
模仿并超越人类围棋手,KL正则化搜索让AI下棋更像人类,Meta&CMU出品
点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达
晓查 发自 凹非寺
量子位 报道 | 公众号 QbitAI
如果非要问AlphaGo有什么缺点,那就是下棋不像人类。
和AlphaGo对弈过的顶级棋手都有这种感受,他们觉得AI落子经常让人捉摸不透。

这不仅是AlphaGo的问题,许多AI系统无法解释,且难以学习。如果想让AI与人类协作,就不得不解决这个问题。
现在,来自Meta AI等机构的研究者们打造出一个能战胜人类顶级棋手、且更容易复盘棋谱的AI。

他们用人类棋谱训练AI模仿,并让后者超越了人类。
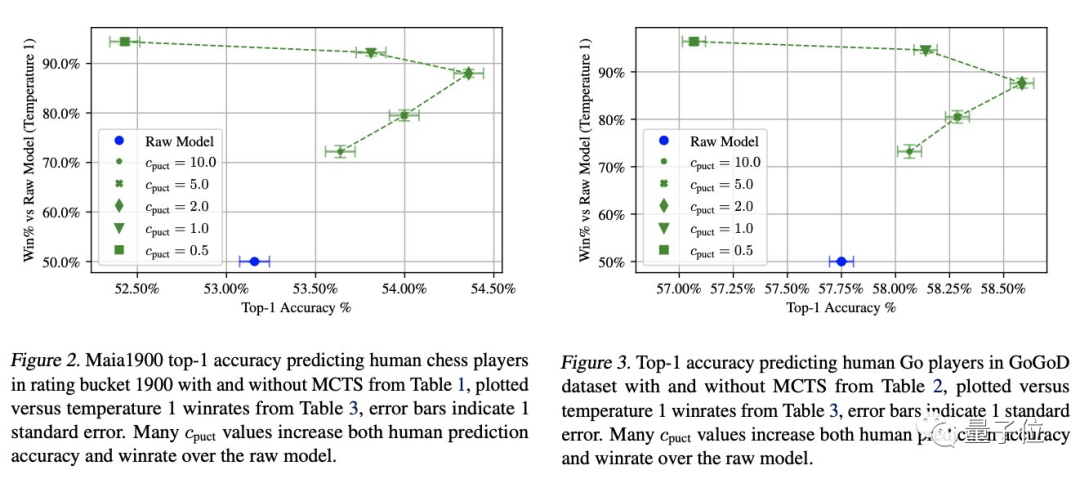
上图分别展示了该方法在国际象棋(左)、围棋(右)的表现。
纵轴为AI与原始模型对弈的胜率,横轴为AI预测人类落子位置的Top-1准确度。可以看出新的算法(绿色)在两方面都已经超过了SOTA结果(蓝色)。
像人类,还能打败人类
正所谓“鱼与熊掌难以兼得”。
AlphaGo使用的自我博弈与蒙特卡洛树搜索(MCTS),虽然练就了无比强大的AI,但它的下棋更像凭直觉,而非策略。
如果要让AI更像人类,更应当使用模仿学习(Imitative learning),但是这却很难让AI达到人类顶级棋手水准。
Meta AI和CMU的研究者发现,加入了KL正则化搜索后,一切都不一样了。AI的落子策略变得与人类棋手更加相似,这就是他们提出的新方法。
在国际象棋、围棋和无合作的博弈游戏中,这种方法在预测人类的准确性上达到了SOTA水平,同时也大大强于模仿学习策略。
作者选择了遗憾最小化算法(regret minimization algorithms)作为模仿学习的算法,但是非正则化遗憾最小化算法在预测人类专家行为方面的准确性较低。
因此作者引入了新的方法,引入了与搜索策略和人类模仿学习的锚策略之间的KL散度成正比的成本项。此算法被称为策略正则化对冲,简称piKL-hedge。
piKL-hedge的执行步骤如下:
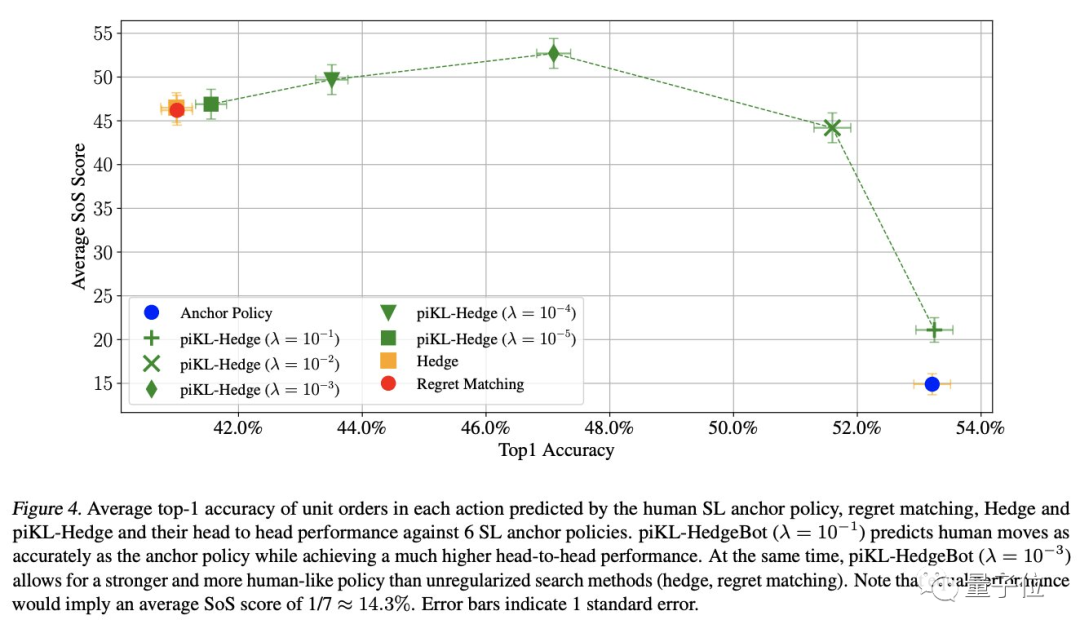
在下图中,piKL-Hedge(绿色)可以生成预测人类博弈的策略,其准确度与模仿学习(蓝色)相同,同时性能强1.4倍。
另一方面,在实现更高预测准确性的同时,piKL-Hedge优于非正则化搜索(黄色)的策略。
作者团队简介
本文共有三位共同一作,分别是来自Meta AI的Athul Paul Jacob、David Wu,以及CMU的Gabriele Farina。

Athul Paul Jacob同时也是MIT CSAIL的二年级博士生,从2016年到2018年,他还在Mila担任访问学生研究员,在Yoshua Bengio手下工作,与Bengio共同发表了多篇论文。
David Wu是Meta AI的国际象棋和围棋首席研究员。
Gabriele Farina是CMU一名六年级博士生,曾是2019-2020年Facebook经济学和计算奖学金的获得者,他的研究方向是人工智能、计算机科学、运筹学和经济学。
另外,Gabriele Farina还参与过著名的CMU德州扑克AI程序Libratus的开发。
论文地址:
https://arxiv.org/abs/2112.07544
— 完 —
本文系网易新闻•网易号特色内容激励计划签约账号【量子位】原创内容,未经账号授权,禁止随意转载。

点个在看 paper不断!