
最近常问候选人的一个案例

A/B对比:Mann–Whitney U test(曼-惠特尼U检验);
A/B/N对比:Kruskal-Wallis
是不是我们有95%的把握实验组比对照组好啦?


每个活跃用户付费 = 付费转化率 * 付费用户客单价
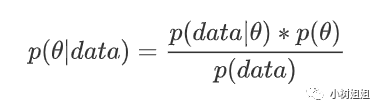
转化率一般可以使用Beta分布作为转化率的先验分布,然后使用实验数据更新Beta分布作为后验分布,再使用抽样的方法计算我们感兴趣的提升概率。(最终还可以去看看我们的假设分布是否合理,如果不合理,还要改变先验)
客单价使用Gamma分布作为客单价的先验分布,使用实验数据更新Gamma分布作为后验分布,再使用抽样的方法计算我们感兴趣的提升概率
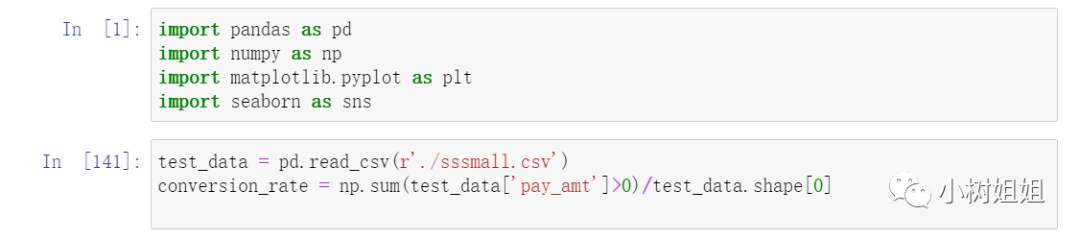
from scipy.stats import betafig,ax = plt.subplots(1, 1)#这里α、β取值都较小,其中conversion_rate是事前的估计值prior_alpha = round(conversion_rate, 2) + 0.1prior_beta = 0.1 + 1 - round(conversion_rate, 2)#假设转化率的先验分布prior = beta(prior_alpha, prior_beta)#看看分布 图x = np.linspace(0,1,1000)ax.plot(x, prior.pdf(x), label=f'prior Beta({int(round(conversion_rate, 1)*) + 1}, {20 + 1 - int(round(conversion_rate, 1)*20)})')ax.set_xlabel('Conversion Probability')ax.set_ylabel('Density')ax.set_title('Chosen Prior')ax.legend()
results = test_data.groupby('test_group').agg({'imei': pd.Series.nunique, 'pay_amt': [np.count_nonzero ,np.sum]})results.columns = ['sampleSize','converted','pay_amt']results['conversionRate'] = results['converted']/results['sampleSize']results['revenuePerSale'] = results['pay_amt']/results['converted']#使用实验数据更新转化率分布control = beta(prior_alpha + results.loc['对照组', 'converted'], prior_beta + results.loc['对照组', 'sampleSize'] - results.loc['对照组', 'converted'])treatment = beta(prior_alpha + results.loc['实验组', 'converted'], prior_beta + results.loc['实验组', 'sampleSize'] - results.loc['实验组', 'converted'])plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号fig, ax = plt.subplots()x = np.linspace(0,0.05,3000)ax.plot(x, control.pdf(x), label='对照组')ax.plot(x, treatment.pdf(x), label='实验组')ax.set_xlabel('Conversion Probability')ax.set_ylabel('Density')ax.set_title('Experiment Posteriors')ax.legend()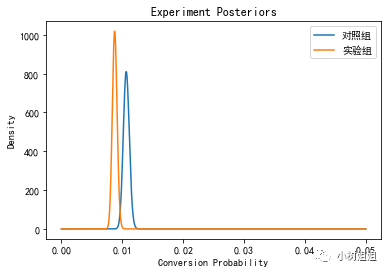
import decimaldecimal.getcontext().prec = 4control_simulation = np.random.beta(prior_alpha + results.loc['对照组', 'converted'], prior_beta + results.loc['对照组', 'sampleSize'] - results.loc['对照组', 'converted'], size=30000)treatment_simulation = np.random.beta(prior_alpha + results.loc['实验组', 'converted'], prior_beta + results.loc['实验组', 'sampleSize'] - results.loc['实验组', 'converted'], size=30000)treatment_won = [i <= j for i,j in zip(control_simulation, treatment_simulation)]chance_of_beating_control = np.mean(treatment_won)print(f'Chance of treatment beating control is {decimal.getcontext().create_decimal(chance_of_beating_control)}')
from scipy.stats import gammacontrol_rr = gamma(a=(1 + results.loc['对照组', 'converted']), scale=(10/(1 + 0.1 * results.loc['对照组', 'converted']*results.loc['对照组', 'revenuePerSale'])))treatment_rr = gamma(a=(1 + results.loc['实验组', 'converted']), scale=(10/(1 + 0.1 * results.loc['实验组', 'converted']*results.loc['实验组', 'revenuePerSale'])))fig, ax = plt.subplots()x = np.linspace(0,4,5000)ax.plot(x, control_rr.pdf(x), label='对照组')ax.plot(x, treatment_rr.pdf(x), label='实验组')ax.set_xlabel('Rate Parameter')ax.set_ylabel('Density')ax.set_title('Experiment Posteriors')ax.legend()
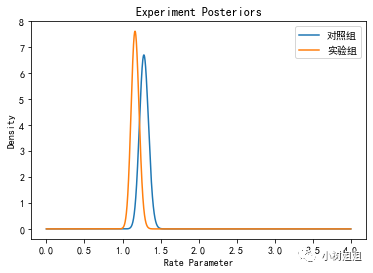
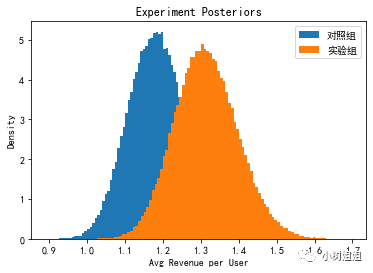
control_conversion_simulation = np.random.beta(7 + results.loc['对照组', 'converted'], 15 + results.loc['对照组', 'sampleSize'] - results.loc['对照组', 'converted'], size=100000)treatment_conversion_simulation = np.random.beta(7 + results.loc['实验组', 'converted'], 15 + results.loc['实验组', 'sampleSize'] - results.loc['实验组', 'converted'], size=100000)control_revenue_simulation = np.random.gamma(shape=(1 + results.loc['对照组', 'converted']), scale=(10/(1 + (0.1)*results.loc['对照组', 'converted']*results.loc['对照组', 'revenuePerSale'])), size=100000)treatment_revenue_simulation = np.random.gamma(shape=(1 + results.loc['实验组', 'converted']), scale=(10/(1 + (0.1)*results.loc['实验组', 'converted']*results.loc['实验组', 'revenuePerSale'])), size=100000)control_avg_purchase = [i/j for i,j in zip(control_conversion_simulation, control_revenue_simulation)]treatment_avg_purchase = [i/j for i,j in zip(treatment_conversion_simulation, treatment_revenue_simulation)]fig, axx = np.linspace(0,4,1000)ax.hist(control_avg_purchase, density=True, label='对照组', histtype='stepfilled', bins=100)ax.hist(treatment_avg_purchase, density=True, label='实验组', histtype='stepfilled', bins=100)ax.set_xlabel('Avg Revenue per User')ax.set_ylabel('Density')ax.set_title('Experiment Posteriors')ax.legend()


推荐阅读
评论