
拯救pandas计划(1)——将一维数组转换为二维数组
拯救pandas计划(1)——将一维数组转换为二维数组
数据需求
需求拆解
数据导入
需求处理
方法一:pivot_table
方法二:unstack
总结
最近发现周围的很多小伙伴们都不太乐意使用pandas,转而投向其他的数据操作库,身为一个数据工作者,基本上是张口pandas,闭口pandas了,故而写下此系列以让更多的小伙伴们爱上pandas。
系列文章说明:
系列名(系列文章序号)——此次系列文章具体解决的需求
平台:
windows 10 python 3.8 pandas 1.2.4
数据需求
将下方左边红框的数据转置成右边的形式。
首先,使用代码并不是为了处理简单且一次性使用的场景,会得不偿失,就如群友【心田有垢生荒草】在少量数据可以这样操作,而数据量较大时改用pivot_table惨遭滑铁卢: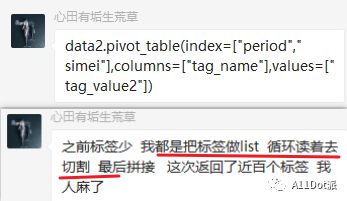
对于这个需求乍一看,还挺容易弄的,但是没有一些数据操作经验的话还是有些许难度,有用过excel的小伙伴就会想到用透视表操作,但在我这,不得行,为了让pandas重回数据操作巅峰,我决定逝一逝。
需求拆解
从左图到右图很明显的看到需要将tag_name中的所有数据作为新的列名,而period和simei应该是唯一值。
数据导入
首先导入数据: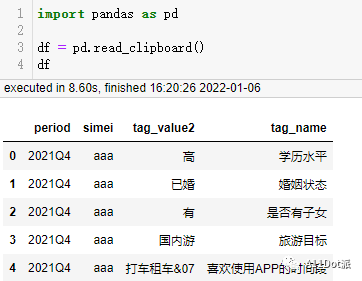
需求处理
方法一:pivot_table
直接使用pivot_table会报数据不为数值型的错误,其中aggfunc默认参数为mean,无法操作字符串,为了能达到需求目的,需要自建一个函数:
def eval_func(x):
return x
df = pd.pivot_table(df, values='tag_value2', index=['period', 'simei'], columns=['tag_name'], aggfunc=eval_func).reset_index()
df.columns = df.columns.values
使用pivot_table调用eval_func,生成了一个有多级索引的透视表。 再重置索引,并重新设置列名,完成需求。
再重置索引,并重新设置列名,完成需求。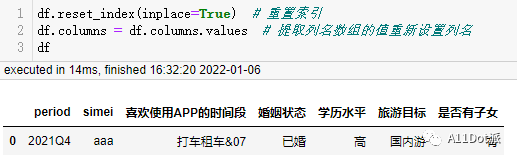
方法二:unstack
可以说是能用pivot_table完成的,那用unstack做也不是不可。
df = df.set_index(['period', 'simei', 'tag_name']).unstack('tag_name')
df.columns = df.columns.get_level_values(1).values
df.reset_index()
为了能够正确的将目标列unstack至表头,即设置成列名,需要先把需要处理的列设置成索引。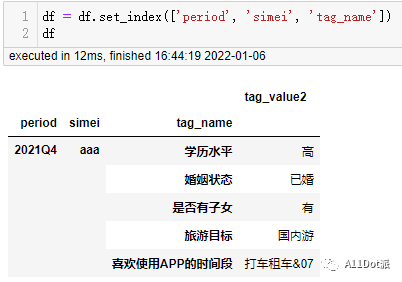 再对
再对tag_name索引进行 unstack() 转成列名。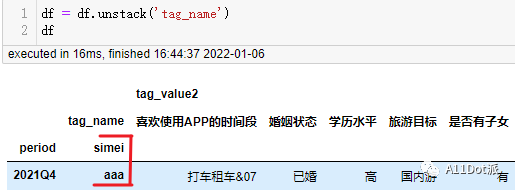
目前列部分为多层索引,红框内为多级索引,这里处理比较简单,先将列名的多层转成一层,而且这个列名显示的非常不友好,可以先打印出来看看是什么格式,再通过方法进行特定值提取。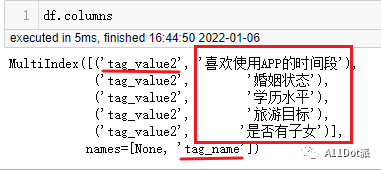
tag_value2和tag_name都在输出值里,但是所需要的只有红框的部分。调用 get_level_values() 获取指定索引处的值并重设置为列名,再将多级索引进行 reset_index() 完成需求。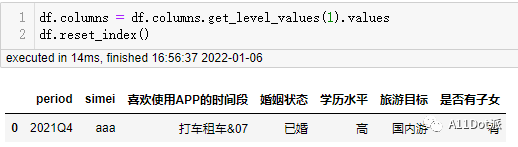
总结
对大量数据的处理中,pandas不失为一个好帮手,本节例子仅仅展示了其冰山一角,对于这个需求处理也只是起到抛砖引玉的作用,再次感谢【心田有垢生荒草】提供数据,如有更好的方法亦可在评论区留言或联系作者进行讨论。
数据如海洋,努力找到前行的灯塔,才不会迷失自我。
于二零二二年一月六日作