
全文2500字 详解Pandas与Lambda结合进行高效数据分析
lambda方法以及它在pandas模块当中的运用,熟练掌握可以极大地提高数据分析与挖掘的效率导入模块与读取数据
我们第一步需要导入模块以及数据集
import pandas as pd
df = pd.read_csv("IMDB-Movie-Data.csv")
df.head()
创建新的列
df['AvgRating'] = (df['Rating'] + df['Metascore']/10)/2
lambda方法就很多必要被运用到了,我们先来定义一个函数方法def custom_rating(genre,rating):
if 'Thriller' in genre:
return min(10,rating+1)
elif 'Comedy' in genre:
return max(0,rating-1)
elif 'Drama' in genre:
return max(5, rating-1)
else:
return rating
apply方法和lambda方法将这个自定义的函数应用在这个DataFrame数据集当中df["CustomRating"] = df.apply(lambda x: custom_rating(x['Genre'], x['Rating']), axis = 1)
axis参数的作用,其中axis=1代表跨列而axis=0代表跨行,如下图所示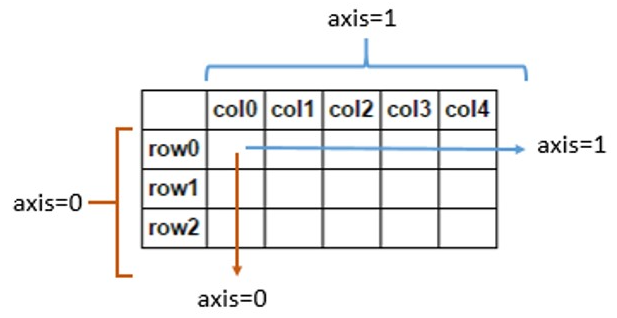
筛选数据
pandas当中筛选数据相对来说比较容易,可以用到& | ~这些操作符,代码如下# 单个条件,评分大于5分的
df_gt_5 = df[df['Rating']>5]
# 多个条件: AND - 同时满足评分高于5分并且投票大于100000的
And_df = df[(df['Rating']>5) & (df['Votes']>100000)]
# 多个条件: OR - 满足评分高于5分或者投票大于100000的
Or_df = df[(df['Rating']>5) | (df['Votes']>100000)]
# 多个条件:NOT - 将满足评分高于5分或者投票大于100000的数据排除掉
Not_df = df[~((df['Rating']>5) | (df['Votes']>100000))]
电影的影名长度大于5的部分,要是也采用上面的方式就会报错df[len(df['Title'].split(" "))>=5]
output
AttributeError: 'Series' object has no attribute 'split'
这里我们还是采用apply和lambda相结合,来实现上面的功能
#创建一个新的列来存储每一影片名的长度
df['num_words_title'] = df.apply(lambda x : len(x['Title'].split(" ")),axis=1)
#筛选出影片名长度大于5的部分
new_df = df[df['num_words_title']>=5]
当然要是大家觉得上面的方法有点繁琐的话,也可以一步到位
new_df = df[df.apply(lambda x : len(x['Title'].split(" "))>=5,axis=1)]
我们先要对每年票房的的平均值做一个归总,代码如下
year_revenue_dict = df.groupby(['Year']).agg({'Revenue(Millions)':np.mean}).to_dict()['Revenue(Millions)']
def bool_provider(revenue, year):
return revenue然后我们通过结合apply方法和lambda方法应用到数据集当中去
new_df = df[df.apply(lambda x : bool_provider(x['Revenue(Millions)'],
x['Year']),axis=1)]
.loc方法,它同时也可以和lambda方法联用,例如我们想要筛选出评分在5-8分之间的电影以及它们的票房,代码如下df.loc[lambda x: (x["Rating"] > 5) & (x["Rating"] < 8)][["Title", "Revenue (Millions)"]]
转变指定列的数据类型
astype方法来实现的,例如我们将“Price”这一列的数据类型转变成整型的数据,代码如下df['Price'].astype('int')
会出现如下所示的报错信息
ValueError: invalid literal for int() with base 10: '12,000'
astype方法实现数据类型转换就会报错,因此我们还需要将到apply和lambda结合进行数据的清洗,代码如下df['Price'] = df.apply(lambda x: int(x['Price'].replace(',', '')),axis=1)
方法调用过程的可视化
这里用到的是tqdm模块,我们将其导入进来
from tqdm import tqdm, tqdm_notebook
tqdm_notebook().pandas()
然后将apply方法替换成progress_apply即可,代码如下
df["CustomRating"] = df.progress_apply(lambda x: custom_rating(x['Genre'],x['Rating']),axis=1)
output

当lambda方法遇到if-else
当然我们也可以将if-else运用在lambda自定义函数当中,代码如下
Bigger = lambda x, y : x if(x > y) else y
Bigger(2, 10)
output
10
if-else,这样写起来就有点麻烦了,代码如下df['Rating'].apply(lambda x:"低分电影" if x < 3 else ("中等电影" if x>=3 and x < 5 else("高分电影" if x>=8 else "值得观看")))
apply和lambda方法搭配使用
各位伙伴们好,詹帅本帅搭建了一个个人博客和小程序,汇集各种干货和资源,也方便大家阅读,感兴趣的小伙伴请移步小程序体验一下哦!(欢迎提建议)
推荐阅读
推荐阅读
评论