
实战 | 在真实场景实现双目立体匹配获取深度图
点击左上方蓝字关注我们

目前大多数立体匹配算法使用的都是标准测试平台提供的标准图像对,比如著名的有如下两个:
MiddleBury: http://vision.middlebury.edu/stereo/;
KITTI:http://www.cvlibs.net/datasets/kitti/eval_scene_flow.php?benchmark=stereo
但是对于想自己尝试拍摄双目图片进行立体匹配获取深度图,进行三维重建等操作的童鞋来讲,要做的工作是比使用校正好的标准测试图像对要多的。因此博主觉得有必要从用双目相机拍摄图像开始,捋一捋这整个流程。
主要分四个部分讲解:
摄像机标定(包括内参和外参)
双目图像的校正(包括畸变校正和立体校正)
立体匹配算法获取视差图,以及深度图
利用视差图,或者深度图进行虚拟视点的合成
注:如果没有双目相机,可以使用单个相机平行移动拍摄,外参可以通过摄像机自标定算出。我用自己的手机拍摄,拍摄移动时尽量保证平行移动。
一、摄像机标定
1.内参标定
摄像机内参反映的是摄像机坐标系到图像坐标系之间的投影关系。摄像机内参的标定使用张正友标定法,简单易操作,具体原理请拜读张正友的大作《A Flexible New Technique for Camera Calibration》。当然网上也会有很多资料可供查阅,MATLAB 有专门的摄像机标定工具包,OpenCV封装好的摄像机标定API等。
摄像机的内参包括,fx, fy, cx, cy,以及畸变系数[k1,k2,p1,p2,k3],详细就不赘述。我用手机对着电脑拍摄各个角度的棋盘格图像,棋盘格图像如图所示:

使用OpenCV3.4+VS2015对手机进行内参标定。标定结果如下,手机镜头不是鱼眼镜头,因此使用普通相机模型标定即可:
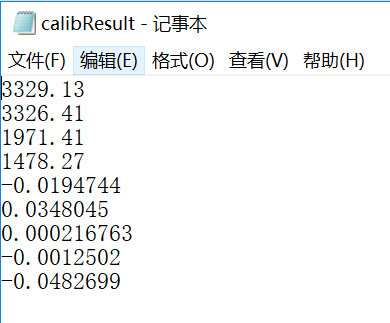
图像分辨率为:3968 x 2976。上面标定结果顺序依次为fx, fy, cx, cy, k1, k2, p1, p2, k3, 保存到文件中供后续使用。
2.外参标定
摄像机外参反映的是摄像机坐标系和世界坐标系之间的旋转R和平移T关系。如果两个相机的内参均已知,并且知道各自与世界坐标系之间的R1、T1和R2,T2,就可以算出这两个相机之间的Rotation和Translation,也就找到了从一个相机坐标系到另一个相机坐标系之间的位置转换关系。摄像机外参标定也可以使用标定板,只是保证左、右两个相机同时拍摄同一个标定板的图像。外参一旦标定好,两个相机的结构就要保持固定,否则外参就会发生变化,需要重新进行外参标定。
那么手机怎么保证拍摄同一个标定板图像并能够保持相对位置不变,这个是很难做到的,因为后续用来拍摄实际测试图像时,手机的位置肯定会发生变化。因此我使用外参自标定的方法,在拍摄实际场景的两张图像时,进行摄像机的外参自标定,从而获取当时两个摄像机位置之间的Rotation和Translation。
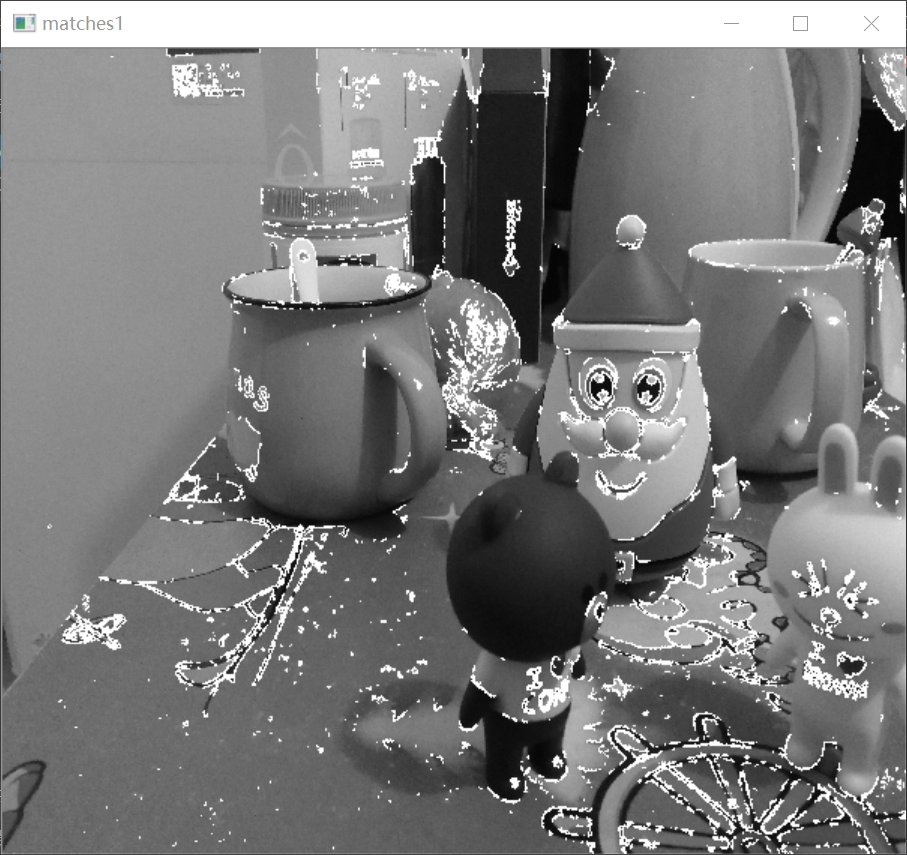
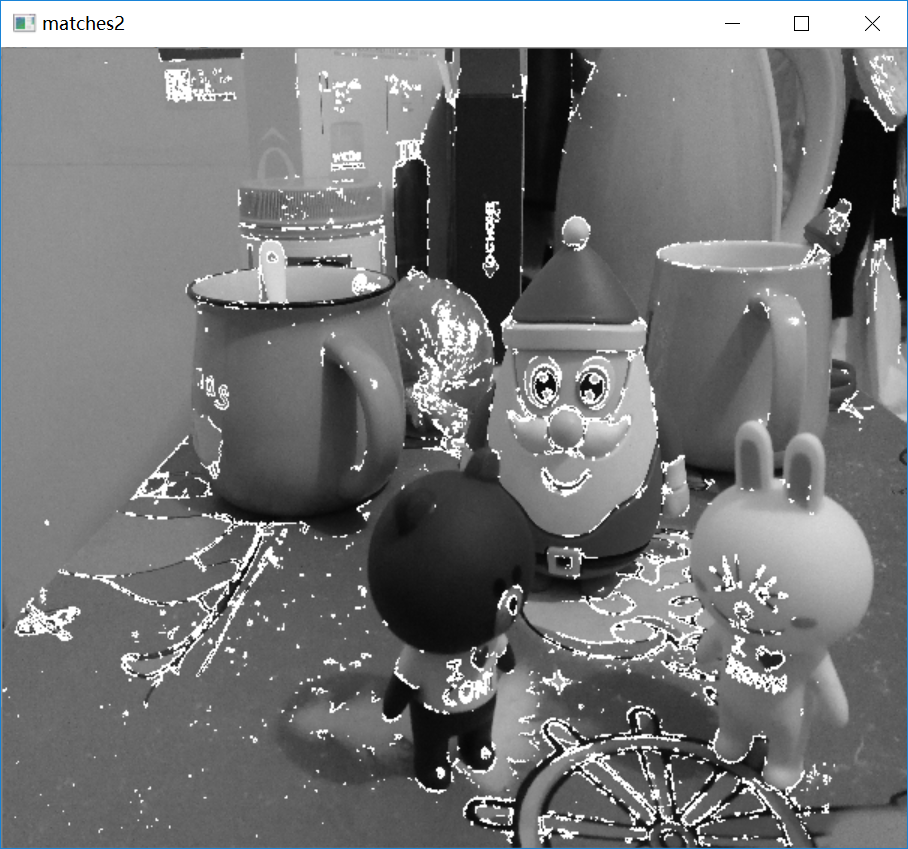
比如:我拍摄这样两幅图像,以后用来进行立体匹配和虚拟视点合成的实验。




cv::Mat E = cv::findEssentialMat(tmpPts1, tmpPts2, camK, CV_RANSAC);cv::Mat R1, R2;cv::decomposeEssentialMat(E, R1, R2, t);R = R1.clone();t = -t.clone();
cv::stereoRectify(camK, D, camK, D, imgL.size(), R, -R*t, R1, R2, P1, P2, Q);
cv::initUndistortRectifyMap(P1(cv::Rect(0, 0, 3, 3)), D, R1, P1(cv::Rect(0, 0, 3, 3)), imgL.size(), CV_32FC1, mapx, mapy);cv::remap(imgL, recImgL, mapx, mapy, CV_INTER_LINEAR);cv::imwrite("data/recConyL.png", recImgL);cv::initUndistortRectifyMap(P2(cv::Rect(0, 0, 3, 3)), D, R2, P2(cv::Rect(0, 0, 3, 3)), imgL.size(), CV_32FC1, mapx, mapy);cv::remap(imgR, recImgR, mapx, mapy, CV_INTER_LINEAR);cv::imwrite("data/recConyR.png", recImgR);


int numberOfDisparities = ((imgSize.width / 8) + 15) & -16;cv::Ptr<cv::StereoSGBM> sgbm = cv::StereoSGBM::create(0, 16, 3);sgbm->setPreFilterCap(32);int SADWindowSize = 9;int sgbmWinSize = SADWindowSize > 0 ? SADWindowSize : 3;sgbm->setBlockSize(sgbmWinSize);int cn = imgL.channels();sgbm->setP1(8 * cn*sgbmWinSize*sgbmWinSize);sgbm->setP2(32 * cn*sgbmWinSize*sgbmWinSize);sgbm->setMinDisparity(0);sgbm->setNumDisparities(numberOfDisparities);sgbm->setUniquenessRatio(10);sgbm->setSpeckleWindowSize(100);sgbm->setSpeckleRange(32);sgbm->setDisp12MaxDiff(1);int alg = STEREO_SGBM;if (alg == STEREO_HH)sgbm->setMode(cv::StereoSGBM::MODE_HH);else if (alg == STEREO_SGBM)sgbm->setMode(cv::StereoSGBM::MODE_SGBM);else if (alg == STEREO_3WAY)sgbm->setMode(cv::StereoSGBM::MODE_SGBM_3WAY);sgbm->compute(imgL, imgR, disp);
sgbm->setMinDisparity(-numberOfDisparities);sgbm->setNumDisparities(numberOfDisparities);sgbm->compute(imgR, imgL, disp);disp = abs(disp);





depth = ( f * baseline) / disp
/*函数作用:视差图转深度图输入: dispMap ----视差图,8位单通道,CV_8UC1 K ----内参矩阵,float类型输出: depthMap ----深度图,16位无符号单通道,CV_16UC1*/void disp2Depth(cv::Mat dispMap, cv::Mat &depthMap, cv::Mat K){int type = dispMap.type();float fx = K.at<float>(0, 0);float fy = K.at<float>(1, 1);float cx = K.at<float>(0, 2);float cy = K.at<float>(1, 2);float baseline = 65; //基线距离65mmif (type == CV_8U){const float PI = 3.14159265358;int height = dispMap.rows;int width = dispMap.cols;uchar* dispData = (uchar*)dispMap.data;ushort* depthData = (ushort*)depthMap.data;for (int i = 0; i < height; i++){for (int j = 0; j < width; j++){int id = i*width + j;if (!dispData[id]) continue; //防止0除depthData[id] = ushort( (float)fx *baseline / ((float)dispData[id]) );}}}else{cout << "please confirm dispImg's type!" << endl;cv::waitKey(0);}}




void insertDepth32f(cv::Mat& depth){const int width = depth.cols;const int height = depth.rows;float* data = (float*)depth.data;cv::Mat integralMap = cv::Mat::zeros(height, width, CV_64F);cv::Mat ptsMap = cv::Mat::zeros(height, width, CV_32S);double* integral = (double*)integralMap.data;int* ptsIntegral = (int*)ptsMap.data;memset(integral, 0, sizeof(double) * width * height);memset(ptsIntegral, 0, sizeof(int) * width * height);for (int i = 0; i < height; ++i){int id1 = i * width;for (int j = 0; j < width; ++j){int id2 = id1 + j;if (data[id2] > 1e-3){integral[id2] = data[id2];ptsIntegral[id2] = 1;}}}// 积分区间for (int i = 0; i < height; ++i){int id1 = i * width;for (int j = 1; j < width; ++j){int id2 = id1 + j;integral[id2] += integral[id2 - 1];ptsIntegral[id2] += ptsIntegral[id2 - 1];}}for (int i = 1; i < height; ++i){int id1 = i * width;for (int j = 0; j < width; ++j){int id2 = id1 + j;integral[id2] += integral[id2 - width];ptsIntegral[id2] += ptsIntegral[id2 - width];}}int wnd;double dWnd = 2;while (dWnd > 1){wnd = int(dWnd);dWnd /= 2;for (int i = 0; i < height; ++i){int id1 = i * width;for (int j = 0; j < width; ++j){int id2 = id1 + j;int left = j - wnd - 1;int right = j + wnd;int top = i - wnd - 1;int bot = i + wnd;left = max(0, left);right = min(right, width - 1);top = max(0, top);bot = min(bot, height - 1);int dx = right - left;int dy = (bot - top) * width;int idLeftTop = top * width + left;int idRightTop = idLeftTop + dx;int idLeftBot = idLeftTop + dy;int idRightBot = idLeftBot + dx;int ptsCnt = ptsIntegral[idRightBot] + ptsIntegral[idLeftTop] - (ptsIntegral[idLeftBot] + ptsIntegral[idRightTop]);double sumGray = integral[idRightBot] + integral[idLeftTop] - (integral[idLeftBot] + integral[idRightTop]);if (ptsCnt <= 0){continue;}data[id2] = float(sumGray / ptsCnt);}}int s = wnd / 2 * 2 + 1;if (s > 201){s = 201;}cv::GaussianBlur(depth, depth, cv::Size(s, s), s, s);}}
END
整理不易,点赞鼓励一下吧↓