
无监督学习?Yann LeCun说:或许应该叫它预测性学习

新智元报道
新智元报道
来源:danrose
编辑:白峰
【新智元导读】随着机器学习的不断发展,无监督学习在近年来备受关注。Yann LeCun提出赋予无监督学习新的名字——预测性学习。

监督学习、无监督学习和强化学习:机器学习的三驾马车
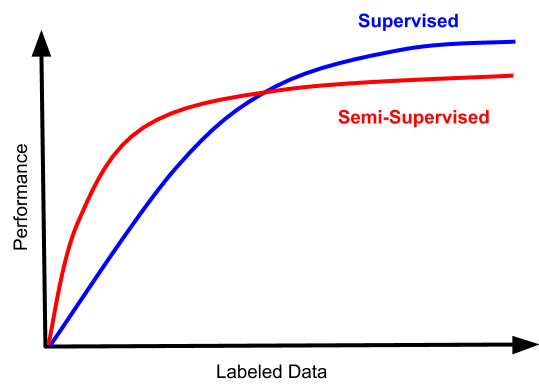
昂贵且复杂的数据标记让监督学习变得困难

无监督学习(预测性学习)正在登上历史舞台
正如Yann LeCun所说,无监督学习是「填补空白」。填补空白不仅仅是将相似的事物归类,填补空白就像是想象。 在训练预测学习模型时,目的是了解当前的世界。

「预测性学习」可能会改变我们的未来

评论