
PPLCNet:CPU端强悍担当,吊打现有主流轻量型网络,百度提出CPU端的最强轻量型架构

极市导读
本文是百度团队结合Intel-CPU端侧推理特性而设计的轻量高性能网络PP-LCNet,所提方案在图像分类任务上取得了比ShuffleNetV2、MobileNetV2、MobileNetV3以及GhostNet更优的延迟-精度均衡。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

arXiv:https://arxiv.org/pdf/2109.15099.pdf
code: https://github.com/PaddlePaddle/PaddleClas
前有阿里团队针对Nvidia-GPU端加速而设计的高推理速度高性能的GENet,现有百度团队针对Intel-CPU端加速而设计的高推理速度&高性能的LCNet。本文是百度团队结合Intel-CPU端侧推理特性而设计的轻量高性能网络PP-LCNet,所提方案在图像分类任务上取得了比ShuffleNetV2、MobileNetV2、MobileNetV3以及GhostNet更优的延迟-精度均衡。
Abstract
本文提出一种基于MKLDNN加速的轻量CPU模型PP-LCNet,它在多个任务上改善了轻量型模型的性能。本文列举了一些可以提升模型精度且保持延迟几乎不变的技术,基于这些改进,所提PP-LCNet可以凭借同等推理速度大幅超过其他已有网络。
如下图所示,在图像分类任务方面,所提PP-LCNet在推理延迟-精度均衡方面大幅优于ShuffleNetV2、MobileNetV2、MobileNetV3以及GhostNet;在其他下游任务(如目标检测、语义分割等),所提方案同样表现优异。
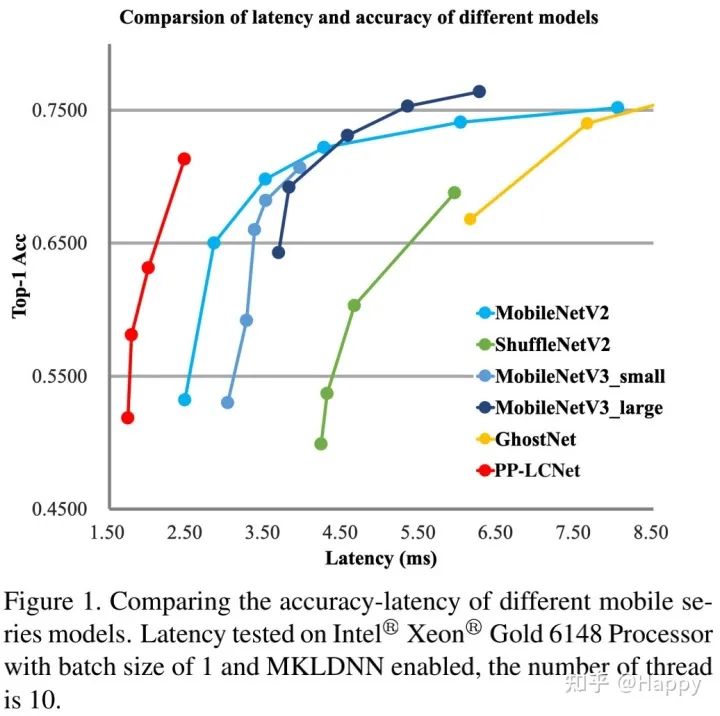
Method
尽管已有不少轻量型网络可以在ARM端具有非常快的推理速度,但鲜少有网络考虑Intel CPU端的推理速度,尤其当启动MKLDNN加速时。有不少可以在ARM端提升模型精度且保持推理延迟几乎不变的方法,但这些方法切换到Intel CPU端就会出现一些差异。
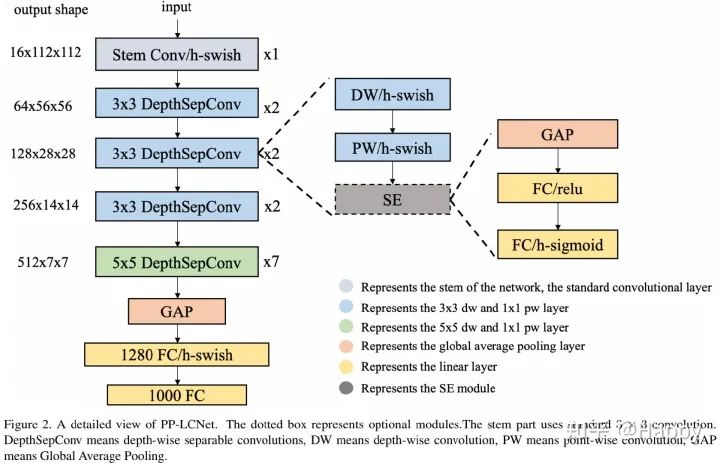
在这里,我们总结了一些可以提升模型性能且几乎不会造成推理延迟的方法。我们以MobileNetV1中的DepthSepConv作为基础模块,即没有跳过连接,也就没有concat或者add操作(这些操作不仅会降低模型的推理速度,而且在小模型上不会提升,模型精度);此外,由于这些操作已被Intel CPU的加速库MKLDNN进行深度优化,推理速度优于其他轻量型模块。我们通过堆叠模块构建了一个类似MobileNetV1的BaseNet,然后组合BaseNet与某些现有技术构建了一种更强力网络PP-LCNet,见下图(注:带SE模块的图示好像有点问题,跟code对不上。code中的实现方式为DW-SE-PW)。
Better activation function
众所周知,激活函数的质量决定了模型的性能。激活函数从早期的Sigmoid转换到了ReLU后,模型的性能得到了显著提升。近年来,深度学习领域也提出各种更优秀的激活函数,而Swish系列则是其中的佼佼者,尤以H-Swish为最优。
本文同样采用H-Swish替换BaseNet中的ReLU,性能大幅提升,而推理速度几乎不变。
SE modules at appropriate positions
自提出以来,SE就被广泛应用到不用网络架构中,比如MobileNetV3。然而,在Intel CPU端,SE模块会提升模型的推理耗时,故我们不能对整个网络使用它。
事实上,我们做了大量的实验并发现:当把SE置于模型的尾部时,它具有更好作用 。因此,我们仅将SE模块添加到接近网络尾部的模块 ,这种处理方式具有更好的精度-速度平衡。注:SE模块采用了与MobileNetV3相似的机制:SE中的两个激活函数分别为SE和H-Sigmoid。
Larger convolution kernels
卷积核的尺寸通常会影响模型最终的性能,MixNet的作者分析了不同尺寸卷积对于网络性能的影响并提出了已中混合不同尺寸的卷积核,然而这种操作会降低模型的推理速度。我们尝试仅使用一个尺寸的卷积,并在低延迟&高精度情形下使用大尺度卷积核。
我们实验发现:类似SE模块的位置,在网络的尾部采用卷积核可以取得全部替换相近的效果。因此,我们仅在网络的尾部采用 卷积 。
Larger dimensional conv layer after GAP
在本文所提PP-LCNet中,GAP后的输出维度比较小,直接添加分类层会有相对低的性能。为提升模型的强拟合能能力,我们在GAP后添加了一个1280维的卷积,它仅需很小的推理延迟即可取得更强的性能。
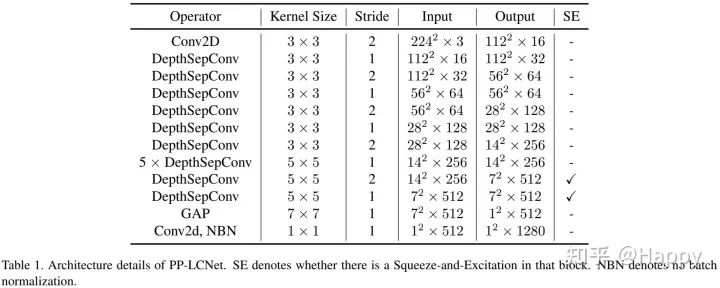
最后,上表给出了结合上述改进后的PP-LCNet的网络架构参数信息。
Experiments
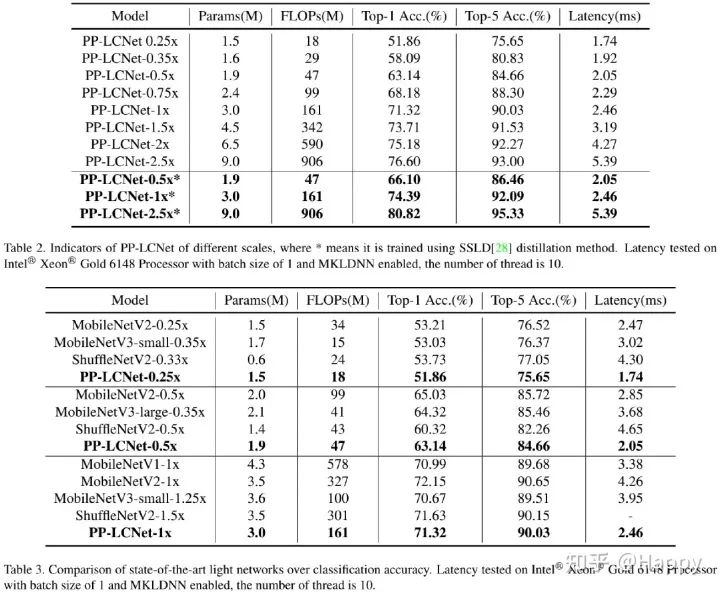
上表2和3给出了所提方案在ImageNet数据集上的性能以及与其他知名模型的性能对比,从中可以看到:
引入SSLD知识蒸馏方案,模型的精度可以进一步提升; 相比其他轻量型模型,所提PP-LCNet具有更强的速度-精度均衡。
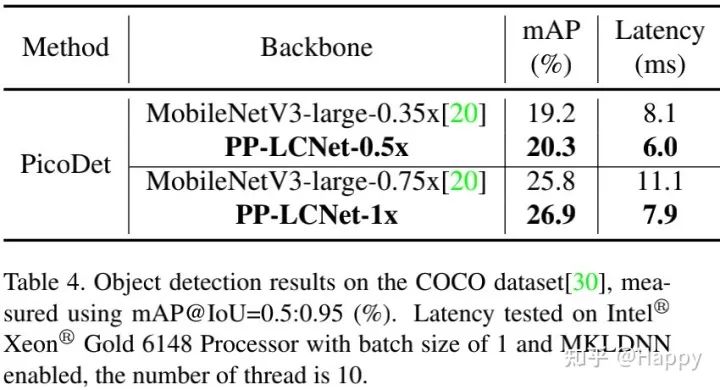
上表给出了COCO目标检测任务上的性能对比,可以看到:相比MobileNetV3,所提PP-LCNet具有更好的性能、更低的推理延迟 。
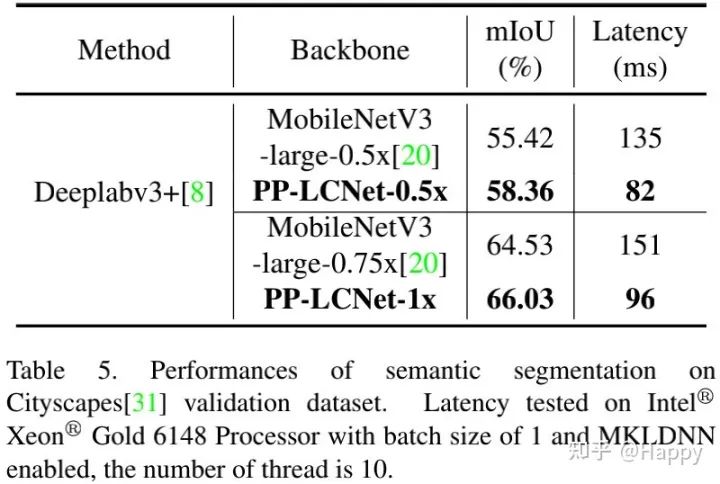
上表给出了Cityscapes语义分割任务上的性能对比,可以看到:相比MobileNetV3,所提PP-LCNet具有更好的性能、更低的推理延迟 。
Ablation Study
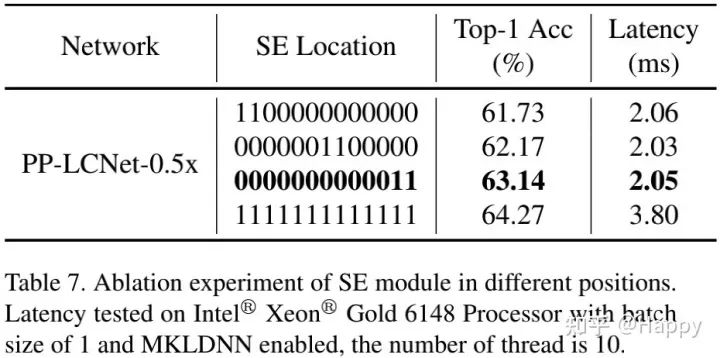
上表对比了SE的位置对于模型性能影响,可以看到:SE在模型的尾部时具有更重要的影响。为更好平衡推理-精度,PP-LCNet仅在尾部两个模块添加SE模块。

上表比较了不同位置大尺寸卷积对于性能的影响,可以看到:在模型的尾部使用卷积更具竞争力。因此,我们选用了表中第三行的配置。

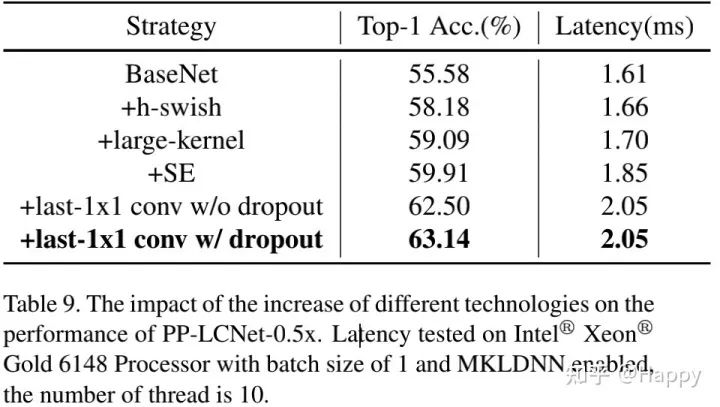
上表6与9对比了不同模块移除对于PP-LCNet的性能影响,可以看到:
H-Swish与大卷积核可以提升模型性能且几乎不会造成推理耗时提升; 添加少量的SE更进一步提升模型性能; GAP后采用更大FC层可以极大提升模型性能; dropout技术可以进一步提升了模型的精度。
代码片段
其实PPLCNet的实现还是比较简单的,没什么复杂东西,这就直接给出DepthwiseSeparable这个模块的实现(摘自PaddleClas),PaddlePaddle的动态图机制跟Pytorch非常相似,所以参考这个代码就可以非常容易的写出pytorch版的。
class DepthwiseSeparable(TheseusLayer):
def __init__(self,
num_channels,
num_filters,
stride,
dw_size=3,
use_se=False):
super().__init__()
self.use_se = use_se
self.dw_conv = ConvBNLayer(
num_channels=num_channels,
num_filters=num_channels,
filter_size=dw_size,
stride=stride,
num_groups=num_channels)
if use_se:
self.se = SEModule(num_channels)
self.pw_conv = ConvBNLayer(
num_channels=num_channels,
filter_size=1,
num_filters=num_filters,
stride=1)
def forward(self, x):
x = self.dw_conv(x)
if self.use_se:
x = self.se(x)
x = self.pw_conv(x)
return x
如果不想训练,只是 想测试一下速度和性能,还可以考虑直接把预训练模型直接导入到Pytorch中,这个也是非常简单,感兴趣的同学可以后台留言PPLCNet获取下载链接。
笔者把PPLCNet这个转换成ONNX形式共享呢,结果发现:ONNX不支持HardSwish算子,转换成了复杂的结构,见下图红框部分。此外,尽管ONNX支持hardsigmoid,但是pytorch自身的onnx问题模型导出失败(据说最新版的已经支持了,笔者用的是1.8版本的没有转换成功,有时间更新下torch版本再试试);而paddle版本则可以正常导出。

个人反思
这篇文章很短,短到只需不超过10分钟就能轻松的理解到该结构。但同时,值得深思:自从ResNet以来,无论是轻量型还是高性能网络均重度依赖跳过连接、残差连接这种机制。反而像MobileNetV1这种非常简单模型的性能提升鲜少有学者进行深入研究。虽然RepVVGG在推理阶段类似,但训练阶段仍用到了残差连接。
其实,全文看下来,这篇文章是看不到创新的,但是工程性的梳理太令人钦佩了。在这样一个“每天都有几十篇AI相关paper”的时代,能这样静下来去深挖这些被忽视的细节并精心整理出来真是太不容易了。笔者也成尝试去做类似的工作(反正我是没能力发paper),其中艰辛谁做谁知道...
个人非常喜欢这类深挖细节的文章,虽然创新不多,但非常能体验工程能力与技术深度。但是这类文章太少了,一季度不一定能超过两篇,非常期待更多类似的paper发出来。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
