
值得一看的文本检测方法
作者:晟 沚
目前深度学习方法做文本检测比较普遍,但是也存在一些时候GPU资源不够,这时候就需要一些其他的方法来检测文本信息,本文主要介绍不使用深度学习进行文本检测的方法。文本检测的瓶颈主要是处理那些对比度不同或嵌入复杂背景的文本。为了解决这些困难,本文主要介绍的方法可以基于不变的特征,例如边缘强度,边缘密度和水平分布。首先,它应用边缘检测,并使用较低的阈值来过滤掉非文本边缘。然后,选择局部阈值以保留低对比度文本并简化高对比度文本的复杂背景。接下来,用两个文本区域增强operator,以突出显示具有高边缘强度或高边缘密度的那些区域。最后,从粗到细的检测可以有效地定位文本区域。实验结果表明,本文提出的方法在对比度,字体大小,字体颜色,语言和背景复杂性方面均十分可靠。
01
分析
当文本嵌入复杂的背景中时,文本的对比度,即文本的颜色(或亮度)与其局部背景之间的差异,会在图像的不同区域发生变化。因此,使用全局阈值分隔文本和背景的方法将丢失低对比度文本。例如,(图a)显示了具有不同对比度文本的图像。应用Sobel运算符后,如果阈值是40(图b),则所有文本都会保留,阈值为65,则低对比度文本消失(图c)。
另外,不同语言的字符具有各种笔画结构。使用笔划密度约束的方法可以成功检测英语等。但是无法正确检测亚洲语言文字,例如中文。例如,区域增长方法使用小尺寸的窗口扫描图像并将每个窗口分类为文本或非文本,然后合并相邻的文本块形成文本区域。由于每个汉字占用相同的空间,而笔划数从1到大于20不等,因此笔划少的字符将不会被笔划密度约束分类为文本。
针对文本的特殊,总结如下规律:
尽管文本字符串的像素颜色不均匀,但是视频中可识别的文本字符串确实具有密集或鲜明的颜色或亮度过渡,即相对于其背景的边缘。因此,边缘是比字体颜色更可靠的功能。边缘具有两个属性:边缘强度和边缘密度。当嵌入在简单且高对比度的背景中时,文本字符串在边缘强度和边缘密度上都很明显。当嵌入在简单且低对比度的背景中时,主要是边缘密度很明显。当嵌入到充满非文本对象边缘的复杂背景中时,主要是边缘强度就很明显。由于不可能用很少的笔划由所有字符组成文本字符串,因此其平均边缘密度明显高于背景。字符大多是直立的,并在与水平线对齐的有限距离内成簇出现,并且它们显示出空间凝聚力–同一文本字符串的字符具有相似的高度,方向和间距。
所以,基于边缘强度,边缘密度和水平分布,可以设计一种有效的方法来检测复杂背景下的多语言文本。
02
具体方法
本文的方法的目标是在不受到语言和字体大小影响的情况下,检测低对比度文本和高对比度文本。首先,使用彩色边缘检测器将视频图像转换为边缘图,并使用较低的全局阈值来过滤掉绝对非边缘点。然后,执行选择性局部阈值处理以简化复杂背景。接下来,用一个边缘强度平滑算子和一个边缘聚类功率算子,以突出显示那些边缘强度高或边缘密度高的区域,即文本候选者。最后,考虑到特征随语言和字体大小不变,采用一种面向字符串的从粗到细的检测方法来快速定位文本字符串。
边缘检测
彩色边缘检测器使用Sobel运算符检测YUV颜色空间中的边缘。最终的颜色边缘图是Y,U和V通道的三个边缘图的并集。但是,由于阈值太高而无法保留低对比度文本,因此不使用快速熵阈值化。取而代之的是,应用由边缘强度直方图确定的低阈值,以仅消除绝对的非文本点。首先,在直方图中找到排名0-20的峰,并获得其周围的平均高度;然后,低阈值是峰后高度低于平均高度10%的第一个位置。在全局阈值化之后,非边缘点的值为零,而边缘点的值为其各自的边缘强度。
局部阈值
如果背景是简单的,则可以通过低阈值轻松检测甚至低对比度的文本字符串,而嵌入复杂背景中的文本字符串需要更高的阈值才能进一步简化背景。因此,有必要根据每个局部区域的背景复杂度确定适当的阈值。定义一个大小为H×W的窗口(H和W分别与图像的高度和宽度成比例)。窗口首先在水平方向上然后在垂直方向上逐步扫描边缘特征图,如下图所示。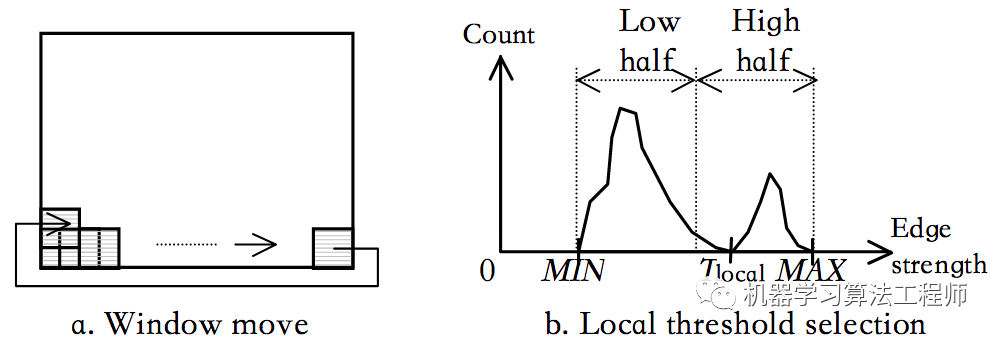
在每个步骤中,窗口的原点仅在水平方向上移动W / 2(或在垂直方向上移动H / 2),因此可以补偿因使用窗口边框分割字符而导致的不准确性。窗口覆盖的边缘图部分是要分析的局部区域。
背景复杂度定义如下。
如果像素是非边缘点,将其称为空白点。如果该局部区域中全部空白行的数量不少于10%×H,则背景复杂度很简单。简单区域不再需要阈值,而复杂区域则需要更高的阈值。从该区域的局部直方图中可以找到新的阈值。令MAX和MIN分别为最高边缘强度和最低边缘强度。在[MIN,MAX]的下半部分找到低峰,在[MIN,MAX]的上半部分找到高峰,然后将新阈值确定为低峰和高峰之间的最低位置。在该区域中强度低于Tlocal的边缘点标记。扫描完整个边缘图后,将删除所有带有标志的边缘点。应用选择性局部阈值,可以保持简单背景下的低对比度文本,同时简化了高对比度文本的背景。
文本区域的增强
通过选择性局部阈值选取出在局部背景中明显的边缘点。然而,仅利用了边缘强度特征。为了通过边缘密度功能进一步突出显示文本区域,通过边缘强度平滑(ESS)算子和边缘聚类功率(ECP)算子,其卷积内核如下图所示。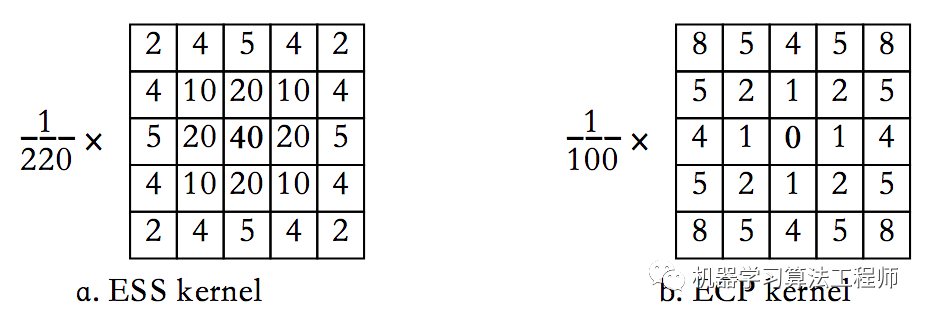
两个核中的权重均来自欧几里得距离。最后是使用整数来加快卷积速度,因此将卷积结果除以权重之和(ESS的权重为220,ECP的权重为100)。ESS权重与从中心向外的距离的平方成反比。它反映了中心边缘点周围的平均边缘强度。由于局部阈值处理可能会降低文本区域中的边缘密度,因此首先使用如下等式对边缘图中每个表示为EM(x,y)的点执行ESS算子,以增加边缘密度。
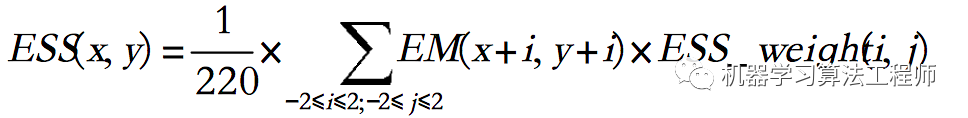
ESS特征图是平滑的边缘强度特征图。然后,通过仅对ESS算子中的非零点执行ECP算子来增强高边缘密度区域,如下公式所示。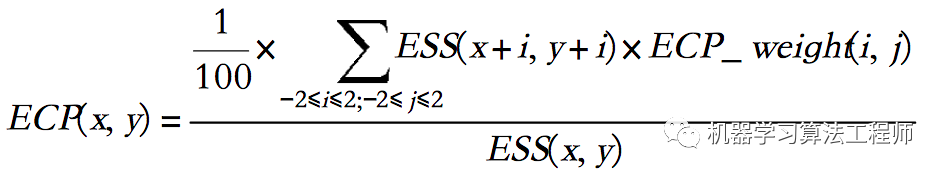
ECP权重与从中心向外的距离的平方成正比,卷积结果除以其自身的ESS值。如果ECP有许多相邻的边缘点具有更高或相似的边缘强度,则无论边缘点的ESS值是什么,ECP都仅会突出显示中心点周围的边缘密度。最后,通过如下公式对ESS值和ECP值进行积分,并更新边缘图。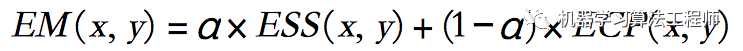
通常,ESS和ECP,α为0.5。
粗到细的检测方法
显然,具有高密度的水平矩形区域表示文本字符串。投影是查找此类高密度区域的一种比其他方法(例如区域生长方法)更有效的方法,因为文本字符串在水平投影中始终会产生急剧的跳跃。但是,在视频图像中,文本字符串不会逐行显示。它们通常在水平或垂直维度上重叠。由于简单的投影仅反映一维的分布,因此无法很好地处理这种情况。因此,通过一种从粗到精的检测方案来解决此问题。粗到细检测的想法是通过两阶段投影来逐步定位文本区域,如下图。
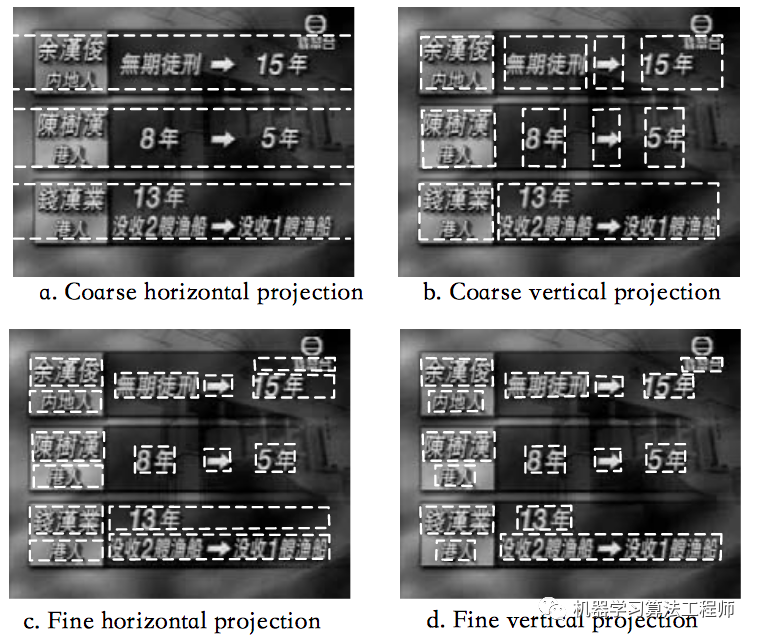
在第一阶段,它使用粗水平投影和粗垂直投影将边缘图粗略地分割为文本块。然后,在第二阶段,它通过精细的水平投影和精细的垂直投影来精确地定位文本区域。请注意,只有粗略的水平投影是整体投影,其他都是矩形区域中的局部投影。最后,根据平均密度,精细的垂直投影中的峰分布和密度分布的规则检查文本状区域非文本区域。由于预处理显着突出了类似文本的区域,因此可以轻松快速地找到文本字符串。下面给出一些结果:




END
机器学习算法工程师
一个用心的公众号
