
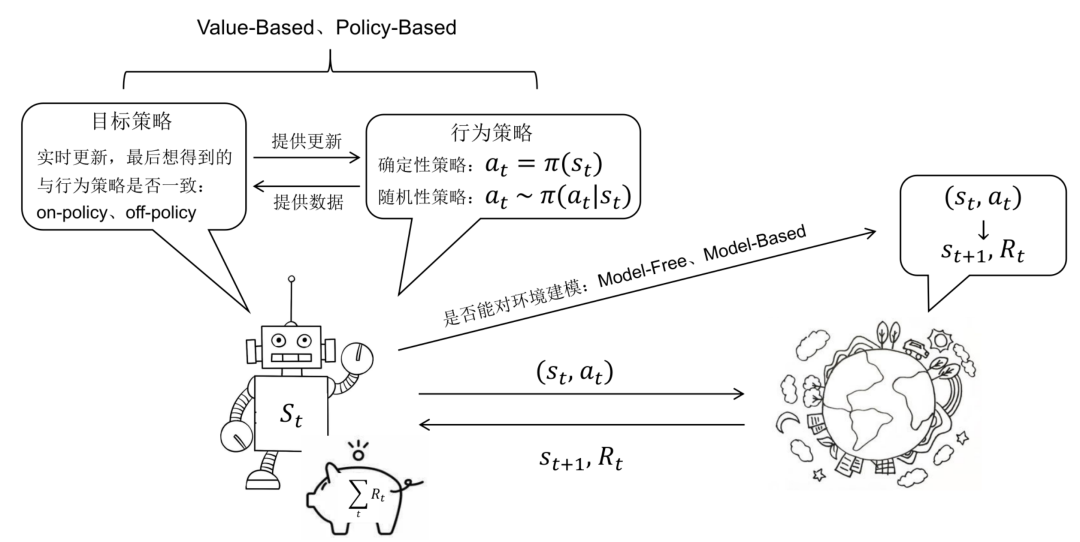
RL的分类:基于模型(Value-base/Policy-based)与不基于模型
本文接前面文章:
根据问题求解思路、方法的不同,我们可以将强化学习分为
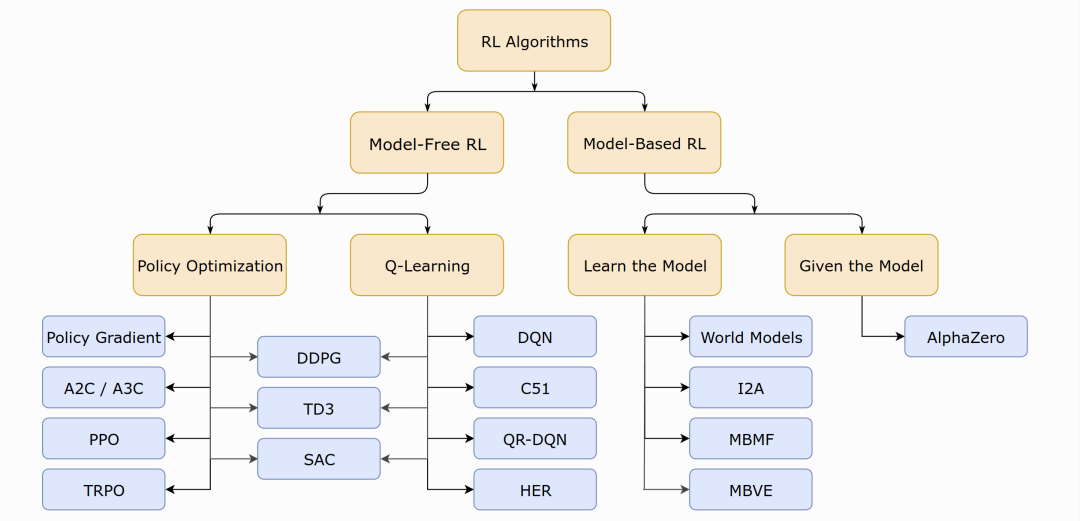
基于模型的强化学习(Model-based RL),可以简单的使用动态规划求解,任务可定义为预测和控制,预测的目的是评估当前策略的好坏,即求解状态价值函数
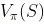 ,控制的目的则是寻找最优策略
,控制的目的则是寻找最优策略
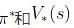
在这里“模型”的含义是对环境进行建模,具体而言,是否已知其P和R,即
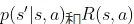 取值
取值
→ 如果有对环境的建模,那么智能体便可以在执行动作前得知状态转移的情况
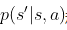 即和奖励
即和奖励
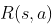 ,也就不需要实际执行动作收集这些数据;
,也就不需要实际执行动作收集这些数据;
→否则便需要进行采样,通过与环境的交互得到下一步的状态和奖励,然后仅依靠采样得到的数据更新策略
无模型的强化学习(Model-free RL),又分为
基于价值的强化学习(Value-based RL),其会学习并贪婪的选择值最大的动作,即
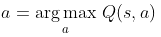 ,最经典的便是off-policy模式的Q-learning和on-policy模式的SARSA,一般得到的是确定性策略,下文第三部分重点介绍
,最经典的便是off-policy模式的Q-learning和on-policy模式的SARSA,一般得到的是确定性策略,下文第三部分重点介绍
基于策略的强化学习(Policy-based RL),其对策略进行进行建模
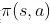
并优化,一般得到的是随机性策略,下文第四部分会重点介绍
好
消
息
小长假后,一起来充电跑赢下半年
 为助力更多小伙伴转型成功,升职加薪,七月在线集训营高级班限时钜惠;加满额赠课+所有集训营高级班课程
为助力更多小伙伴转型成功,升职加薪,七月在线集训营高级班限时钜惠;加满额赠课+所有集训营高级班课程一次报名,答疑服务三年
学术/学业/职称论文,1V1辅导
现在需求也越来越旺,如果你有论文需求,别犹豫,七月在线论文保发;
国内外求职1V1辅导
也如火如荼进行中

有意找苏苏老师(VX:
julyedukefu008
)或七月在线其他老师申请试听/了解课程
(扫码联系苏苏
老师
)
点击“
阅读原文
”
了解课程
~
