
因买不到RTX 3090,小哥自己搭建了一个专业级机器学习工作站

极市导读
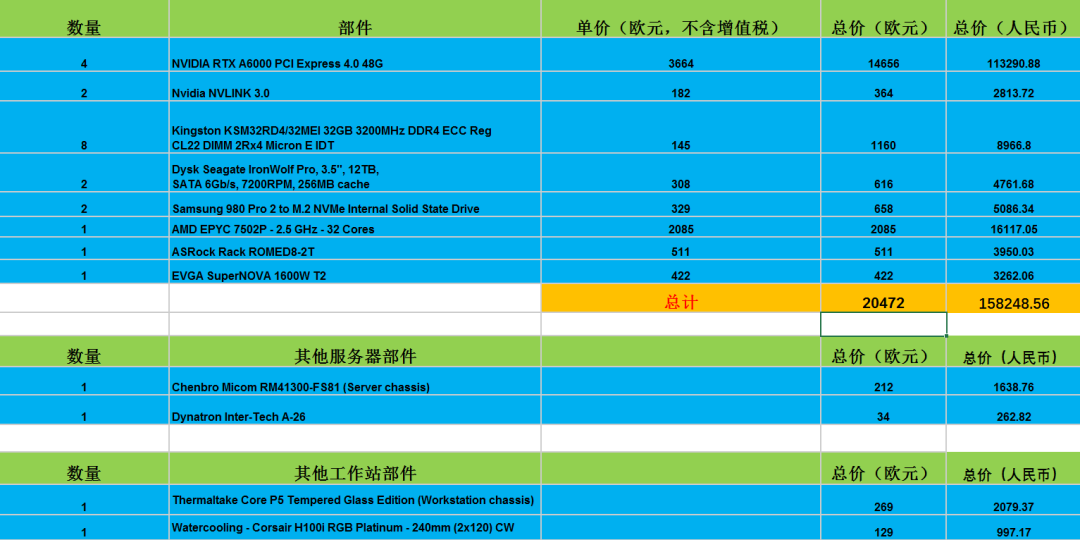
一名机器学习研究员自己搭建了一个机器学习工作站,它拥有4个NVIDIA RTX A6000和一个32核的AMD EPYC 2、192 GB的GPU显存和256GB的RAM。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
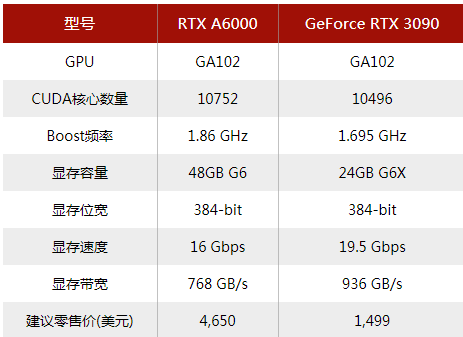
GPU
消费级:RTX 3080 / RTX 3090 专业级(prosumer,或称生产性消费级):A6000 企业级:A100
消费级:两个RTX 3080s / RTX 3090s 专业级:四个A6000 企业级:8个A100或A6000(PCIe),或16个A100(SXM4),或20个A100(基于PCIe的模块化刀片节点)
非企业级GPU的限制
PCIe转接卡的主板限制:14个GPU(每个GPU x8 Gen 4.0) 每个插槽的用电量限制:8个GPU(美国为4个) 消费级电源限制:5个GPU(2000W) 标准PC机箱尺寸:4个双插槽GPU
堆叠的显卡彼此相邻:4个A6000 / 3070或2个3080/3090 热量限制:2个GPU(最好是水冷式) 消费者供应量:1个GPU(大多数商店只允许购买一个消费级GPU,并且通常仅在发布后3到12个月内可购买)

为什么存在8-GPU消费级工作站?
2
专业级显卡和企业级显卡的功能
快1.1-2倍(取决于GPU、二进制浮点格式和模型) 1.7-3.3倍的内存 能耗更低(更适合堆叠卡) 数据中心部署(非营利组织可以获取消费卡许可)
ECC内存(防错内存) 每个GPU和MIG(仅限企业级)可有多个用户 NVSwitch(A100 SXM4),更快的GPU到GPU的通信
3
服务器限制
带有消费级部件的服务器:4个PCIe GPU PCIe服务器的限制:10个双插槽GPU(标准服务器的宽度) 重量:10个PCIe GPU或4个SMX4 GPU(30千克)
PCIe服务器机箱的联网限制:8个双插槽GPU(2个双插槽用于联网) SXM4服务器的机箱数量限制:16个GPU(168千克) PCIe刀片服务器限制:20个双插槽GPU
4
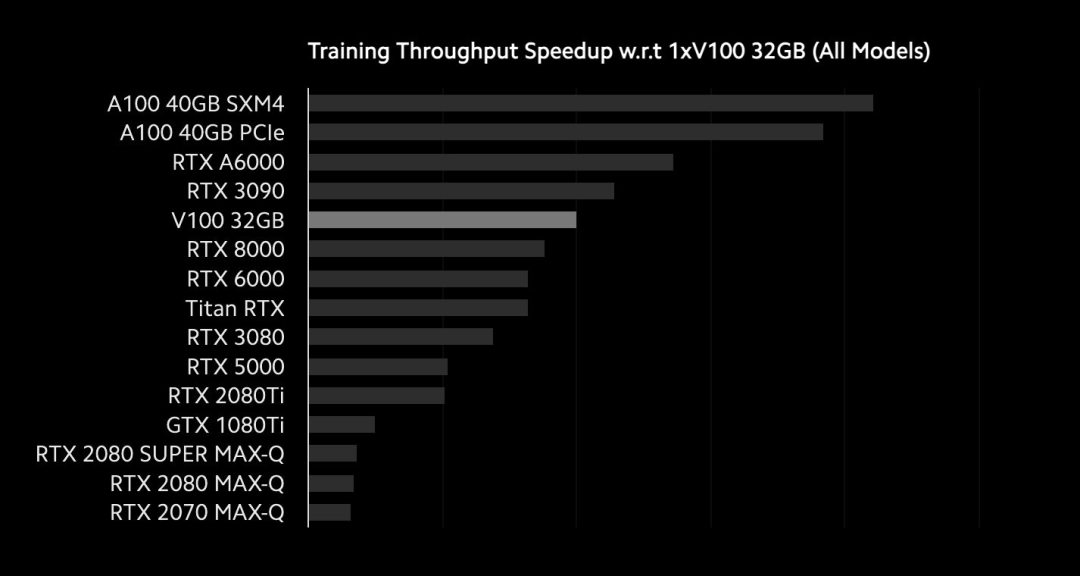
速度基准
https://lambdalabs.com/blog/tag/benchmarks/ https://lambdalabs.com/gpu-benchmarks


GPU定价
A100 SMX4(80 GB):€18k A100 SMX4(40 GB):€13k A100 PCIe(40 GB):€9k
RTX A6000 / A40(48GB):€4500 RTX 3090(24 GB):€1500-2000 RTX 3080(10 GB):€800-1300 RTX 3070(12 GB):€700-1000
机器学习工作站预算
€240-340k:8 x A100 SXM4(80 GB) €120-170k:8 x A100 SXM4(40 GB)
€90k:8 x A100 PCIe(40 GB) €50k:4 x A100 PCIe或8 x RTX A40(无风扇RTX A6000) €25k:4 x RTX A6000(我的装备) €25k:4 x RTX 3090(液冷) €15k:4 x RTX 3090(加密风格或上限性能)
€10k:4 x RTX 3070 €7k:2 x RTX 3090 €5k:1 x RTX 3090或2 x RTX 3080 €4k:1 x RTX 3080 €3k:1 x RTX 3070
CPU
消费级:带有AM4插槽的Ryzen 5000 专业级:Ryzen Threadripper第三代,带有sTRX4,以及用于第一代Pro版本的sWRX8插槽 企业级:带有SP3插槽的EPYC 2
CPU散热
锐龙5000:Noctua NH-D15或Corsair H100i RGB PLATINUM Threadripper:Noctua NH-U14S TR4-SP3或Corsair Hydro系列H100x EPYC:Dynatron A26 2U(用于服务器)
主板
锐龙5000:MSI PRO B550-A PRO AM4(ATX) Threadripper 3rd Gen:华擎TRX40 CREATOR(ATX) Threadripper Pro:ASUS Pro WS WRX80E-SAGE SE(ETAX) EPYC 2:AsRock ROMED8-2T(ATX)(我的主板)
主板尺寸

PCI Express(PCIe)

PCIe物理长度:图中每个插槽的长度为x16,GPU的标准长度为89mm。 PCIe带宽:有时,你有一个16插槽的长度,但只有一半的插槽有连接到主板的管脚,使其成为x8带宽的x16插槽。作为参考,加密钻机将使用x16适配器,但x1带宽。 生成速度:上面的板是4.0代。每一代的速度往往是上一代的两倍。NVIDIA的最新gpu是gen4.0,但在实际应用中在gen3.0板上的性能相当。 多GPU要求:对于4-10 GPU系统,通常建议每个GPU至少x8 Gen 3.0。
PCIe通道
机箱


10
PSU、RAM和存储
搭建和安装
 )
)结论
推荐阅读
2021-01-25

2021-01-21

2020-08-21


# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~

评论