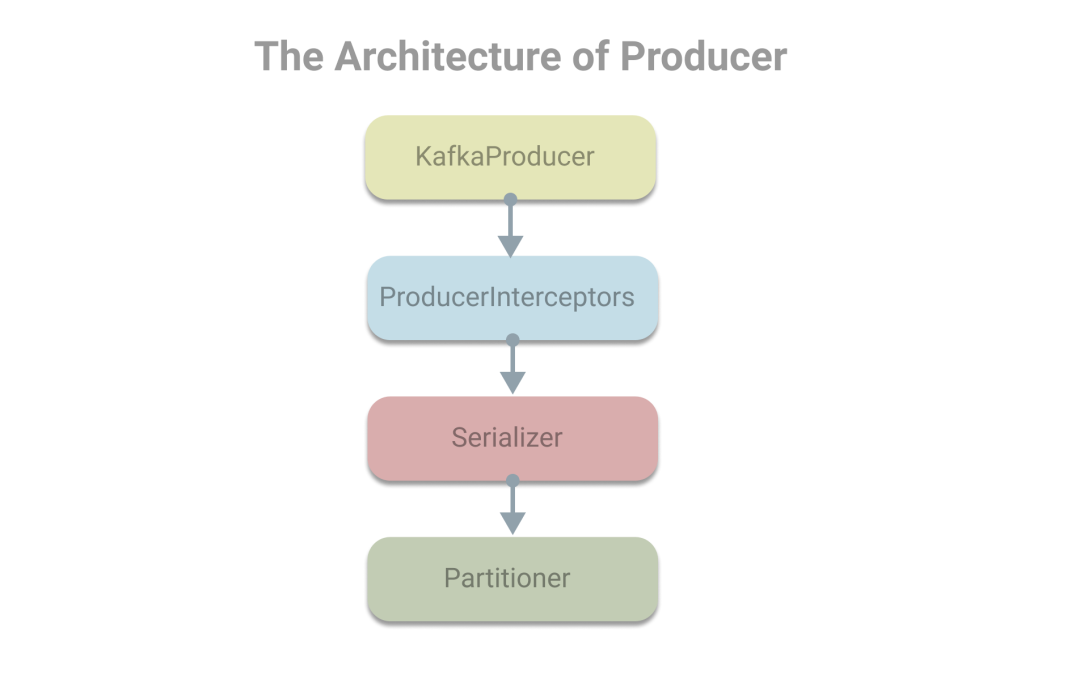
生产者拦截器: ProducerInterceptor接口,主要用于在消息发送前做一些准备工作,比如对消息做过滤,或者修改消息内容,也可以用于在发送回调逻辑前做一些定制化的需求,例如统计类工作。序列化器, Serializer接口,用于将数据转换为字节数组。分区器, Partitioner接口,若未指定分区号,且提供key。
下面结合代码来看下处理过程,加深印象。
public Future send(ProducerRecord record, Callback callback) {
// 拦截器,拦截消息进行处理
ProducerRecord interceptedRecord = this.interceptors.onSend(record);
return doSend(interceptedRecord, callback);
}
上面是KafkaProducer的send方法,首先会将消息传给拦截器的onSend方法,然后进入doSend方法。其中doSend方法较长,但内容并不复杂,下面给出了主要步骤的注释。
private Future doSend(ProducerRecord record, Callback callback) {
TopicPartition tp = null;
try {
throwIfProducerClosed();
// 1.确认数据发送到的topic的metadata可用
long nowMs = time.milliseconds();
ClusterAndWaitTime clusterAndWaitTime;
try {
clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), nowMs, maxBlockTimeMs);
} catch (KafkaException e) {
if (metadata.isClosed())
throw new KafkaException("Producer closed while send in progress", e);
throw e;
}
nowMs += clusterAndWaitTime.waitedOnMetadataMs;
long remainingWaitMs = Math.max(0, maxBlockTimeMs - clusterAndWaitTime.waitedOnMetadataMs);
Cluster cluster = clusterAndWaitTime.cluster;
// 2.序列化器,序列化消息的key和value
byte[] serializedKey;
try {
serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert key of class " + record.key().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG).getName() +
" specified in key.serializer", cce);
}
byte[] serializedValue;
try {
serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert value of class " + record.value().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG).getName() +
" specified in value.serializer", cce);
}
// 3.分区器,获取或计算分区号
int partition = partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);
setReadOnly(record.headers());
Header[] headers = record.headers().toArray();
int serializedSize = AbstractRecords.estimateSizeInBytesUpperBound(apiVersions.maxUsableProduceMagic(),
compressionType, serializedKey, serializedValue, headers);
ensureValidRecordSize(serializedSize);
long timestamp = record.timestamp() == null ? nowMs : record.timestamp();
if (log.isTraceEnabled()) {
log.trace("Attempting to append record {} with callback {} to topic {} partition {}", record, callback, record.topic(), partition);
}
Callback interceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp);
if (transactionManager != null && transactionManager.isTransactional()) {
transactionManager.failIfNotReadyForSend();
}
// 4.消息累加器,缓存消息
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs, true, nowMs);
if (result.abortForNewBatch) {
int prevPartition = partition;
partitioner.onNewBatch(record.topic(), cluster, prevPartition);
partition = partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);
if (log.isTraceEnabled()) {
log.trace("Retrying append due to new batch creation for topic {} partition {}. The old partition was {}", record.topic(), partition, prevPartition);
}
// producer callback will make sure to call both 'callback' and interceptor callback
interceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp);
result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs, false, nowMs);
}
if (transactionManager != null && transactionManager.isTransactional())
transactionManager.maybeAddPartitionToTransaction(tp);
// 5.如果batch满了或者消息大小超过了batch的剩余空间需要创建新的batch
// 将唤醒sender线程发送消息
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
this.sender.wakeup();
}
return result.future;
} catch (ApiException e) {
log.debug("Exception occurred during message send:", e);
if (callback != null)
callback.onCompletion(null, e);
this.errors.record();
this.interceptors.onSendError(record, tp, e);
return new FutureFailure(e);
} catch (InterruptedException e) {
this.errors.record();
this.interceptors.onSendError(record, tp, e);
throw new InterruptException(e);
} catch (KafkaException e) {
this.errors.record();
this.interceptors.onSendError(record, tp, e);
throw e;
} catch (Exception e) {
this.interceptors.onSendError(record, tp, e);
throw e;
}
}
doSend方法主要分为5个步骤:
在发送数据前,先确认数据发送的topic的metadata是可用的(partition的leader存在即为可用,如果开启了权限控制,则还要求client具有相应的权限); 序列化器,序列化消息的key和value; 分区器,获取或计算分区号; 消息累加器,缓存消息; 在消息累加器中,消息会被放在一个batch中,用于批量发送,当batch满了或者消息大小超过了batch的剩余空间需要创建新的batch,则将唤醒sender线程发送消息。
关于meatadata本文将不深究,序列化器、分区器前文也给出了介绍。下面我们主要看下消息累加器。
消息累加器,其作用是用于缓存消息,以便批量发送消息。在RecordAccumulator中用一个ConcurrentMap的map变量保存消息。作为key的TopicPartition封装了topic和分区号,而对应的value为ProducerBatch的双端队列,也就是将发往同一个分区的消息缓存在ProducerBatch中。在发送消息时,Record会被追加在队列的尾部,即加入到尾部的ProducerBatch中,如果ProducerBatch的空间不足或队列为空,则将创建新的ProducerBatch,然后追加。当ProducerBatch满了或创建新的ProducerBatch时,将唤醒Sender线程从队列的头部获取ProducerBatch进行发送。
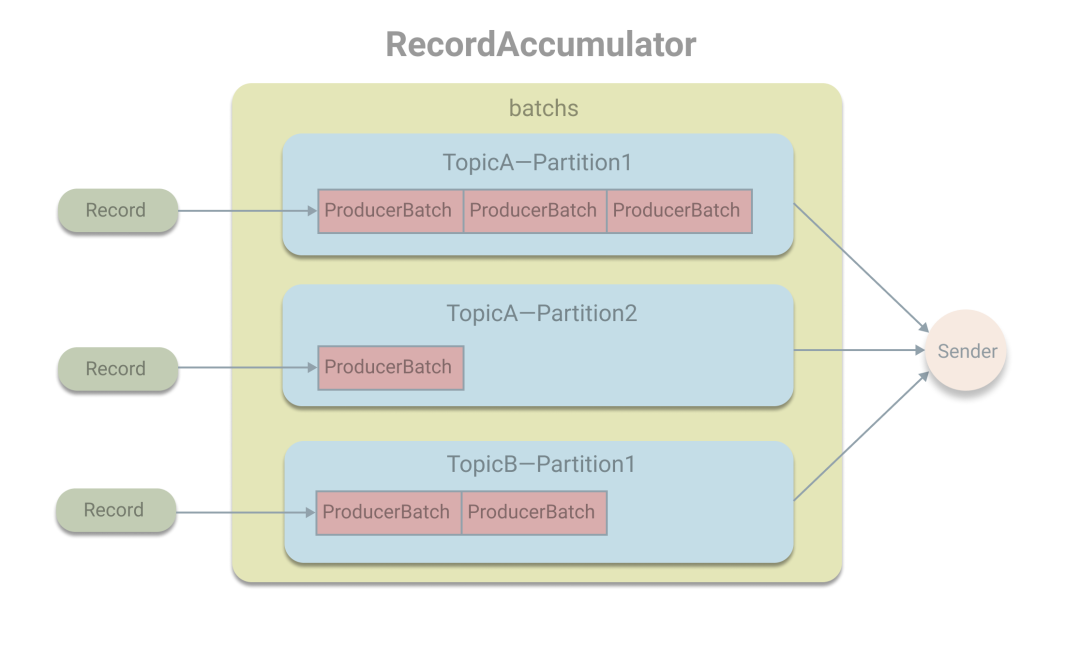
在Sender线程中会将待发送的ProducerBatch将转换成ProducerBatch放在一个请求中发送。
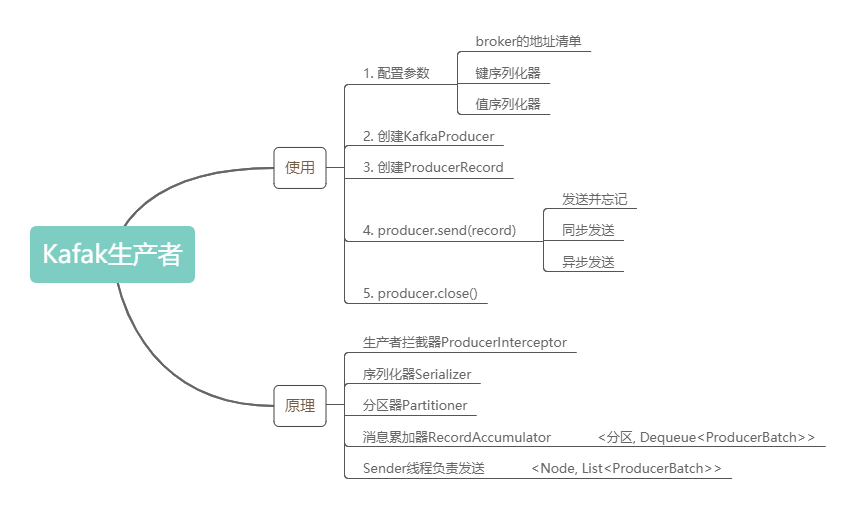
Kafak生产者的内容就先了解到这,下面通过思维导图对本文内容做一个简单的回顾:
参考
《深入理解Kafka核心设计与实践原理》 《Kafka权威指南》 Kafka 源码解析之 Producer 发送模型(一): http://matt33.com/2017/06/25/kafka-producer-send-module/
完

觉得不错,点个在看~
