
Java并发容器那么多,应该怎么选?
“ 写给自己看,说给别人听。你好,这是think123的第86篇原创文章”
我们先来看看有哪些并发容器
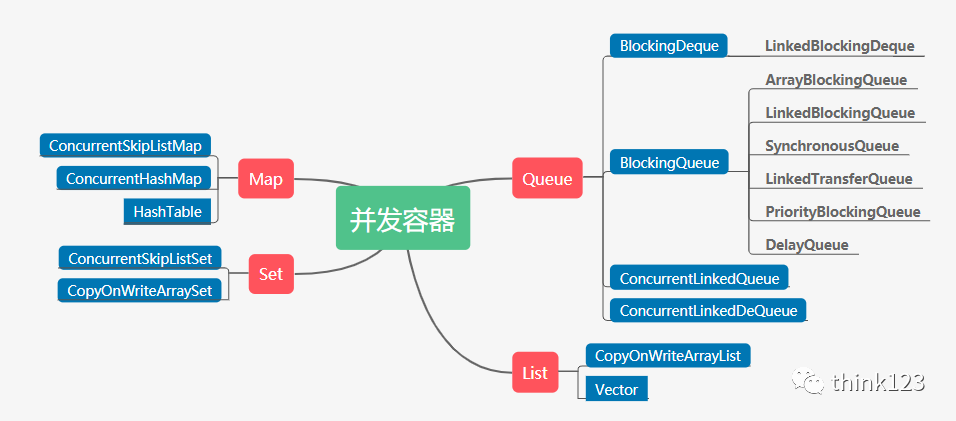 并发容器
并发容器这么多容器,我们该怎么选? 虽然不能全要,但是我们可以都了解一下,然后挑选适合自己的。
并发下的Map
我们都知道不能再并发场景下使用HashMap,因为在JDK7之前,在并发场景下使用 HashMap 会出现死循环,从而导致 CPU 使用率居高不下,而扩容是导致死循环的主要原因。
虽然 Java 在 JDK8 中修复了 HashMap 扩容导致的死循环问题,但在高并发场景下,依然会有数据丢失以及不准确的情况出现。
HashMap扩容出现死循环的分析可以查看我之前的文章
为了保证线程安全,安全的Map对象 Hashtable、ConcurrentHashMap 以及ConcurrentSkipListMap 三个容器
Hashtable 和 ConcurrentHashMap 都是基于 HashMap 实现的,对小数据量的存取比较有优势。
ConcurrentSkipListMap 是基于跳表实现的,其特点是存取平均时间复杂度是 O(log(n)),适用于大数据量存取的场景。
Hashtable VS ConcurrentHashMap
Hashtable在它所有的获取或者修改数据的方法上都添加了Synchronized,因此在高并发场景下,读写操作都会存在大量锁竞争,给系统带来性能开销。
ConcurrentHashMap 在保证线程安全的基础上兼具了更好的并发性能。
在 JDK7 中,ConcurrentHashMap 就使用了分段锁 Segment 减小了锁粒度,最终优化了锁的并发操作。
到了 JDK8,ConcurrentHashMap 做了大量的改动,摒弃了 Segment 的概念。由于Synchronized 锁在 Java6 之后的性能已经得到了很大的提升,所以在 JDK1.8 中,Java重新启用了 Synchronized 同步锁,通过 Synchronized 实现 HashEntry 作为锁粒度。
这种改动将数据结构变得更加简单了,操作也更加清晰流畅。
与 JDK7 的 put 方法一样,JDK8 在添加元素时,在没有哈希冲突的情况下,会使用CAS 进行添加元素操作;如果有冲突,则通过 Synchronized 将链表锁定,再执行接下来的操作。
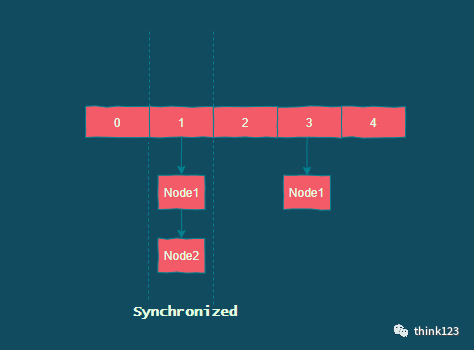 ConcurrentHashMap
ConcurrentHashMap虽然 ConcurrentHashMap 的整体性能要优于 Hashtable,但在某些场景中,ConcurrentHashMap 依然不能代替 Hashtable。
例如,在强一致的场景中ConcurrentHashMap 就不适用,原因是 ConcurrentHashMap 中的 get、size 等方法没有用到锁,因此返回的数据就不准确, ConcurrentHashMap 是弱一致性的,因此有可能会导致某次读无法马上获取到写入的数据
ConcurrentHashMap VS ConcurrentSkipListMap
我们都知道 ConcurrentHashMap 数据量比较大的时候,链表会转换为红黑树。红黑树在并发情况下,删除和插入过程中有个平衡的过程,会牵涉到大量节点,因此竞争锁资源的代价相对比较高。
而ConcurrentSkipListMap由于是基于跳表实现的,它需要锁住的节点要少一些,在高并发场景下性能也要好一些。
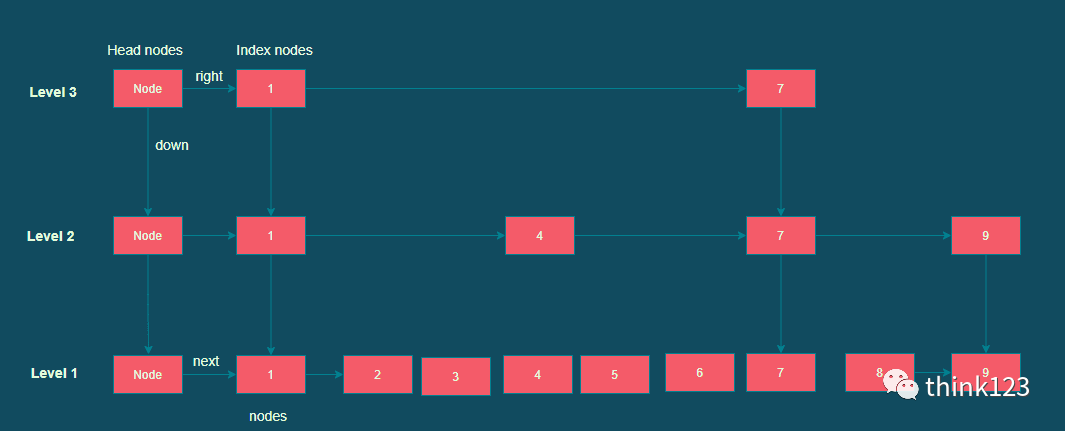 跳表
跳表跳跃表是基于链表扩展实现的一种特殊链表,类似于树的实现,跳跃表不仅实现了横向链表,还实现了垂直方向的分层索引。
一个跳跃表由若干层链表组成,每一层都实现了一个有序链表索引,只有最底层包含了所有数据,每一层由下往上依次通过一个指针指向上层相同值的元素,每层数据依次减少,等到了最顶层就只会保留部分数据了。
跳跃表的这种结构,是利用了空间换时间的方法来提高了查询效率。程序总是从最顶层开始查询访问,通过判断元素值来缩小查询范围。
java的实现中,往跳表中插入数据的时候,会根据概率随机算出level值,然后重建索引层,这里的代码还是比较有趣的
// 产生一个随机数
int rnd = ThreadLocalRandom.nextSecondarySeed();
// 0x80000001二进制为是10000000000000000000000000000001
// 只有随机数是正偶数才能决定是否要新增层级
if ((rnd & 0x80000001) == 0) {
int level = 1, max;
// 从随机数第二位开始,有几个连续的1,level值就加几
while (((rnd >>>= 1) & 1) != 0)
++level;
Index idx = null;
HeadIndex h = head;
// 层数小于等于当前跳表的最大层
if (level <= (max = h.level)) {
// 从第一层开始建立down的索引链表
for (int i = 1; i <= level; ++i)
idx = new Index(z, idx, null);
}
else {
// 超出了现有跳表的层数,则只加一层,多了没有意义
level = max + 1;
...
}
// 省略重建索引层代码
}
当新增一个 key 值为 7 的节点时,首先新增一个节点到最底层的链表中,根据概率算出level 值,再根据 level 值新建索引层,最后链接索引层的新节点。
新增节点和链接索引都是基于 CAS 操作实现
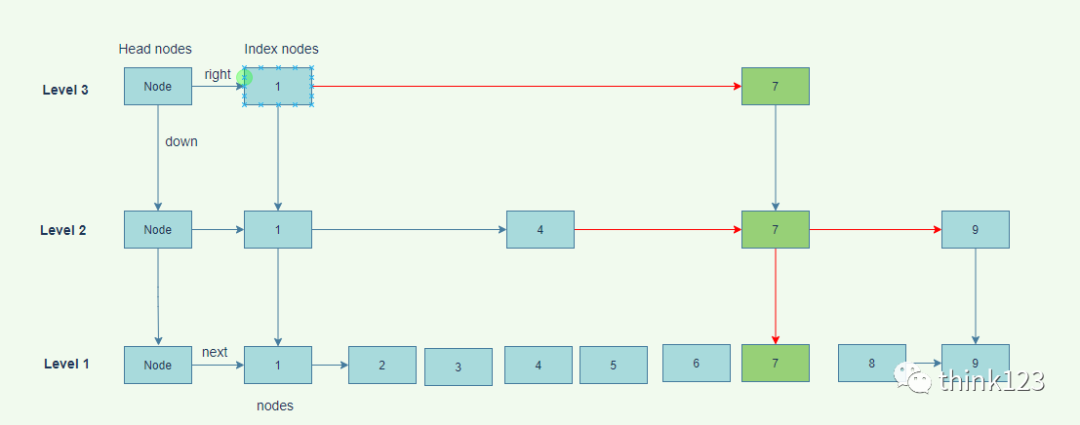 插入数据
插入数据当删除某个key 时,首先找到待删除结点,将其 value 值通过cas设置为 null;之后再向待删除结点的 next 位置新增一个marker(标记)结点,以便减少并发冲突。
然后让待删结点的前驱节点直接越过本身指向的待删结点,直接指向后继结点,中间要被删除的结点最终将会被JVM 垃圾回收处理掉;最后判断此次删除后是否导致某一索引层没有其它节点了,如果这一层都没有节点了则跳表层数降级。
经过上面的分析,我们可以知道当我们不需要知道集合中准确数据的时候使用ConcurrentHashMap,当我们需要知道集合中准确数据个数时,则需要用到HashTable。
如果数据量特别大,且存在大量增删改查操作,则可以考虑使用ConcurrentSkipListMap。
同时需要注意的是这三个线程安全的容器类key,value都不允许为null,而我们常使用的HashMap的key是可以为null,value不能为null的。
并发下的List
我们都知道Vector也是在它所有暴露出来的public方法中都加上了synchronized 关键字来保证线程安全,所以在读远大于写的操作场景中,Vector 将会发生大量锁竞争,
从而给系统带来性能开销。
而CopyOnWriteList实现了读操作无锁,写操作则通过操作底层数组的新副本来实现,是一种读写分离的并发策略,我们来看下源码是如何实现的
private transient volatile Object[] array;
public E get(int index) {
return get(getArray(), index);
}
private E get(Object[] a, int index) {
return (E) a[index];
}
可以看到读操作平平无奇,就是从数组中读取元素。
再看看写操作
public E set(int index, E element) {
final ReentrantLock lock = this.lock;
// 独占锁加锁
lock.lock();
try {
// 获取存储数据原始数组
Object[] elements = getArray();
E oldValue = get(elements, index);
// 设置新的数据
if (oldValue != element) {
int len = elements.length;
// 将旧数据复制到一个新的数组
Object[] newElements = Arrays.copyOf(elements, len);
// 将数据插入到新的数组中,并将新的数组设置为存储数据的数组
newElements[index] = element;
setArray(newElements);
} else {
// 重新设置数据,保证volatile写语义
setArray(elements);
}
return oldValue;
} finally {
lock.unlock();
}
}
从源码中我们知道了 CopyOnWriteList 就是当需要写入数据的时候,复制一个新的数组,将数据写入到新的数组中,再将新的数组赋值给旧数组。
所以 CopyOnWriteList 更适用于读远大于写的操作,同时业务场景对写入数据的实时获取并没有要求,只需要保证最终能获取到写入数组中的数据就可以了。
并发下的Set
CopyOnWriteArraySet是使用CopyOnWriteArrayList实现的,而 ConcurrentSkipListSet 又是使用 ConcurrentSkipListMap实现的,而这两者区别可以分别参考它们的实现。这里就不重复说明了。
并发下的Queue
Java并发包中Queue这类并发容器是最复杂的,并不是说实现多复杂,而是它的类比较多,记起来复杂。不过它仍然可以从两个维度来分类。
一个维度是阻塞与非阻塞,所谓阻塞指的是当队列已满时,入队操作阻塞;当队列已空时,出队操作阻塞。
另一个维度是单端与双端,单端指的是只能队尾入队,队首出队;而双端指的是队首队尾皆可入队出队。
Java 并发包里阻塞队列都用 Blocking 关键字标识,单端队列使用 Queue 标识,双端队列使用 Deque 标识。
两个维度可以双双组合,将 Queue 细分为4大类。
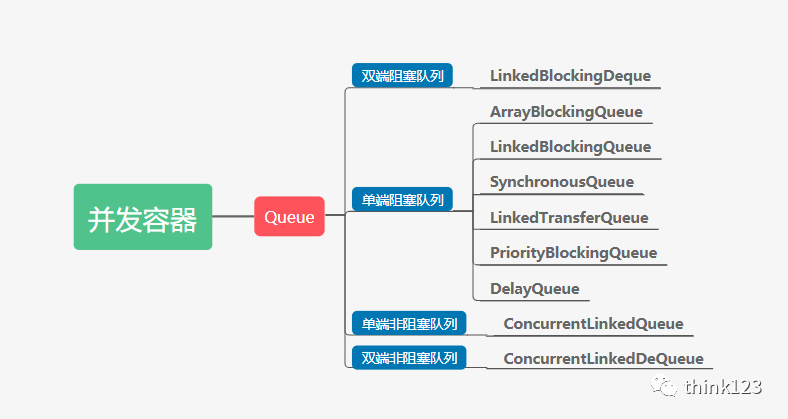 4大类队列
4大类队列单端阻塞队列
单端阻塞队列内部一般会持有一个队列,这个队列可能是数组(ArrayBlockingQueue)也可以是链表(LinkedBlockingQueue)。
甚至还可以不持有队列(其实现是 SynchronousQueue),此时生产者线程的入队操作必须等待消费者线程的出队操作。
需要注意的是需要调用put/take方法队列才会阻塞,add,offer方法是不会阻塞的。
ArrayBlockingQueue 首先使用的是数组来实现队列,然后阻塞功能则是借助 ReentrantLock 和 Condition 来实现的。
LinkedBlockingQueue 则是借助的链表来实现队列, 阻塞功能也是借助 ReentrantLock 和 Condition 来实现的,和 ArrayBlockingQueue 还有一个不同之处在于 LinkedBlockingQueue 中 put 和 take 分别使用了不同的 ReentrantLock, 这样做的原因是 put的时候会将元素添加到队列尾,take的时候则是从队列头移除。
SynchronousQueue 也作为阻塞队列在线程池中出现过,它用于在两个线程之间直接移交元素,一个线程生产了数据,另一个线程才能消费数据。
虽然它内部没有缓冲,但是如果同一个模式(生产或者消费)的线程过多,它们都会被存储起来,然后被阻塞,所以它更适合生产和消费速率相当的情况下使用。
PriorityBlockingQueue 支持按照优先级出队,其底层实现就是 PriorityQueue + ReentrantLock ,关于PriorityQueue可以参考我的这篇 优先级队列源码解析
DelayQueue 是一个支持延时获取元素的阻塞队列,其使用 PriorityQueue(存储元素) + ReentrantLock 实现,同时元素必须实现 Delayed 接口。在创建元素时可以指定多久才可以从队列中获取当前元素,只有在延迟期满时才能从队列中提取元素。我们可以使用它实现定时调度和缓存系统。
LinkedTransferQueue 融合 LinkedBlockingQueue 和 SynchronousQueue 的功能,性能比 LinkedBlockingQueue 更好,它底层数据结构采用的是双队列(dual queue)。
消费者线程取元素时,如果队列为空,那就生成一个节点(节点元素为null)入队,然后消费者线程park住,后面生产者线程入队时发现有一个元素为null的节点,生产者线程就不入队了,直接就将元素填充到该节点,唤醒该节点上park住线程,被唤醒的消费者线程就能获取到该节点上的数据了。
如果是生产者插入元素时,如果队列为空,就生成一个数据节点入队,然后立即返回,并不会阻塞。
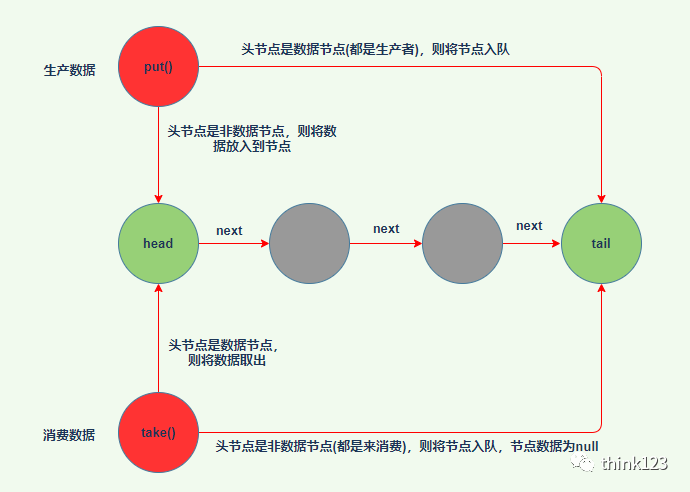 LinkedTransferQueue
LinkedTransferQueue双端阻塞队列
双端阻塞队列的实现是 LinkedBlockingDeque, 它和 LinkedBlockingQueue 的实现类似,只是一个这个是双端。
单端非阻塞队列
实现是 ConcurrentLinkedQueue, 从队尾插入数据,从队头取出数据。均是通过CAS来更新head, tail的指向,所以不会阻塞线程,但是如果并发太激烈会导致CPU空转。
双端非阻塞队列
实现是 ConcurrentLinkedDeque。和 ConcurrentLinkedQueue 实现类似,只是它是双端队列。
通过上面的分析还可以知道,阻塞就用到了锁,会阻塞线程。
非阻塞使用的是CAS的方式,不会阻塞线程,但是在并发很大的情况下,会使得CPU使用率过高。
使用队列时,需要格外注意队列是否支持有界(所谓有界指的是内部的队列是否有容量限制)。实际工作中,一般都不建议使用无界的队列,因为数据量大了之后很容易导致OOM。
上面提到的这些 Queue 中,只有 ArrayBlockingQueue 和 LinkedBlockingQueue 是支持有界的,所以在使用其他无界队列时,一定要充分考虑是否存在导致 OOM 的隐患。
写到最后
分析了这些容器的特点以及实现,我相信大家一定有自己的选择了。