
synchronized的实现原理是啥?
点击上方蓝色字体,选择“标星公众号”
优质文章,第一时间送达
作者 | 夜勿语
来源 | urlify.cn/MvYZZj
前言
上一篇分析了优化后的synchronized在不同场景下对象头中的表现形式,还记得那个结论吗?当一个线程第一次获取锁后再去拿锁就是偏向锁,如果有别的线程和当前线程交替执行就膨胀为轻量级锁,如果发生竞争就会膨胀为重量级锁。这句话看起来很简单,但实际上synhronized的膨胀过程是非常复杂的,有许多场景和细节需要考虑,本篇就对其进行详细分析。
正文
先来看一个案例代码:
public class TestInflate {
static Thread t2;
static Thread t3;
static Thread t1;
static int loopFlag = 19;
public static void main(String[] args) throws InterruptedException {
//a 没有线程偏向---匿名 101偏向锁
List list = new ArrayList<>();
t1 = new Thread() {
@Override
public void run() {
for (int i = 0; i < loopFlag; i++) {
A a = new A();
list.add(a);
synchronized (a) {
log.debug(i + " " + ClassLayout.parseInstance(a).toPrintableTest(a));
}
}
log.debug("========t2=================");
LockSupport.unpark(t2);
}
};
t2 = new Thread() {
@Override
public void run() {
LockSupport.park();
for (int i = 0; i < loopFlag; i++) {
A a = list.get(i);
log.debug(i + " " + ClassLayout.parseInstance(a).toPrintable(a));
synchronized (a) {
log.debug(i + " " + ClassLayout.parseInstance(a).toPrintable(a));
}
log.debug(i + " " + ClassLayout.parseInstance(a).toPrintable(a));
}
log.debug("======t3=====================================");
LockSupport.unpark(t3);
}
};
t3 = new Thread() {
@Override
public void run() {
LockSupport.park();
for (int i = 0; i < loopFlag; i++) {
A a = list.get(i);
log.debug(i + " " + ClassLayout.parseInstance(a).toPrintable(a));
synchronized (a) {
log.debug(i + " " + ClassLayout.parseInstance(a).toPrintable(a));
}
log.debug(i + " " + ClassLayout.parseInstance(a).toPrintable(a));
}
}
};
t1.start();
t2.start();
t3.start();
t3.join();
log.debug(ClassLayout.parseInstance(new A()).toPrintable());
}
这里创建了三个线程t1、t2、t3,在t1中创建了loopFlag个对象并依次加锁,然后放入到list中,t2等待t1执行完成后依次读取list中对象进行加锁并打印加锁前、加锁后、解锁后的对象头,t3和t2相同,只不过需要等待t2执行完才开始执行,最后等三个线程执行完成后再新建一个对象并打印对象头(注意运行该代码需要关闭偏向延迟-XX:BiasedLockingStartupDelay=0)。
偏向锁
偏向锁没什么好演示的,但是在源码中获取偏向锁是第一步,且逻辑比较多,有以下几点需要注意:
是否已经超过偏向延迟指定的时间,若没有,则只能获取轻量锁
是否允许偏向
如果只有当前线程且是第一次则直接获取偏向锁(使用class对象中的mark word和线程id做"或"操作,得到一个新的header,并通过CAS替换锁对象头,替换成功则获取到偏向锁,否则进入锁升级的流程)
是否调用了锁对象未重写的hashcode(对应源码中的Object#hash或System.identityHashCode()方法),hashcode会占用对象头的空间,导致无法偏向
线程是否交替执行(即当前线程ID和对象头中的线程ID不一致),若是交替执行可能获取到偏向锁、轻量锁,细节下文详细讲述。
轻量锁
首先注释掉t3,先设置loopFlag=19运行t1和t2,你能猜到打印的对象头是什么样的么?(为节省篇幅,下文对象头都只截取最后8位展示)
15:57:38.579 [Thread-0] DEBUG cn.dark.ex6.TestInflate - 0 00000101
15:57:38.580 [Thread-0] DEBUG cn.dark.ex6.TestInflate - 1 00000101
......
15:57:38.582 [Thread-0] DEBUG cn.dark.ex6.TestInflate - 17 00000101
15:57:38.582 [Thread-0] DEBUG cn.dark.ex6.TestInflate - 18 00000101
15:57:38.582 [Thread-0] DEBUG cn.dark.ex6.TestInflate - ========t2=================
15:57:38.582 [Thread-1] DEBUG cn.dark.ex6.TestInflate - 0 00000101
15:57:38.583 [Thread-1] DEBUG cn.dark.ex6.TestInflate - 0 10000000
15:57:38.583 [Thread-1] DEBUG cn.dark.ex6.TestInflate - 0 00000001
15:57:38.583 [Thread-1] DEBUG cn.dark.ex6.TestInflate - 1 00000101
15:57:38.583 [Thread-1] DEBUG cn.dark.ex6.TestInflate - 1 10000000
15:57:38.583 [Thread-1] DEBUG cn.dark.ex6.TestInflate - 1 00000001
......
15:57:38.589 [Thread-1] DEBUG cn.dark.ex6.TestInflate - 17 00000101
15:57:38.589 [Thread-1] DEBUG cn.dark.ex6.TestInflate - 17 10000000
15:57:38.589 [Thread-1] DEBUG cn.dark.ex6.TestInflate - 17 00000001
15:57:38.589 [Thread-1] DEBUG cn.dark.ex6.TestInflate - 18 00000101
15:57:38.590 [Thread-1] DEBUG cn.dark.ex6.TestInflate - 18 10000000
15:57:38.590 [Thread-1] DEBUG cn.dark.ex6.TestInflate - 18 00000001
15:57:38.590 [Thread-1] DEBUG cn.dark.ex6.TestInflate - ======t3=====================================
15:57:38.590 [main] DEBUG cn.dark.ex6.TestInflate - cn.dark.entity.A object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 05 00 00 00 (00000101 00000000 00000000 00000000) (5)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 2c 6a 01 f8 (00101100 01101010 00000001 11111000) (-134125012)
12 4 (loss due to the next object alignment)
t1线程不用想,肯定都是101,因为拿到的是偏向锁,但是t2就和我上一篇说的有点不一样了。t2加锁前的状态和t1解锁后是一样的,偏向锁解锁不会改变对象头,接着对其加锁,判断当前线程id和对象头中的线程id是否相同,由于不相同所以会做偏向撤销(即将状态修改为001无锁状态)并膨胀为轻量锁(实际上对象第一次加锁时,也有这个判断,接着会判断是不是匿名偏向,即是不是可偏向模式且第一次加锁,是则直接获取偏向锁),状态改为00。
需要注意轻量锁加锁前会在当前线程栈帧中创建一个无锁的Lock Record,加锁时就会使用CAS操作判断当前对象头中的mark word是否和lr中的displaced word相等,由于都是001所以能加锁成功,之后轻量锁解锁只需要将lr中的dr恢复到当前对象头中(001),这样下一个线程才能对该对象再次加锁。需要注意虽然轻量锁解锁后对象头是001状态,但新建的对象依然是默认的101可偏向无锁状态,正如上面最后一次打印。
批量重偏向
上面创建的19个对象在膨胀为轻量锁的时候都会进行偏向撤销,但是撤销是有性能损耗的,所以JVM设置了一个阈值,当撤销达到20次的时候就会进行批量重偏向,该阈值可通过-XX:BiasedLockingBulkRebiasThreshold=20修改。
将上面代码中的loopFlag改为大于19的数打印结果(后面都不再展示t1线程的打印结果):
16:52:02.005 [Thread-0] DEBUG cn.dark.ex6.TestInflate - ========t2=================
16:52:02.005 [Thread-1] DEBUG cn.dark.ex6.TestInflate - 0 00000101
16:52:02.005 [Thread-1] DEBUG cn.dark.ex6.TestInflate - 0 00110000
16:52:02.005 [Thread-1] DEBUG cn.dark.ex6.TestInflate - 0 00000001
......
16:52:02.011 [Thread-1] DEBUG cn.dark.ex6.TestInflate - 18 00000101
16:52:02.012 [Thread-1] DEBUG cn.dark.ex6.TestInflate - 18 00110000
16:52:02.012 [Thread-1] DEBUG cn.dark.ex6.TestInflate - 18 00000001
16:52:02.012 [Thread-1] DEBUG cn.dark.ex6.TestInflate - 19 00000101
16:52:02.012 [Thread-1] DEBUG cn.dark.ex6.TestInflate - 19 00000101
16:52:02.012 [Thread-1] DEBUG cn.dark.ex6.TestInflate - 19 00000101
16:52:02.012 [Thread-1] DEBUG cn.dark.ex6.TestInflate - 20 00000101
16:52:02.012 [Thread-1] DEBUG cn.dark.ex6.TestInflate - 20 00000101
16:52:02.012 [Thread-1] DEBUG cn.dark.ex6.TestInflate - 20 00000101
16:54:45.035 [main] DEBUG cn.dark.ex6.TestInflate - cn.dark.entity.A object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 05 01 00 00 (00000101 00000001 00000000 00000000) (261)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 2c 6a 01 f8 (00101100 01101010 00000001 11111000) (-134125012)
12 4 (loss due to the next object alignment)
前面19个对象都需要进行撤销,当达到20时,所有的对象头都变成了101了,并且偏向当前线程t2(这里需要注意,批量指的是当前正被加锁的所有对象,还没有加锁的,即从第21个对象开始都是逐个重偏向;另外虽重偏向是先将锁对象设置为可偏向无锁模式101,再讲线程id设置进去),如果此时你打印完整的对象头出来还会发现偏向时间戳标志设置为了01,即代表过期进行了重偏向。需要注意,这时候新建的对象也是101状态,且是重偏向。
批量撤销
JVM还有一个参数-XX:BiasedLockingBulkRevokeThreshold=40用来控制批量撤销,即默认当一个类累计撤销达到40次,那么新建的对象就直接是无锁不可偏向的,因为JVM认为这是代码存在了严重的问题。
将t3注释放开,并将loopFlag设置为50,观察结果:
17:15:46.640 [Thread-1] DEBUG cn.dark.ex6.TestInflate - ======t3=====================================
17:15:46.640 [Thread-2] DEBUG cn.dark.ex6.TestInflate - 0 00000001
17:15:46.640 [Thread-2] DEBUG cn.dark.ex6.TestInflate - 0 11100000
17:15:46.640 [Thread-2] DEBUG cn.dark.ex6.TestInflate - 0 00000001
......
17:15:46.644 [Thread-2] DEBUG cn.dark.ex6.TestInflate - 18 00000001
17:15:46.644 [Thread-2] DEBUG cn.dark.ex6.TestInflate - 18 11100000
17:15:46.644 [Thread-2] DEBUG cn.dark.ex6.TestInflate - 18 00000001
17:15:46.644 [Thread-2] DEBUG cn.dark.ex6.TestInflate - 19 00000101
17:15:46.644 [Thread-2] DEBUG cn.dark.ex6.TestInflate - 19 11100000
17:15:46.644 [Thread-2] DEBUG cn.dark.ex6.TestInflate - 19 00000001
.......
17:15:46.650 [Thread-2] DEBUG cn.dark.ex6.TestInflate - 39 00000101
17:15:46.650 [Thread-2] DEBUG cn.dark.ex6.TestInflate - 39 11100000
17:15:46.651 [Thread-2] DEBUG cn.dark.ex6.TestInflate - 39 00000001
......
17:15:46.652 [Thread-2] DEBUG cn.dark.ex6.TestInflate - 49 00000101
17:15:46.652 [Thread-2] DEBUG cn.dark.ex6.TestInflate - 49 11100000
17:15:46.653 [Thread-2] DEBUG cn.dark.ex6.TestInflate - 49 00000001
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 2c 6a 01 f8 (00101100 01101010 00000001 11111000) (-134125012)
12 4 (loss due to the next object alignment)
t3线程前面20个对象都是从001加锁为轻量锁,所以不用进行撤销,而t2线程从第21个对象开始都是获取的偏向锁,所以,t3线程就需要从第21个对象开始撤销,当和其它所有线程对该类对象累计撤销了40次后新建的对象都不能再获取偏向锁(这里博主是直接设置的50个对象,读者可以设置40个对象来验证),不过在此之前已经获取偏向锁的对象还是要逐个撤销。
但是系统是长期运行的,可能批量重偏向之后很久才会累计撤销达到40次,比如一个月、一年甚至更久,这种情况下就没有必要进行批量撤销了,因此JVM提供了一个参数-XX:BiasedLockingDecayTime=25000,即默认距上一次批量重偏向超过25000ms后,计数器就会重置为0。下面是JVM关于这一点的源码:
// 当前时间
jlong cur_time = os::javaTimeMillis();
// 该类上一次批量撤销的时间
jlong last_bulk_revocation_time = k->last_biased_lock_bulk_revocation_time();
// 该类偏向锁撤销的次数
int revocation_count = k->biased_lock_revocation_count();
// BiasedLockingBulkRebiasThreshold是重偏向阈值(默认20),
// BiasedLockingBulkRevokeThreshold是批量撤销阈值(默认40),
// BiasedLockingDecayTime默认25000。
if ((revocation_count >= BiasedLockingBulkRebiasThreshold) &&
(revocation_count < BiasedLockingBulkRevokeThreshold) &&
(last_bulk_revocation_time != 0) &&
(cur_time - last_bulk_revocation_time >= BiasedLockingDecayTime)) {
// 重置计数器
k->set_biased_lock_revocation_count(0);
revocation_count = 0;
}
具体案例很简单,读者们可以思考下怎么验证这个结论。
重量锁
由于synchronized是c++语言实现的,实现比较复杂,就不进行详细的源码分析了,下面只是对其实现原理的一个总结。另外重量锁的实现原理和ReentrantLock的思想是一样的,读者们可以对比理解。
当多个线程发生竞争的时候,synchronized就会膨胀为重量锁,这时会创建一个ObjectMoitor对象,这个对象包含了三个由ObjectWaiter对象组成的队列:cxq、EntryList、WaitSet,以及两个字段owner和Read Thread。cxq和EntryList都是获取锁失败用来存储等待的线程的,WaitSet则是Java中调用wait方法进入阻塞的线程,owner指向当前获取锁的线程,而Read Thread则表示从cxq和EntryList中挑选出来去抢锁的线程,但由于是非公平锁,所以不一定能抢到锁。
在膨胀为重量锁的时候若没有获取到锁,不是立马就阻塞未获取到锁的线程,因其是非公平锁,首先会去尝试加锁,不管前面是否有线程等待(如果是公平锁的话就会判断是否有线程等待,有的话则直接入队睡眠),如果加锁失败,synchronized还会采用自旋的方式去获取锁,JDK1.6之前是默认自旋10次后睡眠,而优化之后引入了适应性自旋,即JVM会根据各种情况动态改变自旋次数:
如果平均负载小于CPU则一直自旋
如果有超过(CPU/2)个线程正在自旋,则后来线程直接阻塞
如果正在自旋的线程发现Owner发生了变化则延迟自旋时间(自旋计数)或进入阻塞
如果CPU处于节电模式则停止自旋
自旋时间的最坏情况是CPU的存储延迟(CPU A存储了一个数据,到CPU B得知这个数据直接的时间差)
自旋时会适当放弃线程优先级之间的差异
你可能会比较好奇为什么不一直采用自旋,因为自旋是会消耗CPU的,适合并发数不多或自旋次数少的情形,否则不如直接调用系统函数进入睡眠状态。
所以当自旋没有获取到锁,则会将当前线程添加到cxq队列的队首(注意在入队后还会抢一次锁,这就是非公平锁的特点,尽可能的避免调用系统函数进入内核态阻塞)并调用park函数睡眠。
park函数是基于pthread_mutex_lock函数实现的,而Java中的LockSupport.park则是基于pthread_cond_timedwait函数,这两个都是系统函数,更底层则是通过futex实现(注意此处都是基于Linux系统讨论,其它不同的操作系统有不同的实现方式),这里就不展开讨论了。
需要注意线程一旦进入队列后,执行的顺序就是固定了,因为在当前持有锁的线程释放锁后,会从队列中唤醒最后入队的线程,即一朝排队,永远排队,所以公平锁和非公平锁的区别就体现在入队前是否抢锁(排除有新的线程来抢锁的情况)。
所谓唤醒最后入队的线程,其实就类似于栈,先睡眠的线程后唤醒,这点和ReentratLock是相反的,下面给出证明:
public class Demo2 {
private static Demo2 lock = new Demo2();
public static void main(String[] args) throws InterruptedException {
Thread[] threads = new Thread[10];
for (int i = 0; i < 10; i++) {
threads[i] = new Thread(() -> {
synchronized (lock) {
log.info(Thread.currentThread().getName());
}
});
}
synchronized (lock) {
for (Thread thread : threads) {
thread.start();
// 睡眠一下保证线程的启动顺序
Thread.sleep(100);
}
}
}
}
上面程序创建了10个线程,然后主线程拿到锁后依次启动10个线程,这10个线程内又会分别去获取锁,因为被主线程占有,就会膨胀为重量锁进入阻塞,最终打印结果如下:
16:25:49.877 [Thread-9] INFO cn.dark.mydemo.sync.Demo2 - Thread-9
16:25:49.879 [Thread-8] INFO cn.dark.mydemo.sync.Demo2 - Thread-8
16:25:49.879 [Thread-7] INFO cn.dark.mydemo.sync.Demo2 - Thread-7
16:25:49.879 [Thread-6] INFO cn.dark.mydemo.sync.Demo2 - Thread-6
16:25:49.879 [Thread-5] INFO cn.dark.mydemo.sync.Demo2 - Thread-5
16:25:49.879 [Thread-4] INFO cn.dark.mydemo.sync.Demo2 - Thread-4
16:25:49.879 [Thread-3] INFO cn.dark.mydemo.sync.Demo2 - Thread-3
16:25:49.879 [Thread-2] INFO cn.dark.mydemo.sync.Demo2 - Thread-2
16:25:49.879 [Thread-1] INFO cn.dark.mydemo.sync.Demo2 - Thread-1
16:25:49.879 [Thread-0] INFO cn.dark.mydemo.sync.Demo2 - Thread-0
可以看到10个线程并不是按照启动顺序执行的,而是以相反的顺序被唤醒并执行。
以上就是Synchronized的膨胀过程以及底层的一些实现原理,最后我画了一张synchronized锁膨胀过程的图帮助理解,有不对的地方欢迎指出: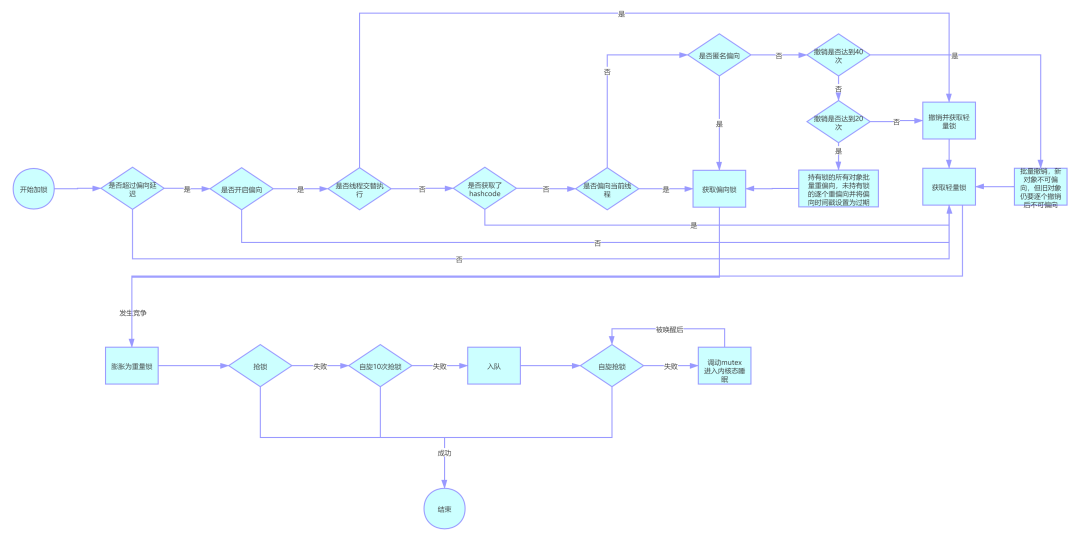
总结
通过两篇文章分析了synchronized的实现原理,可以看到要实现一把高性能的锁是相当复杂的,这也是为什么JDK1.6才对synchronized进行了优化(大概也是迫于ReentratLock的压力吧),优化过后性能基本上和ReentrantLock差不多,只不过后者使用上更加灵活,支持更多的高级特性,但思想上其实都是一样的(应该都是借鉴了futex的实现原理)。
深刻理解synchronized的膨胀过程,不仅仅用于应付面试,而是能够更好的使用它进行并发编程,比如何时加锁,何时使用无锁的自旋锁。另外在进行业务开发遇到类似场景时也可以借鉴其思想。
本篇文章参考了以下文章,最后在此表示感谢,让我少走了很多弯路,也了解了很多底层知识。
linux内核级同步机制--futex
死磕Synchronized底层实现--偏向锁
死磕Synchronized底层实现--轻量级锁
死磕Synchronized底层实现--重量级锁
synchronized实现原理及其优化-(自旋锁,偏向锁,轻量锁,重量锁)


感谢点赞支持下哈 