目标检测RetinaRet--2018
算法概述
RetinaNet算法源自2018年Facebook AI Research的论文 Focal Loss for Dense Object Detection,作者包括了Ross大神、Kaiming大神和Piotr大神。该论文最大的贡献在于提出了Focal Loss用于解决类别不均衡问题,从而创造了RetinaNet(One Stage目标检测算法)这个精度超越经典Two Stage的Faster-RCNN的目标检测网络。
目标检测的 Two Stage 与 One Stage
基于深度学习的目标检测算法有两类经典的结构:Two Stage 和 One Stage。
Two Stage:例如Faster-RCNN算法。第一级专注于proposal的提取,第二级对提取出的proposal进行分类和精确坐标回归。两级结构准确度较高,但因为第二级需要单独对每个proposal进行分类/回归,速度上就打了折扣
One Stage:例如SSD,YOLO算法。此类算法摒弃了提取proposal的过程,只用一级就完成了识别/回归,虽然速度较快但准确率远远比不上两级结构、
产生精度差异的主要原因:类别失衡(Class Imbalance)。One Stage方法在得到特征图后,会产生密集的目标候选区域,而这些大量的候选区域中只有很少一部分是真正的目标,这样就造成了机器学习中经典的训练样本正负不平衡的问题。它往往会造成最终算出的training loss为占绝对多数但包含信息量却很少的负样本所支配,少样正样本提供的关键信息却不能在一般所用的training loss中发挥正常作用,从而无法得出一个能对模型训练提供正确指导的loss(而Two Stage方法得到proposal后,其候选区域要远远小于One Stage产生的候选区域,因此不会产生严重的类别失衡问题)。常用的解决此问题的方法就是负样本挖掘,或其它更复杂的用于过滤负样本从而使正负样本数维持一定比率的样本取样方法。该论文中提出了Focal Loss来对最终的Loss进行校正。
Focal Loss
Focal Loss的目的:消除类别不平衡 + 挖掘难分样本
Focal Loss非常简单,就是在原有的交叉熵损失函数上增加了一个因子,让损失函数更加关注hard examples,以下是用于二值分类的交叉熵损失函数。其中  为类别真实标签,
为类别真实标签,  是模型预测的
是模型预测的  的概率。
的概率。

可以进行如下定义:

因此交叉熵可以写成如下形式,即如下loss曲线图中蓝色曲线所示,可以认为当模型预测得到的  的样本为容易分类的样本,而
的样本为容易分类的样本,而  值预测较小的样本为hard examples,最后震整个网络的loss就是所有训练样本经过模型预测得到的值的累加,因为hard examples通常为少数样本,所以虽然其对应的loss值较高,但是最后全部累加后,大部分的loss值来自于容易分类的样本,这样在模型优化的过程中就会将更多的优化放到容易分类的样本中,而忽略hard examples。
值预测较小的样本为hard examples,最后震整个网络的loss就是所有训练样本经过模型预测得到的值的累加,因为hard examples通常为少数样本,所以虽然其对应的loss值较高,但是最后全部累加后,大部分的loss值来自于容易分类的样本,这样在模型优化的过程中就会将更多的优化放到容易分类的样本中,而忽略hard examples。

对于这种类别不均衡问题常用的方法是引入一个权重因子  ,对于类别1的使用权重 ,对于类别-1使用权重
,对于类别1的使用权重 ,对于类别-1使用权重  ,公式如下所示。但采用这种加权方式可以平衡正负样本的重要性,但无法区分容易分类的样本与难分类的样本。
,公式如下所示。但采用这种加权方式可以平衡正负样本的重要性,但无法区分容易分类的样本与难分类的样本。

因此论文中提出在交叉熵前增加一个调节因子  ,其中
,其中  为focusing parameter,且
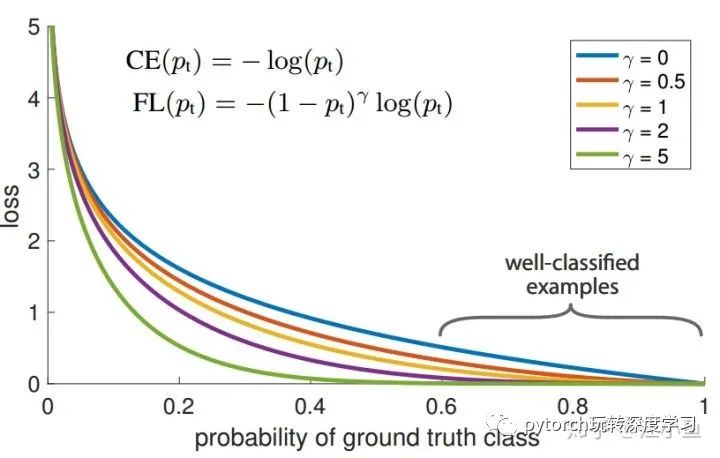
为focusing parameter,且  ,其公式变为如下,当 取不同数值时loss曲线如图1所示。通过途中可以看到,当 越来越大时,loss函数在容易分类的部分其loss几乎为零,而 较小的部分(hard examples部分)loss值仍然较大,这样就可以保证在类别不平衡较大时,累加样本loss,可以让hard examples贡献更多的loss,从而可以在训练时给与hard examples部分更多的优化。
,其公式变为如下,当 取不同数值时loss曲线如图1所示。通过途中可以看到,当 越来越大时,loss函数在容易分类的部分其loss几乎为零,而 较小的部分(hard examples部分)loss值仍然较大,这样就可以保证在类别不平衡较大时,累加样本loss,可以让hard examples贡献更多的loss,从而可以在训练时给与hard examples部分更多的优化。

在实际使用时,论文中提出在上述公式的基础上,增加一个 平衡因子,可以产生一个轻微的精度提升,公式如下所示。

RetinaNet
下图是RetinaNet的网络结构,整个网络相对Faster-RCNN简单了很多,主要由ResNet+FPN+2xFCN子网络构成。
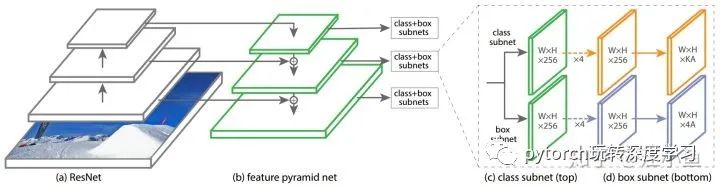
首先RetinaNet的Backbone是由ResNet+FPN构成,关于此Backbone可以参考以下链接中关于Backbone的讲解。输入图像经过Backbone的特征提取后,可以得到  特征图金字塔,其中下标
特征图金字塔,其中下标  表示特征金字塔的层数(
表示特征金字塔的层数(  特征图的分辨率比输入图像小
特征图的分辨率比输入图像小  ),得到的特征金字塔的每层
),得到的特征金字塔的每层  通道。
通道。

在得到特征金字塔后,对每层特征金字塔分别使用两个子网络(分类网络+检测框位置回归)。这两个子网络由RPN网络修改得到。
与RPN网络类似,也使用anchors来产生proposals。特征金字塔的每层对应一个anchor面积,为了产生更加密集的coverage,增加了三个面积比例
 (即使用当前anchor对应的面积分别乘以相应的比例,形成三个尺度),然后anchors的长宽比仍为
(即使用当前anchor对应的面积分别乘以相应的比例,形成三个尺度),然后anchors的长宽比仍为  ,因此特征金字塔的每一层对应A = 9种Anchors。
,因此特征金字塔的每一层对应A = 9种Anchors。原始RPN网络的分类网络只是区分前景与背景两类,此处将其改为目标类别的个数K
上面说到的Focal Loss就应用于类别分类的子网络,即可有效移植类别不均衡问题。
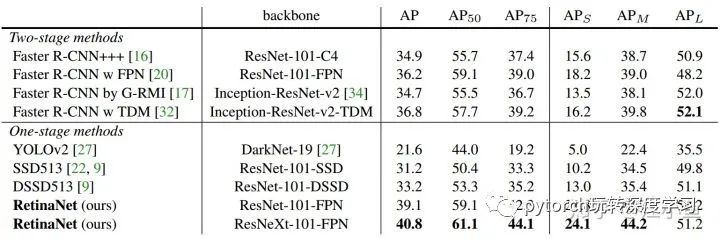
特征金字塔每层都相应的产生目标类别与位置的预测,最后再将其融合起来,同时使用NMS来得到最后的检测结果。下图是论文中给出的试验结果,相比较于经典的Two Stage检测方法Faster-RCNN,RetinaNet具有更高的精度。