
如何利用CPU Cache写出高性能代码,看这些图就够了!
 | 世界就像个巨大的马戏团,它让你兴奋,却让我惶恐,因为我知道散场永远是——有限温存,无限辛酸。 ——卓别林 |
我们平时编写的代码最后都会交给CPU来执行,如何能巧妙利用CPU写出性能比较高的代码呢?看完这篇文章您可能会有所收获。
先提出几个问题,之后我们逐个击破:

初入宝地:什么是CPU Cache?
连类比事:为什么要有Cache?为什么要有多级Cache?
挑灯细览:Cache的大小和速度如何?
追本溯源:什么是Cache Line?
旁枝末叶:什么是Cache一致性?
触类旁通:Cache与主存的映射关系如何?
更上一层:如何巧妙利用CPU Cache编程?
1. 什么是CPU Cache?
如图所示:
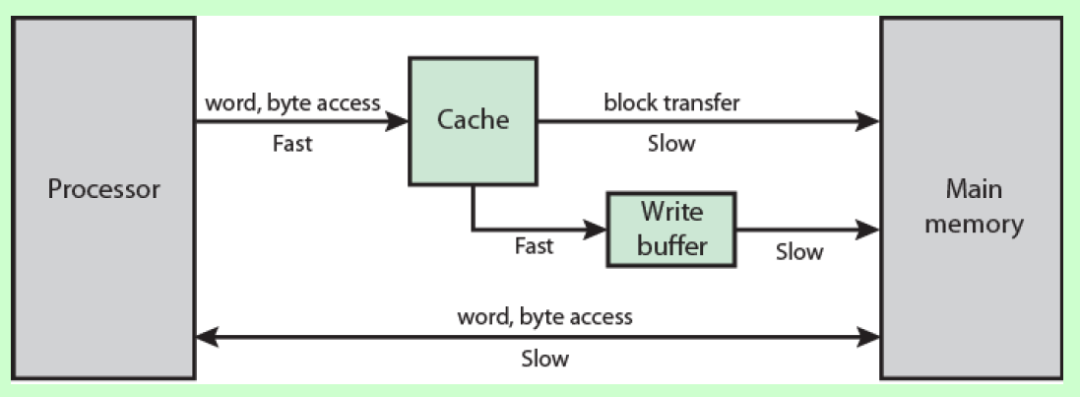
CPU Cache可以理解为CPU内部的高速缓存,当CPU从内存中读取数据时,并不是只读自己想要的那一部分,而是读取更多的字节到CPU高速缓存中。当CPU继续访问相邻的数据时,就不必每次都从内存中读取,可以直接从高速缓存行读取数据,而访问高速缓存比访问内存速度要快的多,所以速度会得到极大提升。
2. 为什么要有Cache?为什么要有多级Cache?
为什么要有Cache这个问题想必大家心里都已经有了答案了吧,CPU直接访问距离较远,容量较大,性能较差的主存速度很慢,所以在CPU和内存之间插入了Cache,CPU访问Cache的速度远高于访问主存的速度。
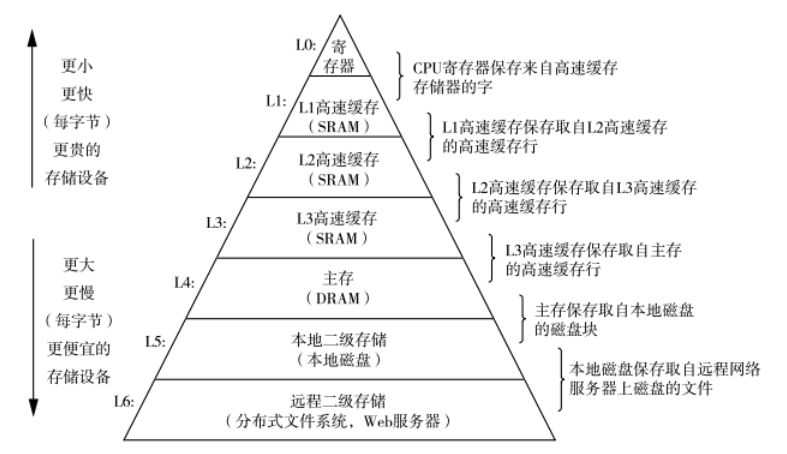
CPU Cache是位于CPU和内存之间的临时存储器,它的容量比内存小很多但速度极快,可以将内存中的一小部分加载到Cache中,当CPU需要访问这一小部分数据时可以直接从Cache中读取,加快了访问速度。
想必大家都听说过程序局部性原理,这也是CPU引入Cache的理论基础,程序局部性分为时间局部性和空间局部性。时间局部性是指被CPU访问的数据,短期内还要被继续访问,比如循环、递归、方法的反复调用等。空间局部性是指被CPU访问的数据相邻的数据,CPU短期内还要被继续访问,比如顺序执行的代码、连续创建的两个对象、数组等。因为如果将刚刚访问的数据和相邻的数据都缓存到Cache时,那下次CPU访问时,可以直接从Cache中读取,提高CPU访问数据的速度。
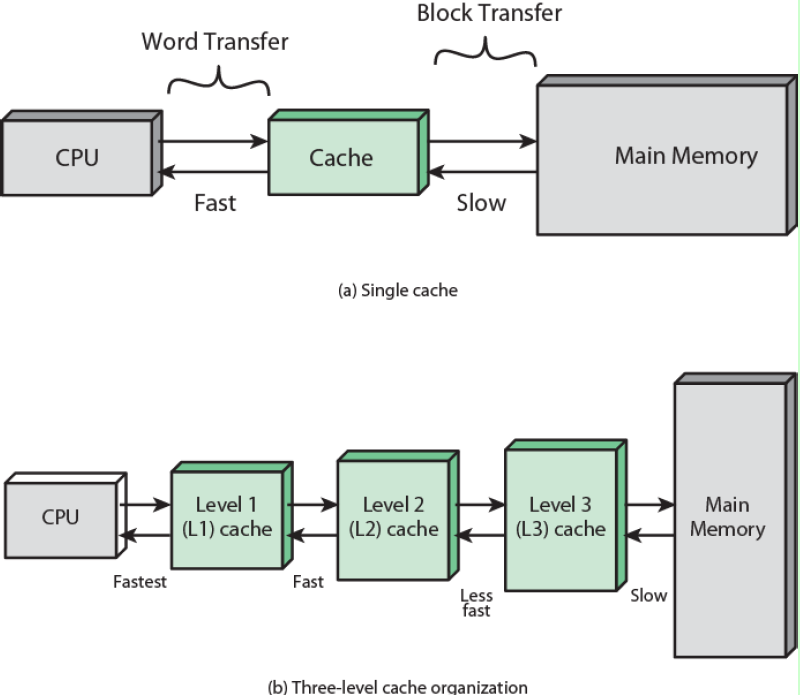
一个存储器层次大体结构如图所示,速度越快的存储设备自然价格也就越高,随着数据访问量的增大,单纯的增加一级缓存的成本太高,性价比太低,所以才有了二级缓存和三级缓存,他们的容量越来越大,速度越来越慢(但还是比内存的速度快),成本越来越低。
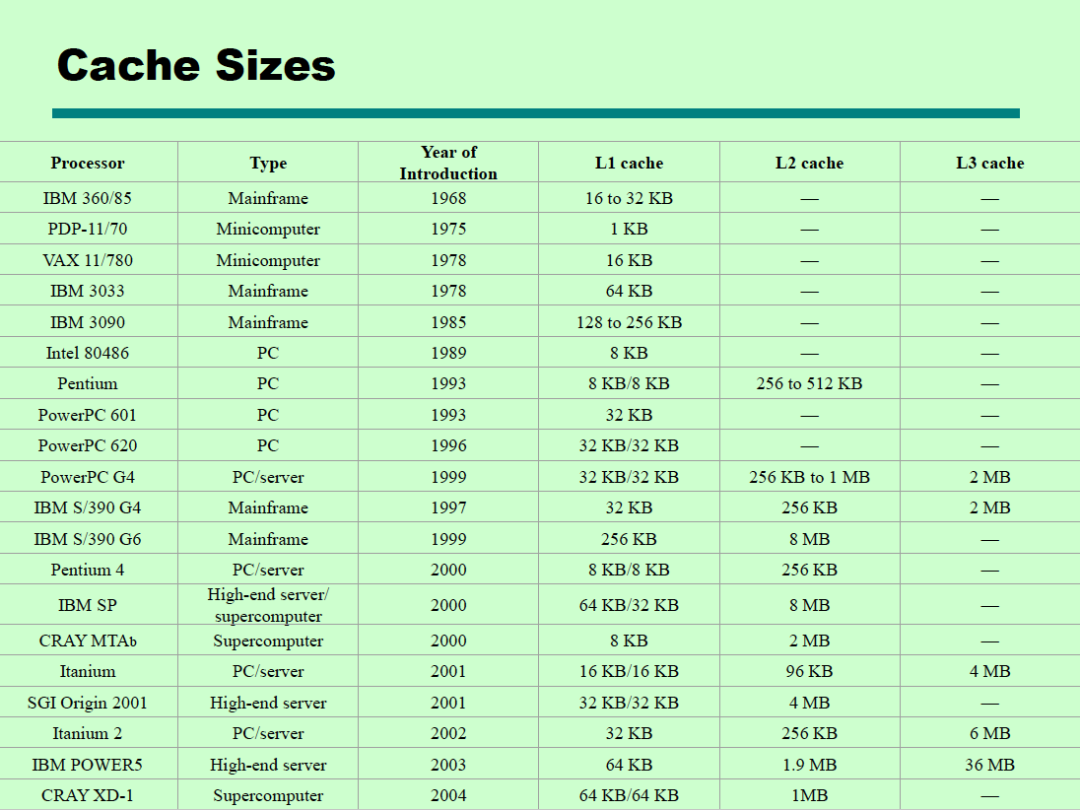
通常越接近CPU的缓存级别越低,容量越小,速度越快。不同的处理器Cache大小不同,通常现在的处理器的L1 Cache大小都是64KB。
那CPU访问各个Cache的速度如何呢?
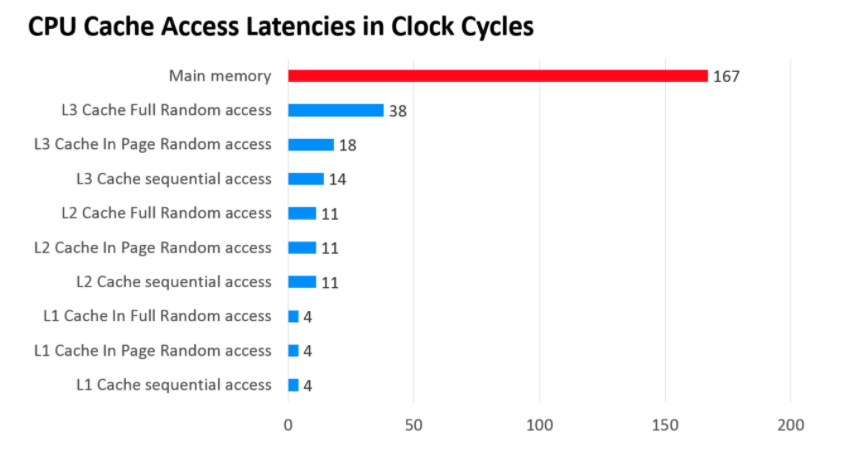
如图所示,级别越低的高速缓存,CPU访问的速度越快。
CPU多级缓存架构大体如下:
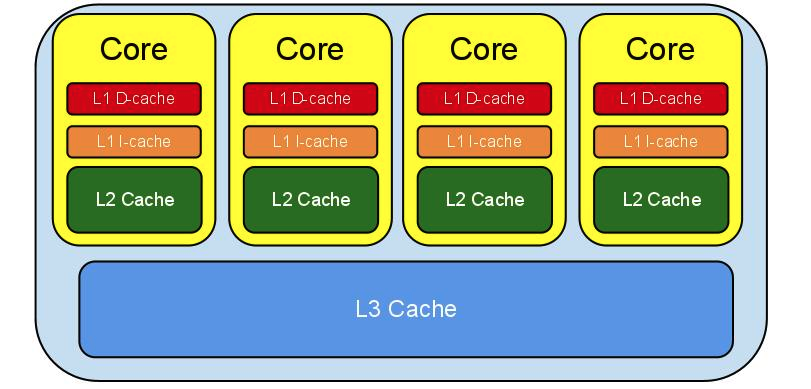
L1 Cache是最离CPU最近的,它容量最小,速度最快,每个CPU都有L1 Cache,见上图,其实每个CPU都有两个L1 Cache,一个是L1D Cache,用于存取数据,另一个是L1I Cache,用于存取指令。
L2 Cache容量较L1大,速度较L1较慢,每个CPU也都有一个L2 Cache。L2 Cache制造成本比L1 Cache更低,它的作用就是存储那些CPU需要用到的且L1 Cache miss的数据。
L3 Cache容量较L2大,速度较L2慢,L3 Cache不同于L1 Cache和L2 Cache,它是所有CPU共享的,可以把它理解为速度更快,容量更小的内存。
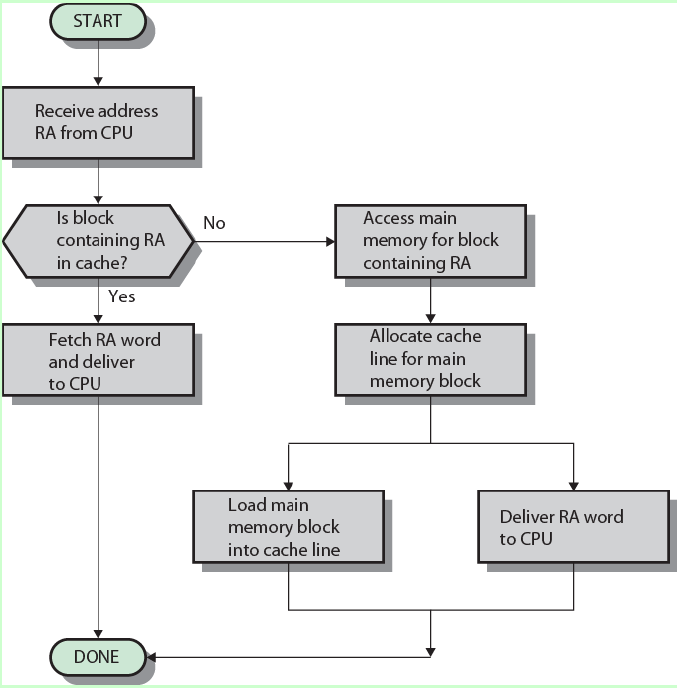
当CPU需要数据时,整体流程如下:
多个CPU对某块内存同时读写,就会引起冲突的问题,被称为Cache一致性问题。
有这样一种情况:
这种问题就被称为Cache一致性问题,为了解决这个问题大佬们设计了MESI协议,当一个CPU1修改了Cache中的某字节数据时,那么其它的所有CPU都会收到通知,它们的相应Cache就会被置为无效状态,当其他的CPU需要访问此字节的数据时,发现自己的Cache相关数据已失效,这时CPU1会立刻把数据写到内存中,其它的CPU就会立刻从内存中读取该数据。
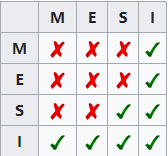
MESI协议是通过四种状态的控制来解决Cache一致性的问题:
■ M:代表已修改(Modified) 缓存行是脏的(dirty),与主存的值不同。如果别的CPU内核要读主存这块数据,该缓存行必须回写到主存,状态变为共享(S).
■ E:代表独占(Exclusive) 缓存行只在当前缓存中,但是干净的(clean)--缓存数据同于主存数据。当别的缓存读取它时,状态变为共享(S);当前写数据时,变为已修改(M)状态。
■ S:代表共享(Shared) 缓存行也存在于其它缓存中且是干净(clean)的。缓存行可以在任意时刻抛弃。
■ I:代表已失效(Invalidated) 缓存行是脏的(dirty),无效的。
四种状态的相容关系如下:
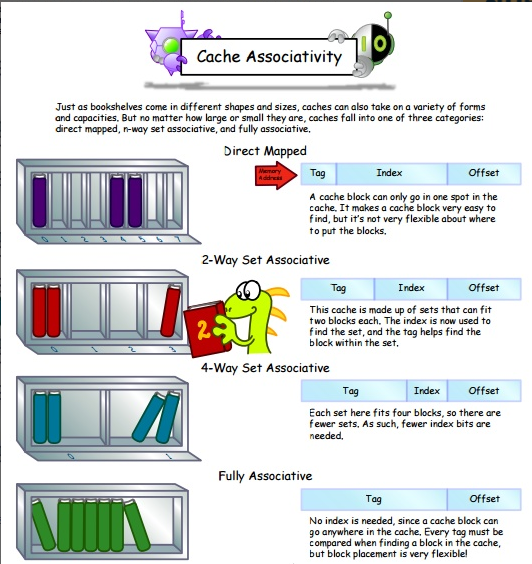
直接映射

直接映射如图所示,每个主存块只能映射Cache的一个特定块。直接映射是最简单的地址映射方式,它的硬件简单,成本低,地址转换速度快,但是这种方式不太灵活,Cache的存储空间得不到充分利用,每个主存块在Cache中只有一个固定位置可存放,容易产生冲突,使Cache效率下降,因此只适合大容量Cache采用。
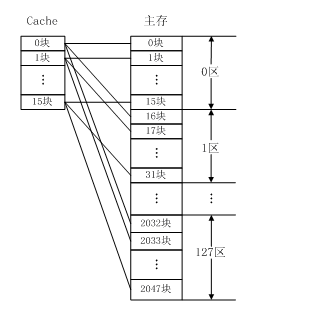
例如,如果一个程序需要重复引用主存中第0块与第16块,最好将主存第0块与第16块同时复制到Cache中,但由于它们都只能复制到Cache的第0块中去,即使Cache中别的存储空间空着也不能占用,因此这两个块会不断地交替装入Cache中,导致命中率降低。
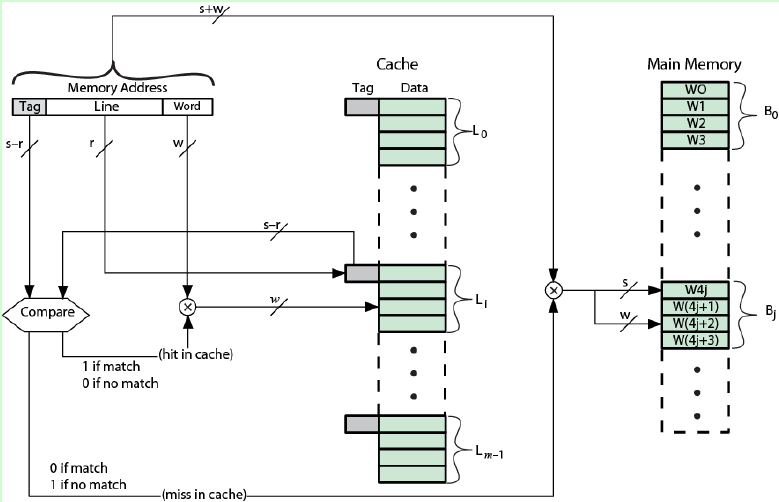
直接映射方式下主存地址格式如图,主存地址为s+w位,Cache空间有2的r次方行,每行大小有2的w次方字节,则Cache地址有w+r位。通过Line确定该内存块应该在Cache中的位置,确定位置后比较标记是否相同,如果相同则表示Cache命中,从Cache中读取。
全相连映射
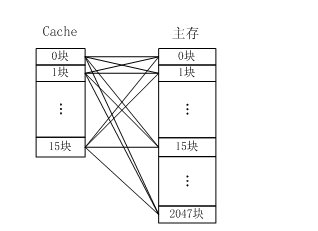
全相连映射如图所示,主存中任何一块都可以映射到Cache中的任何一块位置上。
全相联映射方式比较灵活,主存的各块可以映射到Cache的任一块中,Cache的利用率高,块冲突概率低,只要淘汰Cache中的某一块,即可调入主存的任一块。但是,由于Cache比较电路的设计和实现比较困难,这种方式只适合于小容量Cache采用。
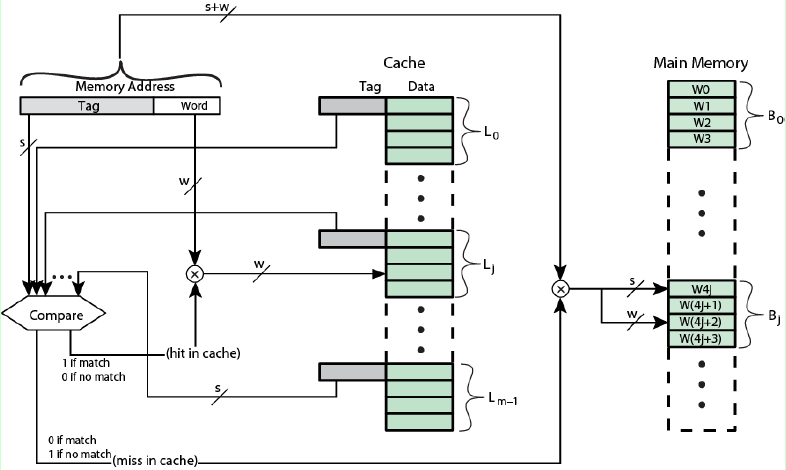
全相连映射的主存结构就很简单啦,将CPU发出的内存地址的块号部分与Cache所有行的标记进行比较,如果有相同的,则Cache命中,从Cache中读取,如果找不到,则没有命中,从主存中读取。
组相连映射
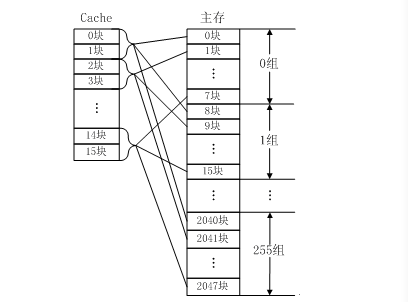
组相联映射实际上是直接映射和全相联映射的折中方案,其组织结构如图3-16所示。主存和Cache都分组,主存中一个组内的块数与Cache中的分组数相同,组间采用直接映射,组内采用全相联映射。也就是说,将Cache分成u组,每组v块,主存块存放到哪个组是固定的,至于存到该组哪一块则是灵活的。例如,主存分为256组,每组8块,Cache分为8组,每组2块。
主存中的各块与Cache的组号之间有固定的映射关系,但可自由映射到对应Cache组中的任何一块。例如,主存中的第0块、第8块……均映射于Cache的第0组,但可映射到Cache第0组中的第0块或第1块;主存的第1块、第9块……均映射于Cache的第1组,但可映射到Cache第1组中的第2块或第3块。
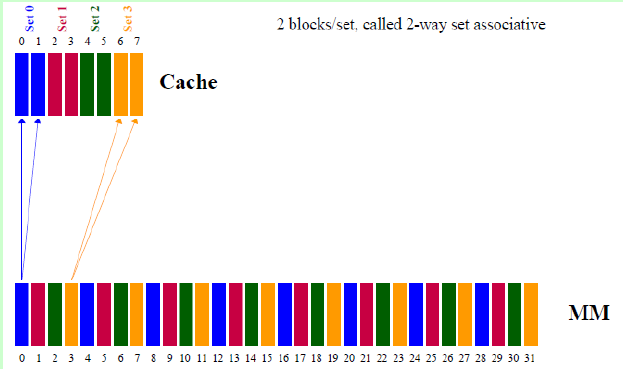
常采用的组相联结构Cache,每组内有2、4、8、16块,称为2路、4路、8路、16路组相联Cache。组相联结构Cache是前两种方法的折中方案,适度兼顾二者的优点,尽量避免二者的缺点,因而得到普遍采用。
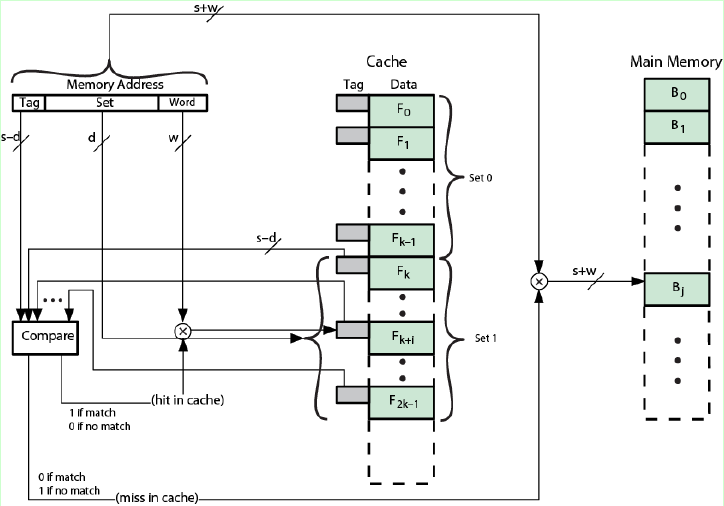
组相连映射方式下的主存地址格式如图,先确定主存应该在Cache中的哪一个组,之后组内是全相联映射,依次比较组内的标记,如果有标记相同的Cache,则命中,否则不命中。
在网上找到了三种映射方式下的主存格式对比图,大家也可以看下:
Cache的替换策略想必大家都知道,就是LRU策略,即最近最少使用算法,选择未使用时间最长的Cache替换。
const int row = 1024;const int col = 1024;int matrix[row][col];//按行遍历int sum_row = 0;for (int r = 0; r < row; r++) {for (int c = 0; c < col; c++) {sum_row += matrix[r][c];}}//按列遍历int sum_col = 0;for (int c = 0; c < col; c++) {for (int r = 0; r < row; r++) {sum_col += matrix[r][c];}}
上面是两段二维数组的遍历方式,一种按行遍历,另一种是按列遍历,乍一看您可能认为计算量没有任何区别,但其实按行遍历比按列遍历速度快的多,这就是CPU Cache起到了作用,根据程序局部性原理,访问主存时会把相邻的部分数据也加载到Cache中,下次访问相邻数据时Cache的命中率极高,速度自然也会提升不少。
平时编程过程中也可以多利用好程序的时间局部性和空间局部性原理,就可以提高CPU Cache的命中率,提高程序运行的效率。
参考链接
https://cseweb.ucsd.edu/classes/fa14/cse240A-a/pdf/08/CSE240A-MBT-L15-Cache.ppt.pdf
http://www.ecs.csun.edu/~cputnam/Comp546/Putnam/Cache%20Memory.pdf
https://ece752.ece.wisc.edu/lect11-cache-replacement.pdf
http://www.ipdps.org/ipdps2010/ipdps2010-slides/session-22/2010IPDPS.pdf
https://faculty.tarleton.edu/agapie/documents/cs_343_arch/04_CacheMemory.pdf
https://www.cnblogs.com/bjlhx/p/10658938.html
https://zh.wikipedia.org/wiki/MESI%E5%8D%8F%E8%AE%AE
https://www.cnblogs.com/yanlong300/p/8986041.html
https://coolshell.cn/articles/20793.html
https://zhuanlan.zhihu.com/p/31875174
https://www.cnblogs.com/jokerjason/p/10711022.html
http://cenalulu.github.io/linux/all-about-cpu-cache/
https://my.oschina.net/fileoptions/blog/1630855
https://www.pianshen.com/article/9557956769/
https://blog.csdn.net/weixin_42649617/article/details/105092395
文中图片来自网络