
视频图像色彩增强的主要方法与落地实践

背景
色彩增强作为视频后处理中画质增强技术的一部分,指的是通过调整图片和视频画面的饱和度特性,使得画面色彩更加丰富和逼真,提升人的视觉主观感受。由于设备摄像头的多样性,部分摄像头在视频采集时存在饱和度不足,画面发灰,色彩寡淡等问题,这些情况在拍摄室外景物和颜色丰富的场景时尤其容易出现。这些问题可以通过算法的后处理调整进行改善。色彩增强配合视频降噪,暗光增强,对比度调整,边缘增强等技术,可以对视频画质起到较大的提升作用。

■色彩增强效果示意图(左:原图 右:增强后)
原图来源:HEVC 标准测试码流
色彩增强算法的设计
后处理对于颜色的调整,一般有两个不同的目标,“还原”和“好看”。“还原”指的是使画面能够真实呈现场景的真实颜色,不偏色。“好看”指的是画面的颜色层次足够丰富和自然,能够提升人视觉的舒适感,使天空更蓝草地更绿,出来的画面更符合人的喜好,是一个相对主观的指标。色彩增强主要关注在“好看”这一目标上。目前针对色彩增强的客观评价标准和公共数据集都比较缺乏,根据搜集到的一些资料,大约可以归纳出以下色彩增强算法的设计目标:
1. 调整后能够提高人对画面质量的主观感受。这个目标是否达成,主要依赖于开发人员、评测人员和用户的主观判断打分。
2. 算法具有适应性。适应性是指对于不同图像,或者同一图像的不同部分,调节强度因应图像特性而有差异。避免导致原来已经较为鲜艳的色彩出现过饱和的现象。
3. 调整后不产生明显瑕疵。色彩增强比较容易产生的问题是过饱和,画面细节的丢失,偏色,或者导致颜色分层等瑕疵。另外也很容易强化画面暗部的彩色噪声。
4. 对于视频帧序列来说,色彩增强的处理不能造成画面颜色突变。比如一些依赖于全局统计量的算法,光源的突然出现可能会造成画面效果的突变,造成画面效果的跳变。
5. 对人像的肤色进行保护。单纯的色彩增强算法容易导致人像肤色变“橙”的问题。由于人的肤色与物体的颜色不同,存在一个经验合理范围,调整超出这个范围之后就会使人像看上去不真实。所以需要对人的肤色进行一定的保护。
6. 需要考虑色彩增强在整个视频处理流程中与其他画质调整模块的配合,会否造成整体效果变差的情况。
以上的各点可以看做是算法设计时的一个自检表,并非必要全部严格满足,但是如果其中的一项出现了比较严重的问题,那么这个算法的可用性会大打折扣。
颜色模型的选择
色彩增强方法一般通过将 RGB 颜色转换到合适的颜色模型,比如HSV,YUV,Lab 颜色模型等,再套用设计好的算法对特定通道进行调整。一般希望将表征色彩鲜艳程度的分量提取出来进行单独调整,这样调整的时候就不会对明暗造成影响,也不会造成偏色。
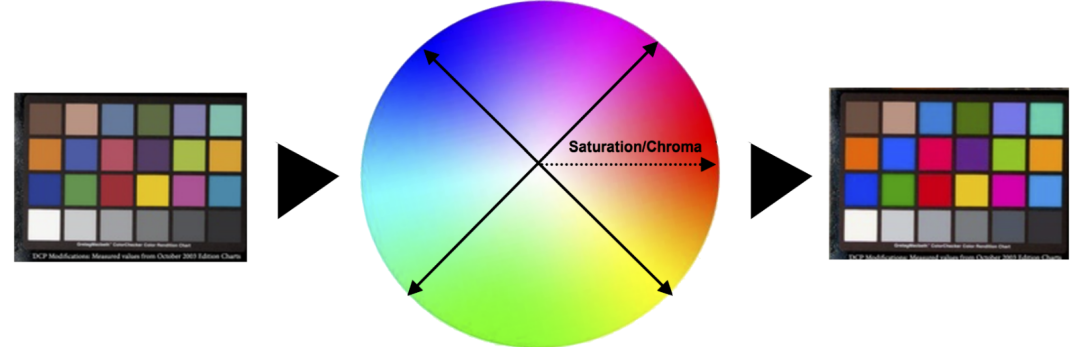
■调整流程示意
除此之外,目前还有使用基于神经网络的方法去做图像增强,由网络自己完成对图像的调整,而不需要由人来设计公式。深度学习的增强方法一般会将色彩,对比度,亮度增强同时实现在一个网络中同时调整,达到画质增强的效果,而其中又分为黑盒方法和白盒方法等。
由于我们色彩增强的工程需求是快速落地,在移动端实现实时、轻量级,并且效果高度可控的算法,同时需要效果与美颜、暗光增强、去噪等模块解耦并相互配合,因此非神经网络的色彩增强方法是更好的选择。
色彩增强方法面临的第一个问题是如何选择合适的颜色模型去进行算法设计。
基于 HSV 颜色模型的饱和度调整
基于 HSV 饱和度的调整方法是将 RGB 颜色模型转换为 HSV 颜色模型,其中 HSV 分别表示(Hue)色相,(Saturation)饱和度和(value)明度。只调整饱和度可以在不影响明暗和色相的情况下增强色彩的鲜艳程度。
常见的调整方法有整体抬升,按比例增加,或者曲线调整,达到将整体饱和度提高的目的。如下图的 gamma 曲线就是比较常用的调整曲线。
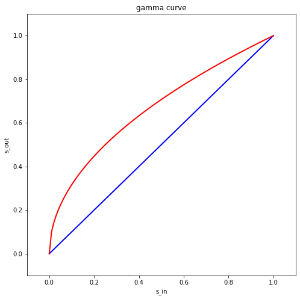
■曲线调整示意图
但是饱和度调整同时提升所有颜色的强度,比较粗暴,有可能导致局部过饱和,局部细节的消失。

■肤色发生了一定的过饱和现象(左:原图 右:增强后)

■调整后衣服皱褶细节丢失(左:原图 右:增强后)
原图来源:HEVC标准测试码流
这对这个问题,自然饱和度(Vibrance)的概念被提出。在调整自然饱和度时,会智能提升画面中比较柔和(即饱和度低)的颜色,而使原本饱和度够的颜色保持原状。
基于自然饱和度的调整
自然饱和度的概念最先由 photoshop 提出,重点在于适应性,自然饱和度调整后一般比饱和度调整要自然。下面分别介绍两种自然饱和度调整的算法。
第一种直接在 RGB 通道上进行统计与调整。其自然饱和度调整的流程是:
1. 计算每个像素 r、g、b 的均值和最大值,分别记为 rgb_avg 以及 rgb_max。
2. 计算 k 值:k = ( abs( rgb_max - rgb_avg ) / 127.0 ) * Vibrance。其中 Vibrance v为调节强度系数,范围为 0~100。
3. 对 r、g、b 分别用同一公式进行调整,以 R 为例,r = (rgb_max - r) * k + r。
该种调节方式可以针对饱和度不同的像素进行不同的调整,能够比较好避免过饱和的情况发生。但是从公式上可以知道,其调整倾向于将 rgb 值往同一个 rgb_max 值进行靠近,可能无法保证颜色保持稳定,不同颜色的调整力度差异较大,会发生偏色的情况。
第二种通过亮度和饱和度进行自适应调节。其自然饱和度的调整流程是:
1. 从 RGB 计算 luma 值:luma = 0.2126 * r + 0.7152 * g + 0.0722 *b。
2. 从 rgb 计算 satuation 值:satuation = max(r ,g, b) - min(r, g, b)。
3. 计算 k 值:k = 1.0 + Vibrance * (1.0 - satuation / 255.0),其中Vibrance为调节强度 0~1。
4. 对 r、g、b 分别用同一公式进行调整,以 r 为例,r = luma * (1.0 - k) + r * k。
同样地,从公式上可以知道,其调整倾向于将 rgb 值往同一个 luma 值进行靠近,也是无法保证颜色保持稳定,会发生偏色的情况。

■基于自然饱和度的增强(左:原图 右:增强后)
从颜色模型上看,基于 RGB、HSV 等颜色空间的颜色调整,对于人的视觉感知是非均匀的,很可能会产生偏色的情况,因此需要一个更合适的颜色模型。Lab 颜色模型是 CIE 在 1976 年改进并且命名的一种色彩模式。它是一种设备无关的颜色模型,也是一种基于生理特征的颜色模型,更适合应用在色彩增强上。
基于 Lab/Lch 颜色模型的调整
Lab 颜色模型由三个要素组成,一个要素是亮度(L),a 和 b 是两个颜色通道。而 Lch 颜色模型采用了同 Lab 一样的颜色空间,但它采用 c 表示饱和度值及 h 表示色调角度。可以认为,ch 是 ab 的极坐标表示方式。由于 Lch 模型是基于生理特征建立的,意味着如果只调节 c 饱和度值的话,就可以起到保证不偏色的效果。
开源图像处理软件 Gimp 的自动色彩增强算法是使用 Lch 颜色模型进行调整的,其处理流程为:
1. 将 RGB 转换到 LCH。
2. 遍历图像像素,找到 C 的最大值 c_max 和最小值 c_min。
3. 对每个像素的 C 进行拉伸:c = (c - c_min) / (c_max - c_min) * 100。
4. 将 LCH 转换回 RGB。

■处理前

■处理后
在 Lch 空间进行调节要比 HSV 上调节科学得多,从实际效果上看,基本上没有出现偏色的情况。不过 Gimp 的方法主要针对的是图片,当用在视频上时,由于存在全局统计,求最大最小值,会增加一定的运算量,同时它会受图像最强点和最弱点的影响较大,若有最强点和最弱点突然离开或进入屏幕,效果可能出现突变,所以这个方法不适用于视频处理。在实际工程化的时候,需要重新设计调整公式,去除对于全局统计点的依赖。
彩色噪声抑制
图像采集的噪声从色彩空间上划分,可以分为 luma noise 亮度噪声与 chroma noise 彩色噪声。色彩增强的应用场景中,比较容易出现的问题是同时把画面中的彩色噪声放大,因此在算法的设计过程中要尽量避免。
同样强度的噪声,在饱和度较低的平坦区域远比在颜色鲜艳的区域看起来要明显。在彩色图像灰色区域中,噪声往往以彩色噪点的形式出现,色彩增强如果不加区分的话,会同时将这些噪点也一并增强,如下图:
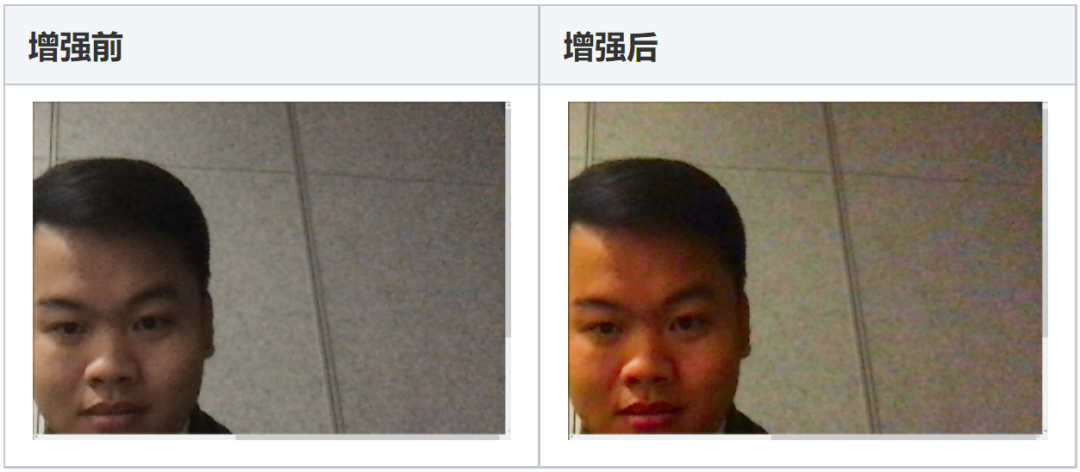
■彩色噪声被增强示意图(左:原图 右:增强后)
针对彩色噪声的统计特性,在工程化的时候,需要进行噪声的判断,并降低色彩增强在这些地方的调整强度。经过噪声抑制之后的效果如下图:

■噪声抑制效果
肤色保护
由于人的肤色存在一个经验合理范围,调整超出这个范围之后就是使得人像看上去不真实。所以在色彩增强的时候,需要对人的肤色进行一定的保护,避免调整过度。要对肤色进行保护,首先要对肤色进行识别,然后对于肤色的部分减弱色彩增强的影响。肤色识别算法大部分是基于某颜色空间下的统计特征,包含大量的经验值。一般主流的有以下的肤色识别方法:
基于 RGB 色彩模型的肤色识别
直接使用 RGB 色彩模型是比较简便的手段,因为一般传入的数据都是 RGB 为主。较为常用的方法是条件判断法,对 RGB 的值进行条件判断,落入经验范围中则判断为肤色。其中分为均匀光照和侧光两种判断条件,实际操作时一般会将这两个判断条件同时使用,只要符合其中一个,即判断为肤色。
除此之外,在 RGB 色彩模型中还可以使用二次多项式模式检测。模型由两个归一化 R-G 平面的二次多项式和一个圆方程构成,只要这三个公式的值落入一定经验范围则判断为肤色。
基于 RGB 的肤色识别方法操作最为简便,一般不需要进行色彩模型的转换。但是由于该色彩没有将亮度和颜色进行分离,判断公式一般都比较烦冗,肤色识别的准确性受光照条件的影响较大。
基于 YCbCr 色彩模型的肤色识别
一般我们听到的 YUV 实际就是指 YCbCr。YCbCr 色彩模型将色彩分解为亮度值 Y 与二维色度值 CbCr,能够只对色度进行判断,避免光照条件的影响。使用 YCbCr 色彩模型,比较直接的肤色识别方法是范围判断法。从 RGB 转换到 YCbCr 之后,对于 CbCr 组成的二维平面,只要落在经验范围之内,都认为是肤色。文献上能查到不同经验范围,一般选择其中一种使用即可,例如 133 <= Cr <= 173,77 <= Cb <= 127。
除了直接判断范围,YCbCr 也可以使用基于椭圆的肤色识别方法。该方法基于经验统计数据,对于 CbCr 组成的二维平面,只要落在椭圆之内,都认为是肤色,准确性比单纯的范围判断更高。这个肤色检测方法被 opencv 所采用。在 opencv 中的椭圆参数为:[113,155.6]为椭圆中心,[23.4,15.6]为长轴和短轴,倾斜角度为 43.0。

■椭圆肤色CbCr区域示意
基于 HSV 色彩模型的肤色识别
HSV 色彩模型也同样将亮度与颜色进行了分离,因此对于光照变化也有很强的抗干扰能力。
基于 HSV 的肤色识别方法常见的有基于高斯模型的方法。这个方法被开源处理库 GPUImage 所采用的。其基本思路为:将 RGB 转换到 HSV 空间,并计算 h 与 skinHue 距离:dist = abs(h – skinHue) / 0.5,其中 skinHue 为高斯模型统计均值,一般使用 0.05。高斯模型方差相关统计参数为 skinHueThreshold,一般取 40。高斯权重通过 exp(-dist * dist * skinHueThreshold)公式求得。这个方法只计算出肤色识别的权重(概率),后面可以通过设置阈值(比如>0.95)来获得肤色检测结果。
另外,基于 HSV 的肤色识别方法也有范围判断法,一般通过文献上提供的 H、S、V 经验范围进行判断,操作比较简单,在此不详细列出。
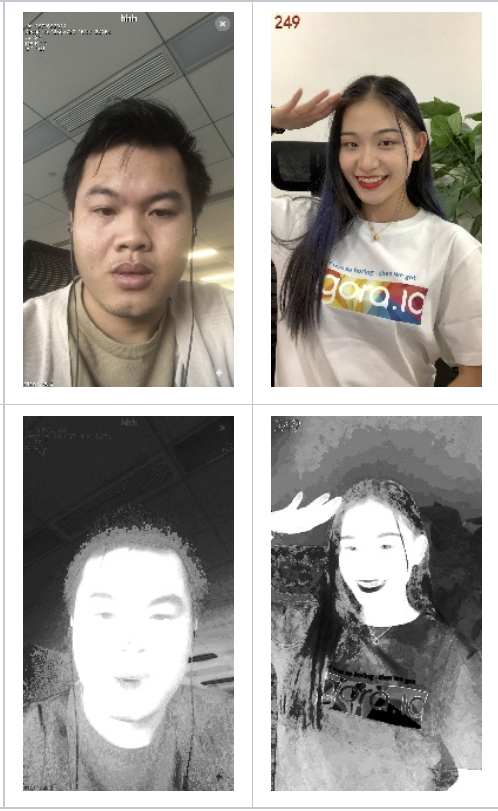
■肤色识别结果示意(上:原图 下:肤色识别结果)

■肤色保护下色彩增强效果
色彩增强算法落地效果
在加入了噪声抑制和肤色保护之后,我们得到了最终的色彩增强算法效果。



■加入噪声抑制和肤色保护之后的色彩增强算法效果(左:原图 右:增强后)
原图来源:HEVC 标准测试码流
总结
总体来说,在我们色彩增强算法的落地过程中,加入了噪声抑制和肤色保护的算法能够在大部分场景下的获得更好的更稳定的效果。不过依然有不少可以改进的方向,例如如何把针对场景和画面特性的适应性做得更好,如何把肤色识别做得更精准等等。另外,目前这里讨论的只是色彩增强,要做到比较好的画质增强,还需要配合对比度亮度的调整,去噪算法,甚至是伪 HDR 算法等,如何通过融合不同的算法输出一个更好的结果,也是一个需要不断迭代研究的课题。
推荐阅读:
觉得不错,点个在看呗~
