
【深度学习】Transformer 向轻量型迈进!微软与中科院提出两路并行的 Mobile-Former
导读
本文创造性的将MobileNet与Transformer进行了两路并行设计,穿插着全局与特征的双向融合,同时利用卷积与Transformer两者的优势达到“取长补短”的目的。

已有的Transformer对标的CNN主要是ResNet系列,鲜少有对标端侧轻量模型的Transformer。本文则从轻量模型角度出发,在MobileNet与Transformer组合方面进行了探索,它创造性的将MobileNet与Transformer进行了两路并行设计,穿插着全局与特征的双向融合,同时利用卷积与Transformer两者的优势达到“取长补短”的目的。此外,受益于超轻量设计,所提Mobile-Former不仅计算高效,同时具有更强的表达能力。在ImageNet分类与COCO目标检测方面,所提Mobile-Former取得了显著优于MobileNetV3的性能。
Abstract
本文提出了一种新颖的Mobile-Former,它采用了MobileNet与Transformer两路并行设计机制,该架构充分利用了MobileNet的局部处理优势与Transformer的全局交互能力。Transformer与MobileNet的双向桥接促进了全局特征与局部特征的双向融合。
不同于现有的Vision Transformer,Mobile-Former中的Transformer包含非常少的(比如少于6个)、随机初始化tokens,进而产生了非常低的计算复杂度。结合所提轻量注意力,Mobile-Former不仅计算高效,同时具有更强的表达能力。在ImageNet分类任务上,从25M到500M Flops复杂度下,所提方案均取得了优于MobileNetV3的性能。比如,它凭借294MFlops计算量取得了比MobileNetV3高1.3%的top1精度且计算量节省17%;当迁移到目标检测时,Mobile-Former取得了比MobileNetV3高8.6AP的指标。
Method
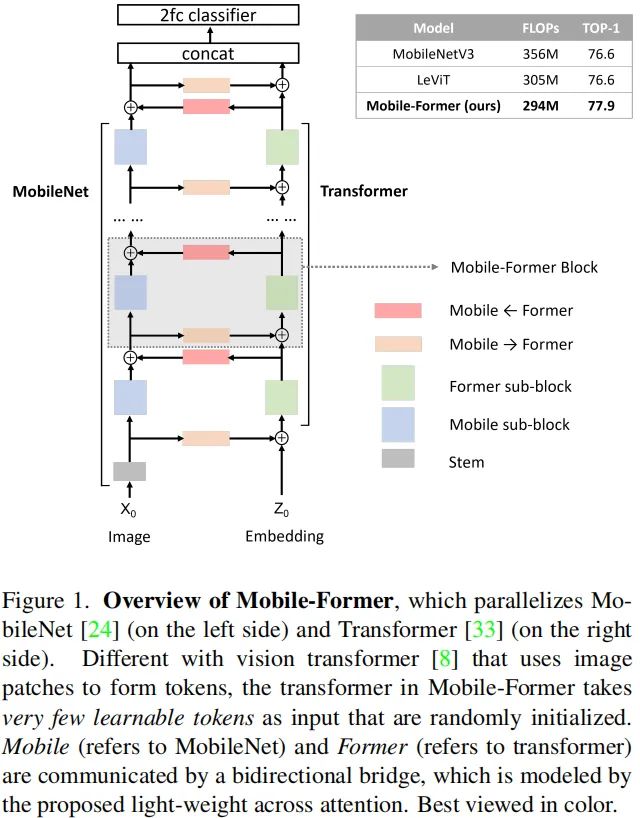
上图给出了本文所提Mobile-Former整体架构示意图,MobileNet与Transformer之间通过双向注意力进行桥接。其中,Mobile以输入图像作为输入,并采用IBB(Inverted Bottleneck Block)提取局部特征;Former则以可学习参数(即tokens)作为输入,值得注意的是,这里的tokens采用了随机初始化方式而非已有ViT中的PatchEmbedding。这种处理机制可以有效的降低token的数量。
Mobile与Former之间通过双向桥连接以进行局部、全局特征融合。我们采用表示桥的两个方向,我们提出了一种轻量注意力机制模拟该双向桥。
Low Cost Two-Way Bridge
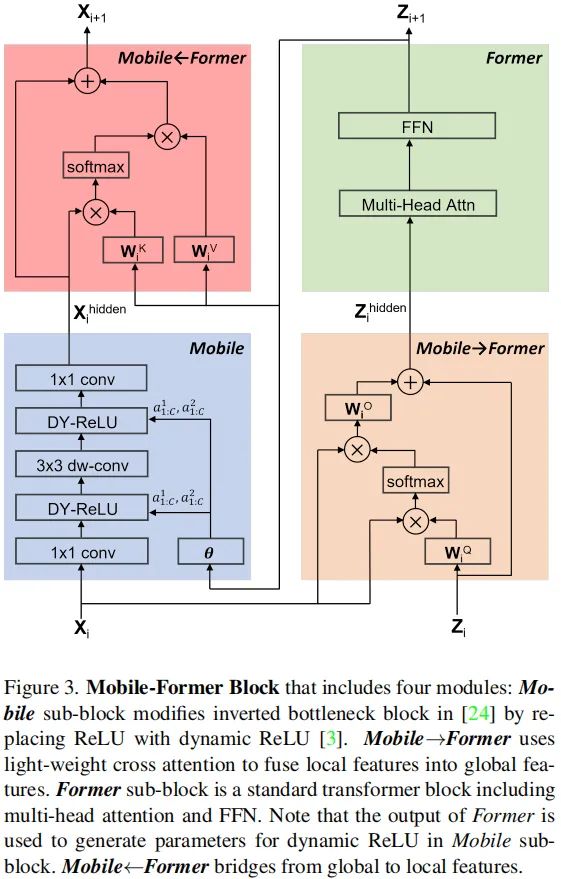
我们利用Cross Attention(交叉注意力)进行局部特征与全局token的信息融合。在标准交叉注意力的基础上引入以下两个改进以降低计算量:
在Mobile的低通道部分计算交叉注意力; 当位置数量比较,移除Mobile端的投影,而保持Former端不变;
假设局部特征为,全局token为,那么局部到全局轻量交叉注意力定义如下:
注:在这里,全局特征z为query,局部特征x为key与value。该过程可参见上图的。
类似地,全局到局部地交叉注意力(参见上图)定义如下:
Mobile-Former Block
由前面的Figure1可以看到,所提模型可以解耦为多个Mobile-Former模块的堆叠,每个模块包含一个Mobile子模块、一个Former子模块以及双向桥接。更具体详见上述Figure3.
Input and Output Mobile-Former模块包含两个输入:(1) 局部特征;(2) 全局tokens 。该模块将输出更新后的局部特征与全局tokens 并作为下一个模块的输入。
Mobile sub-block 该子模块以特征作为输入,它在原始的IBB基础上进行了轻微改动:将ReLU替换为DReLU(Dynamic ReLU)。该子模块的输出表示,它将用作的输入。
Former sub-block 它是一个标准多头Transformer模块,为节省节省量将FFN中的扩展比例从4调整为2。需要注意:Former子模块在两路交叉注意力之间进行处理,计算复杂度为 ,第一项为query与key之间的点乘;而第二项则覆盖线性投影与FFN。由于tokens数量非常少,故第一项可以忽略不记。
所提轻量交叉注意力用于将局部特征融合到全局token。相比标准注意力,为节省计算量,移除了投影矩阵,其计算复杂度为。
在这里,交叉注意力用于将全局token融合到局部特征。由于局部特征为query,全局特征为key、value。因此,这里保留了投影矩阵而移除了投影矩阵。其计算复杂度为。
Computational Complexity Mobile-Former模块的四部分具有不同的计算复杂度,其中Mobile子模块共享了最多的计算复杂度,而Former子模块与两路桥接贡献了不到20%的计算复杂度。
Network Specification
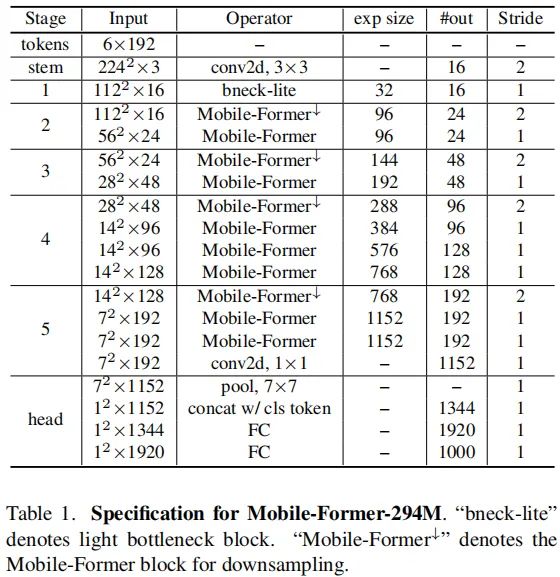
上表给出了所提Mobile-Former的网络架构示意图,它由11个不同输入分辨率的Mobile-Former模块构成,所有Mobile-Former均具有6个维度为192的全局token。stem由卷积+轻量bottleneck构成,分类头则采用以局部特征全局均值池化与全局token的首个元素拼接作为输入并通过两个全连接层预测。
Downsample Mobile-Former Block 注意到stage2-5均具有一个下采样版本的Mobile-Former模块。在Mobile-Former模块中的Mobile子模块从三个层(pointwise->depthwise->pointwise)调整为四层(depthwise->pointwise->depthwise->pointwise),其中第一个depthwise用于降低特征分辨率。
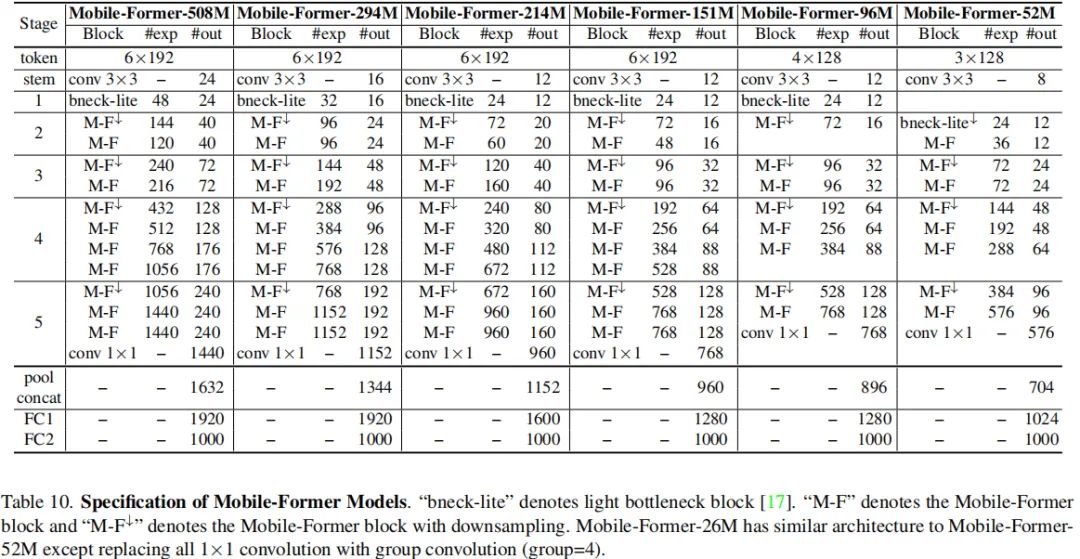
Mobile-Former 变种 按照计算复杂度,Mobile-Former具有7个不同计算量的模型,详细信息见下表(注:26M计算量的模型与52M的模型结构类似,区别在于将所有卷积替换为g=4的组卷积)。
Experiments
接下来,我们从ImageNet分类与COCO目标检测两个方面对所提方案进行性能验证。
ImageNet Classification
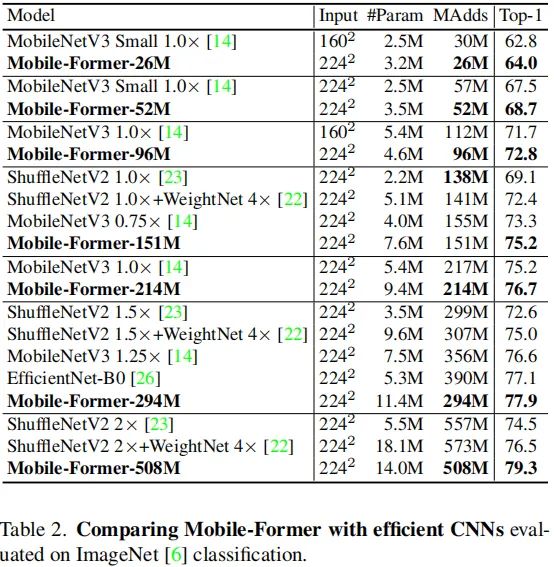
上表对比了MobileNetV3、EfficientNet、ShuffleNetV2、WeightNet与所提方案的性能对比,从中可以看到:在相近计算量下,所提方案具有更少的计算量、更高的性能。这说明:该并行设计机制可以有效的提升特征表达能力。
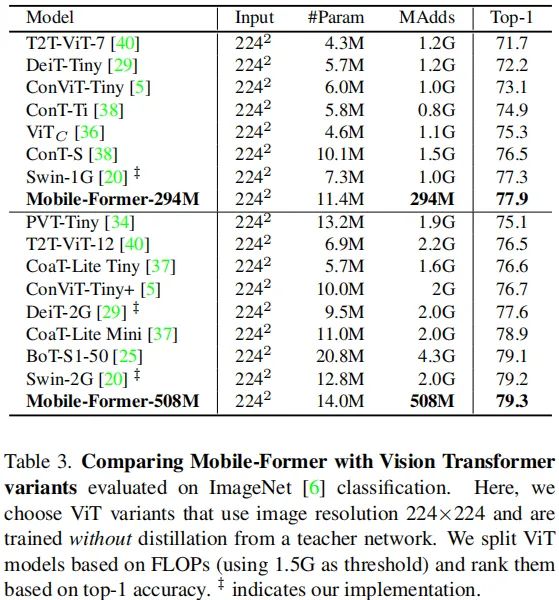
上表对比了所提方案与DeiT、T2T-ViT、PVT、ConViT、CoaT以及Swin的性能,从中可以看到:所提方案取得了更佳的性能,同时具有更少的计算量(少3-4倍)。
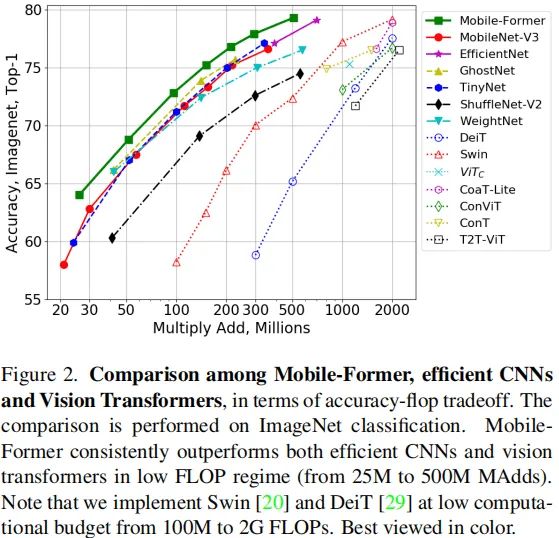
上表比较不同轻量型模型的计算量-性能对比图,可以看到:Mobile-Former取得了显著优于其他CNN与ViT的性能-精度均衡。
Object Detection
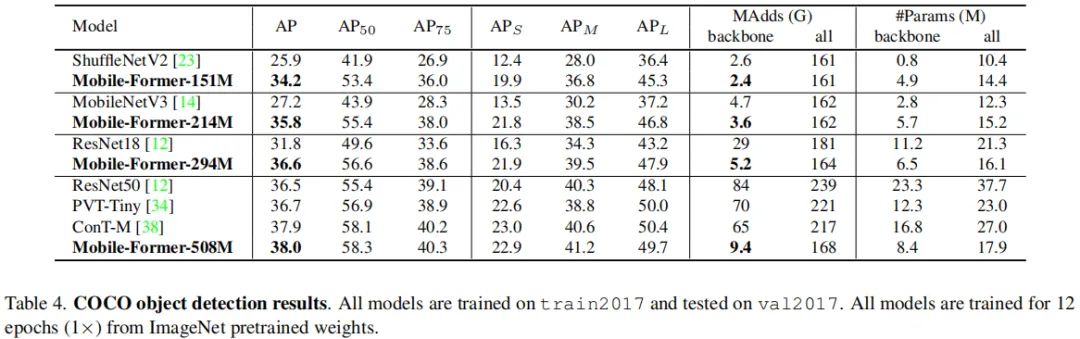
上表对比了COCO目标检测任务上的性能对比,从中可以看到:
在相近计算复杂度下,所提方案以8.3+AP指标优于MobileNetV3与ShuffleNet; 相比ResNet与ViT,所提方案取得了更高的AP指标、同时具有更低的FLOPs。具体来说,Mobile-Former-508M取得了比ResNet50更高的性能,同时计算量低7倍。
Ablation and Discussion
接下来,我们对所提Mobile-Former进行更深入的分析与讨论,这里以Mobile-Former-294M作为基线。
Mobile-Former is Effective
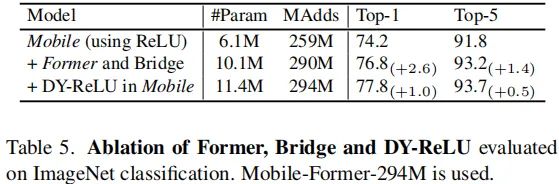
从上表可以看到:
相比Mobile,Former与Bridge仅占用10.6%计算复杂度,但带来了2.6%的性能提升; 采用DY-ReLU可以带来额外的1%性能提升。
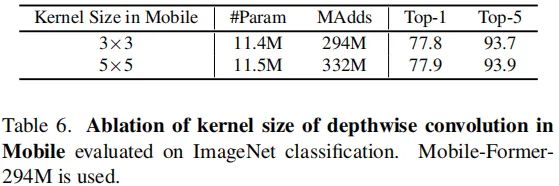
上表对比了Mobile的卷积核尺寸的性能影响,可以看到:提升卷积核尺寸带来的性能提升可以忽略。
Mobile-Former is Efficient
Mobile-Former不仅能够有效的编码局部特征与全局信息,同时计算高效,关键在于:Former仅需非常少的全局tokens。
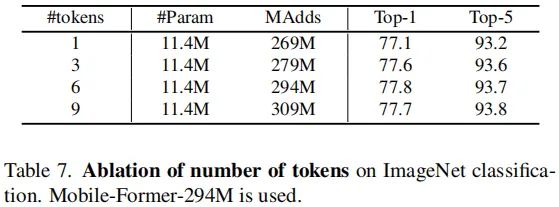
Number of tokens in Former 上表对比了不同数量token时模型性能可以看到:甚至仅需一个全局token仍可取得非常好的性能(77.7%),当采用了3个与6个token时,模型性能提升分别为0.5%、0.7%。这表明:紧致的全局token对于Mobile-Former的高效性非常重要。
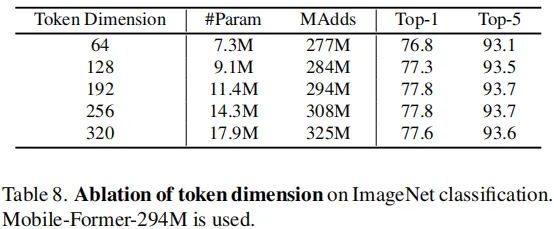
Token dimension 上表对比不同token维度的模型性能对比,从中可以看到:当维度从64提升到192过程中,性能从76.8%提升到了77.8%,此后性能收敛。当token数量为6,维度为192时,Former与Bridge的总计计算量仅占总体计算量的12%。
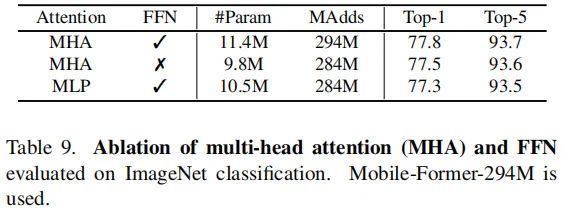
FFN in Former 从上表可以看到:移除FFN会带来0.3%的性能下降。这说明:FFN在Mobile-Former中的重要性很有限。这是因为:FFN并非Mobile-Former中仅有的通道融合模块。
Multi-head Attention via MLP 从上表可以看到:MLP替换MHA会导致0.5%的性能下降。相比MHA,MLP的计算更高效,但它是一种静态操作,不会根据输入自适应调整。
Limitations
Mobile-Former的主要局限在于模型大小,原因有如下两个:
并行设计对于参数共享不够高效,合适因为Mobile、Former以及Bridge均有各自的参数。尽管Former由于token数量少而计算高效,但并不会节省参数量; Mobile-Former的分类头有过多参数量,比例高达40%。当从图像分类任务切换到目标检测任务后(分类头会被移除),该问题可以得到缓解。
本文亮点总结
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# 极市平台签约作者#

happy
知乎:AIWalker
AIWalker运营、CV领域八年深耕码农
研究领域:专注low-level领域,同时对CNN、Transformer、MLP等前沿网络架构保持学习心态,对detection的落地应用甚感兴趣。
公众号:AIWalker
作品精选
