
基于对比学习的时间序列异常检测方法

本文约2500字,建议阅读8分钟
本文为你介绍基于对比学习的时间序列异常检测方法!
简介
时间序列异常检测是一项重要的任务,其目标是从时间序列的正常样本分布中识别异常样本。这一任务的最基本挑战在于学习一个能有效识别异常的表示映射。
它在许多领域中都有广泛的应用,例如工业设备状态监测、金融欺诈检测、故障诊断,以及汽车日常监测和维护等。然而,由于时间序列数据的复杂性和多样性,时间序列异常检测仍然是一个具有挑战性的问题。
在以往的时间序列异常检测中,使用最多的方法是基于Reconstruction(重建)的方法,但是在其表示学习可能会因其巨大的异常损失而损害性能。不同的是,对比学习旨在找到一种能明确区分任何实例的表示,这可能为时间序列异常检测带来更自然和有前景的表示。
日前,KDD 2023中,牛津大学与阿里巴巴联合发表的时间序列异常检测工作,提出了一种名为DCdetector的算法用于时间序列异常检测,这是一个多尺度双注意力对比表征学习模型。
DCdetector利用一个新颖的双注意力非对称设计来创建排列环境和纯对比损失,以引导学习过程,从而学习具有优越判别能力的排列不变表示。大量实验表明DCdetector在多个时间序列异常检测基准数据集上实现了不错的成果。本工作的主要贡献如下:
架构:基于对比学习的双分支注意结构,旨在学习排列不变表示差异的学习在正常点和异常点之间。同时,还提出了通道独立补丁来增强时间序列中的局部语义信息。在注意模块中提出了多尺度的算法,以减少补丁过程中的信息丢失。
优化:基于两个分支的相似性,设计了一个有效且鲁棒的损失函数。请注意,该模型是纯对比训练的,没有重建损失,这减少了异常造成的干扰。
性能和证明:DCdetector在6个多变量和一个单变量时间序列异常检测基准数据集上实现了与最先进的方法相媲美或优越的性能。我们还提供了理由讨论来解释我们的模型如何在没有负样本的情况下避免崩溃。

一、时间序列异常检测概述
在本文中,作者介绍了一些与DCdetector相关的工作,包括异常检测和对比学习。
检测时间序列中异常的方法多种多样,包括统计方法、经典机器学习方法和深度学习方法。统计方法包括使用移动平均、指数平滑和自回归综合移动平均(ARIMA)模型。机器学习方法包括聚类算法,如k-均值和基于密度的方法,以及分类算法,如决策树和支持向量机(SVMs)。深度学习方法包括使用自动编码器、变分自动编码器(VAEs)和循环神经网络(RNNs),如长短期记忆(LSTM)网络。最近在时间序列异常检测方面的工作还包括基于生成对抗网络(GANs)的方法和基于深度强化学习(DRL)的方法。一般来说,深度学习方法在识别时间序列中的异常方面更有效。
时间序列异常检测模型大致可以分为两类:有监督和无监督异常检测算法。当异常标签可用或负担得起时,有监督的方法可以表现得更好;在难以获得异常标签的情况下,可以应用无监督异常检测算法。无监督深度学习方法在时间序列异常检测中得到了广泛的研究。
对比表示学习:对比表示学习的目标是学习一个嵌入空间,其中相似的数据样本彼此保持靠近,而不相似的数据样本则相距较远。使用对比设计使两种类型的样本之间的距离更大具有启发意义。我们尝试使用经过精心设计的多尺度拼接注意力模块来区分时间序列异常和正常点。此外,我们的DCdetector也不需要负样本,并且即使没有“stop gradient”也不会失效。

二、基于对比学习的时间序列异常检测方法
在DCdetector中,我们提出了一种具有双注意的对比表示学习结构,从不同的角度获得输入时间序列的表示。双注意对比结构模块在我们的设计中至关重要。它学习了不同视角下输入的表示。
我们的洞察是,对于正常点,它们大多数情况下即使在不同的视角下也会共享相同的潜在模式(强相关性不容易被破坏)。然而,由于异常点很少且没有明确的模式,它们很难与正常点或彼此之间共享潜在模式(即,异常点与其他点之间的相关性较弱)。因此,正常点在不同视角下的表示差异将很小,而异常点的表示差异将很大。我们可以通过一个精心设计的表示差异标准来区分异常点和正常点。至于异常标准,我们基于两种表示之间的差异来计算异常分数,并使用先验阈值进行异常检测。
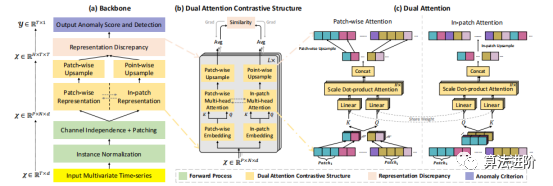
图2:DCdetector框架的工作流程。DCdetector由四个主要模块组成:正向过程模块、双注意对比结构模块、表示差异模块和异常准则模块。

图3:基本补丁注意。将多元时间序列输入中的每个通道被视为一个单一的时间序列,并划分为斑块。每个通道共享相同的自注意网络,表示结果被连接为最终输出。
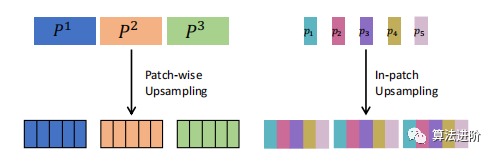
图4:关于如何进行上采样的一个简单示例。对于补丁分支,在补丁中重复(从补丁到点)。对于补丁内分支,从“一个”补丁到全部补丁(从点到补丁)进行重复。
三、实验结果
我们根据各种评估标准将我们的模型与 26 个基线进行比较。实验结果表明,与各种最先进的算法相比,DCdetector在七个基准数据集上实现了最佳或可比的性能。
表1:对真实世界的多变量数据集的总体结果。性能从最低到最高。P、R和f1是精度、查全率和f1分数。(所有的结果都是%的,最好的是粗体的,次之是下划线的。下同)
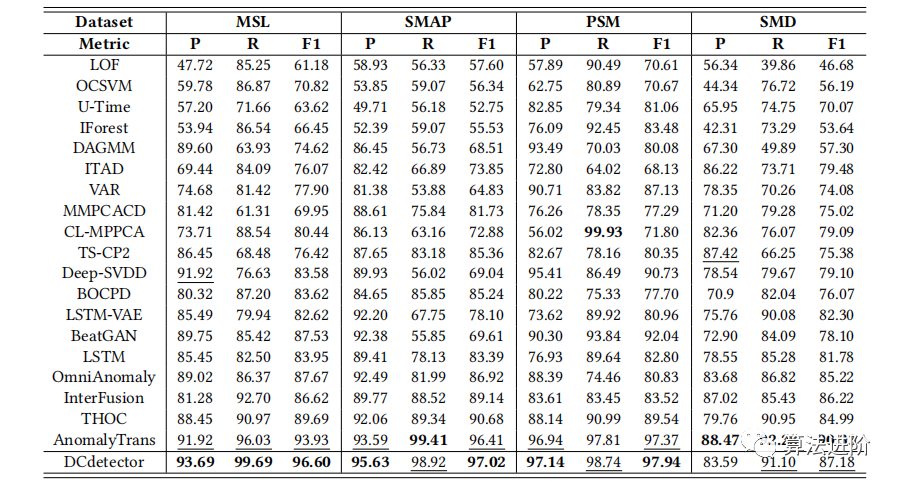
表2:在真实世界的多变量数据集上的多度量结果。Aff-P和Aff-R分别是隶属度度量[31]的精确度和查全率。R_A_R和R_A_P分别为Range-AUC-ROC和Range-AUC-PR [49],分别表示基于ROC曲线和PR曲线下的标签转换的两个分数。V_ROC和V_RR分别是基于ROC曲线和PR曲线[49]创建的表面下的体积。

表3:NIPS-TS数据集的总体结果。性能从最低到最高。
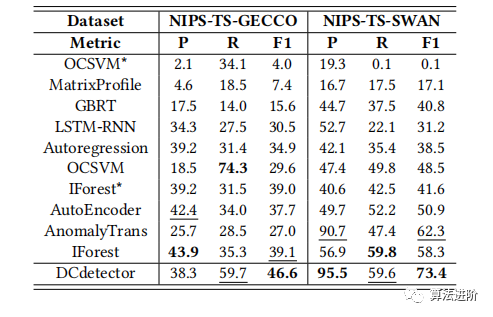
表4:NIPS-TS数据集上的多指标结果。

表5:DCdetector中停止梯度的消融研究。

表6:DC检测器中正向过程模块的消融研究。

表7:单变量数据集的总体结果。
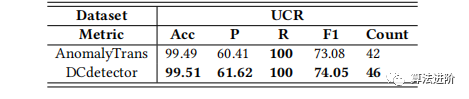
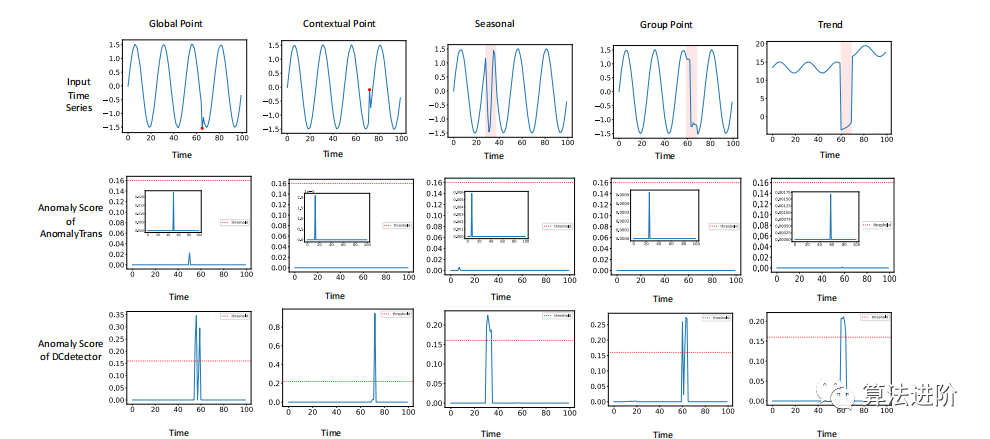
图5:对不同类型异常的DCdetector和异常变压器之间的地面-真实异常和异常得分的可视化比较。

图6:DCdetector中主要超参数的参数灵敏度研究。
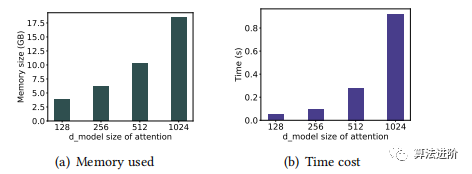
图7:在不同𝑑𝑚𝑜𝑑𝑒𝑙大小的训练期间,平均GPU内存成本和100次迭代的平均运行时间。
四、结论
我们在DCdetector中设计了一个基于对比学习的双注意结构来学习一个排列不变表示。这种表示扩大了正常点和异常点之间的差异,提高了检测精度。此外,还实现了两种设计:多尺度和通道独立补丁,以提高性能。
此外,我们提出了一个无重构误差的纯对比损失函数,并通过经验证明了对比表示与广泛使用的重构表示相比的有效性。最后,大量的实验表明,与各种最先进的算法相比,DCdetector在7个基准数据集上取得了最佳的或可比较的性能。