
文本向量化的六种常见模式

向AI转型的程序员都关注了这个号👇👇👇
一、文本向量化
文本向量化:将文本信息表示成能够表达文本语义的向量,是用数值向量来表示文本的语义。词嵌入(Word Embedding):一种将文本中的词转换成数字向量的方法,属于文本向量化处理的范畴。向量嵌入操作面临的挑战包括:
(1)信息丢失:向量表达需要保留信息结构和节点间的联系。
(2)可扩展性:嵌入方法应具有可扩展性,能够处理可变长文本信息。
(3)维数优化:高维数会提高精度,但时间和空间复杂性也被放大。低维度虽然时间、空间复杂度低,但以损失原始信息为代价,因此需要权衡最佳维度的选择。
常见的文本向量和词嵌入方法包括独热模型(One Hot Model),词袋模型(Bag of Words Model)、词频-逆文档频率(TF-IDF)、N元模型(N-Gram)、单词-向量模型(Word2vec)、文档-向量模型(Doc2vec)
二、独热编码
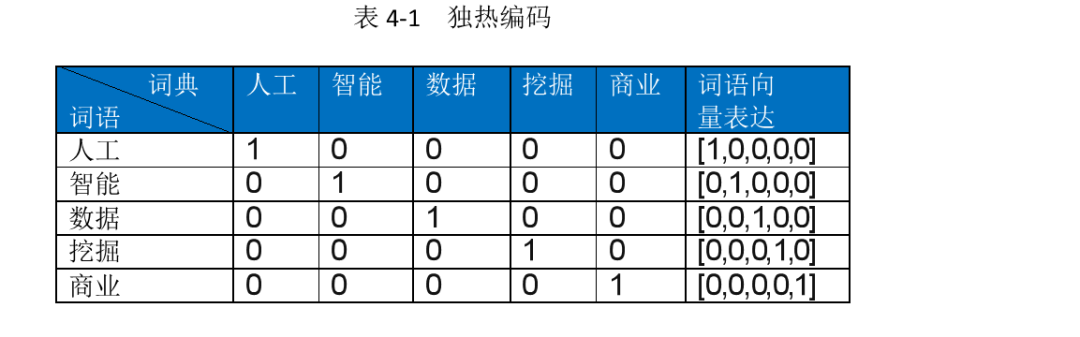
One-hot编码采用N位状态寄存器来对N个状态进行编码,是分类变量作为二进制向量的表述。
首先根据提供的文本构建词典,其中的数字可以视作对应词语的标签信息或者事物的分类信息
然后基于独热编码表达法,构造一个N维向量,该向量的维度与词典的长度一直,对于给定词语进行向量表达时,其在词典中出现的响应位置的寄存器赋值为1,其余为0 示例如下
三、词袋模型
词袋模型(Bag-of-words model:BOW)假定对于给定文本,忽略单词出现的顺序和语法等因素,将其视为词汇的简单集合,文档中每个单词的出现属于独立关系,不依赖于其它单词。先将句子向量化,句子维度和字典维度一致,第 i 维上的数字代表 ID 为 i 的词语在该句子里出现的频率。

四、词频-逆文档频率模型
TF-IDF(term frequency-inverse document frequency)是数据信息挖掘的常用统计技术。TF(Term Frequency)中文含义是词频,IDF(Inverse Document Frequency)中文含义是逆文本频率指数。
词频统计的是词语在特定文档中出现的频率,而逆文档频率统计的是词语在其他文章中出现的频率,其处理基本逻辑是词语的重要性随着其在特定文档中出现的次数呈现递增趋势,但同时会随着其在语料库中其他文档中出现的频率递减下降 数学表达式如下
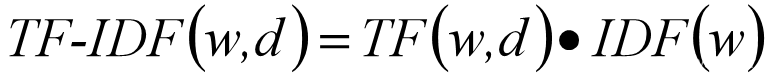
五、N元模型
N-Gram语言模型基本思路是基于给定文本信息,预测下一个最可能出现的词语。N=1称为unigram,表示下一词的出现不依赖于前面的任何词;N=2称为bigram,表示下一词仅依赖前面紧邻的一个词语,依次类推。
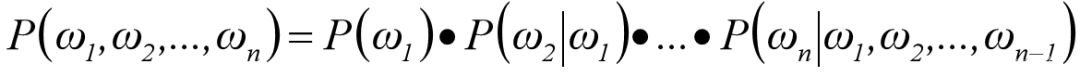
六、单词-向量模型
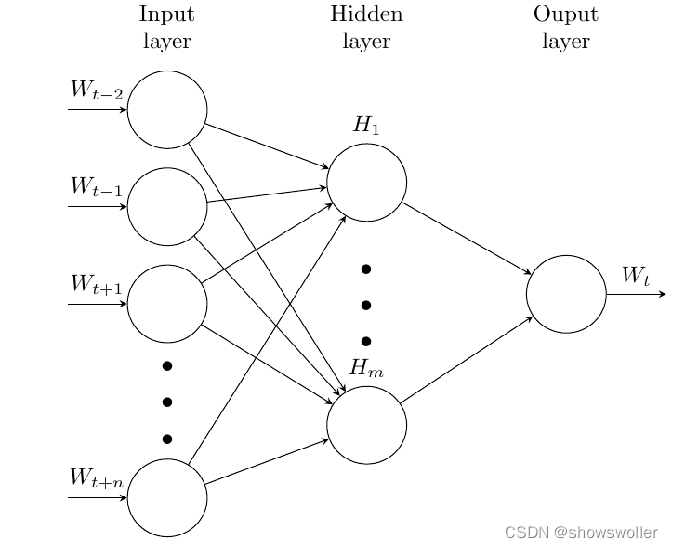
将不可计算、非结构化的词语转化为可计算、结构化的向量。word2vec模型假设不关注词的出现顺序。Word2Vec包含连续词袋模型CBOW(Continues Bag of Words)和Skip-gram模型两种网络结构。训练完成之后,模型可以针对词语和向量建立映射关系,因此可用来表示词语跟词语之间的关系
CBOW模型如下
机器学习算法AI大数据技术
搜索公众号添加:
datanlp
长按图片,识别二维码
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加:
datayx