
Panda处理文本和时序数据?首选向量化
导读
Pandas作为Python数据分析的首选框架,不仅功能强大接口丰富,而且执行效率也相比原生Python要快的多,这是得益于Pandas底层由C实现,同时其向量化执行方式也非常利于并行计算。更重要的是,这种向量化操作不仅适用于数值计算,对于文本和时间格式也有着良好的支持,而这就不得不从Pandas的属性接口谈起。

Pandas中的向量化,就像6个Pandas一样
说起Pandas中的属性接口,首先要从数据类型谈起。在任何一门编程语言中,虽然各自的数据类型有很多,比如数值型有int、long、double,字符串有str或者char类型,还有时间数据类型以及布尔数据类型等,可以说这数值型、字符串型、时间型以及布尔型基本覆盖了所有基本的数据类型。而像其他的数组、列表、字典等则都是集合类的数据结构,不属于基本数据类型。
数值型操作是所有数据处理的主体,支持程度自不必说,布尔型数据在Pandas中其实也有较好的体现,即通过&、|、~三种位运算符也相当于是实现了向量化的并行操作,那么对于字符串和时间格式呢?其实这就是本文今天要分享的重点内容:属性接口——str、dt,两类接口均用几个小例子简单粗暴的进行示范,即学即用!
严格意义上讲,Pandas中的属性接口除了str和dt外,还有枚举类型cat接口,但其实用法很小众,所以本文不予提及。
在Pandas中,当一列数据类型均为字符串类型时,则可对该列执行属性接口操作,即通过调用.str属性可调用一系列的字符串方法函数,其中这里的字符串方法不仅涵盖了Python中内置的字符串通用方法,比如split、strim等,还实现了正则表达式的绝大部分功能,包括查找、匹配和替换等、这对于Pandas处理文本数据来说简直是开挂一般的存在。
举个例子,例如构造如下虚拟DataFrame数据,其中所有列都用到了字符串类型:
df = pd.DataFrame({"name":['GuanYu', 'zhangFei', 'zhao-yun', 'machao', 'huangzhong#'],"city":['湖北省荆州市', '四川省汉中市', '四川省成都市', '甘肃省西凉区', '四川省成都市'],"salary":['30-50K', '30-50k', '30-45k', '30-40k', '30-40k'],"helpers":['关平 周仓 廖化 马良', '张苞 魏延', '马云禄', '马岱 庞德', '严颜']})
对应数据表如下:
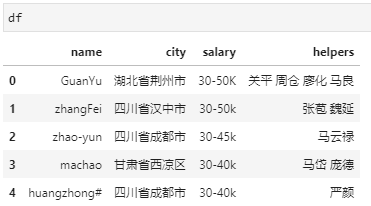
观察数据可见,name列字符串格式不是很统一,既有大小写混乱,也有-、#等其他无用字符,city列相对规整,但马超所在列不是xx省xx市结构,而salary均有薪资上下限组成,最后helpers列则是一个复合类型,各部下之间用空格进行区分。针对这一数据,需要完成如下处理需求:
规整姓名列,均变为小写形式且过滤无用字符
提取所在城市信息
计算平均薪资
提取部下人数信息
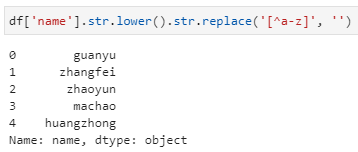
姓名列统一小写,然后过滤掉非字母的字符,其中lower是Python字符串内置的通用方法,replace虽然是Pandas中的全局方法,但嵌套了一层str属性接口后即执行正则匹配的替换,这里即用到了正则表达式的匹配原则,即对a-z字母以外的其他字符替换为空字符:
根据正则表达式,提取省市之间的城市信息,特别地,第二个关键词还可能是区,所以可用正则表达式中的findall提取功能,还需注意提取的限定关键字为前面以"省"开头、后面以"市"或"区"结束的中间字符,即是城市信息:

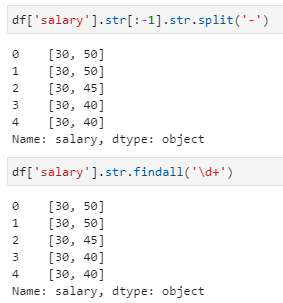
计算平均薪资。由于这里的薪资字段其实还是比较规整的,即都是以K结尾(虽然可能有大小写之别),薪资上下限用-连接,所有其实有多种方法可以实现,这里举例其中的两种,其中第一种用到了字符串的切分函数,第二种方法仍然是正则匹配查找。两种方法均实现了两个数字的提取,进而可以完成上下限的均值计算。
最后是提取下属信息,注意到这里的下属由一个字符串组成,且下属之间由空格间隔。针对这一需求,也可轻松实现两种解决方案,其中之一是进行拆分然后获取拆分后列表的长度、第二种是直接对字符串中空格进行计数,而后+1即为总的部下人数。两种方案结果是一致的:

以上,举了几个简单的例子对pandas中的字符串属性接口str进行了牛刀小试,其中包括python内置的字符串函数split、count、len等,也包括findallreplace中嵌套正则表达式等用法,灵活运用起来效率真的是可以起飞……

基本都是Python中常用的字符串函数,调用时只需在一个字符串列后调用str即可,方法简单,但效率却是异常明显的。
与str用法极其类似、对时间类型的数据处理极为友好的另一个属性接口是dt,即datetime的简称,要求适用于格式是时间类型的数据。由于时间类型在某些特定应用场景还是非常常用的,所以灵活运用dt属性接口也可实现非常便捷的数据处理操作。
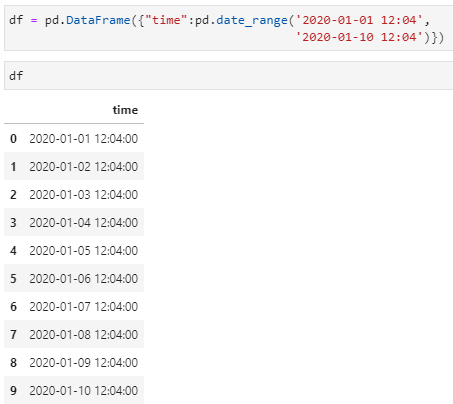
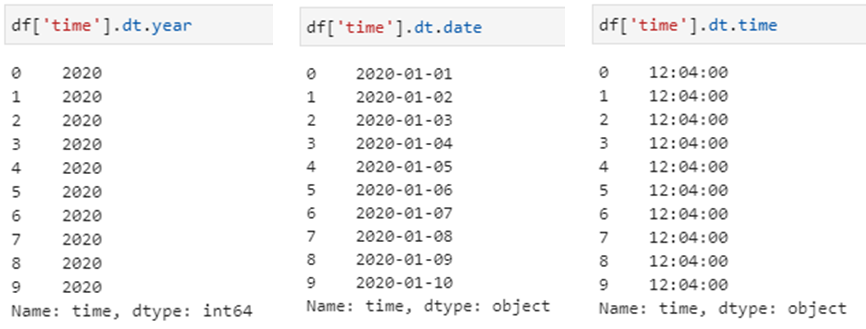
这里需要注意的是,在前述str属性接口中,多数dt后面接的都是函数,而这里获取的year、date和time等都是属性(因为无需参数),二者的区别体现为函数以()结尾,而属性则无需括号。


基本上,时间格式中想得到的、想不到的基本都给予了实现,用来提取个时间信息简直是太方便了。
一门编程语言中的基本数据类型无非就是数值型、字符串型、时间型以及布尔型,Pandas为了应对各种数据格式的向量化操作,针对字符串和时间格式数据专门提供了str和dt两个属性接口(数值型数据天然支持向量化操作,而布尔型也可通过位运算符&、|、~实现并行计算),通过调用属性接口后的系列方法,可以实现丰富的API以及高效的计算能力。尤其是字符串型数据,除了Python中通用的字符串方法外,还集成了正则表达式处理逻辑。
另外,除了str和dt两个属性接口外还有一个枚举属性接口cat(即category缩写),但实际上用处较为局限。
至此,Pandas应用小技巧系列文章已经推出了大部分,后续将视情整理一篇合集,敬请期待。
相关阅读: