
强化一波 hooks,这次咱们换个发力点
大厂技术 高级前端 Node进阶
点击上方 程序员成长指北,关注公众号
回复1,加入高级Node交流群
首先hooks已经推出很久,想必大家或多或少都使用过或者了解过hooks,不知是否会和我一样都有一种感受,那就是hooks使用起来很简单,但总感觉像是一种魔法,并不是很清楚其内部如何实现的,很难得心应手,所以我觉得要想真正驾驭hooks,应该先从了解其内部原理开始,再讲使用,试着建立从原理到使用的一条细细的通路。
hooks扭转了函数组件的局势
hooks 之前
函数组件的基因限制
函数组件可以粗略的认为就是类组件的render函数,即一个返回jsx从而创建虚拟dom的函数。
类组件有this,能够拥有自己的实例方法,变量,这样很容易就可以实现各种特性,比如state和生命周期函数,每一次渲染都可以认为是“曾经"的自己在不断脱变,有延续性。
反观函数组件就无法延续,每一次渲染都是“新”的自己,这就是函数组件的“基因限制”,有点像章鱼。
函数组件和类组件一个“小差异”
首先一个组件可以分别用类组件和函数组件写出两个版本,对吧
类组件:
class CompClass extends Component {
showMessage = () => {
console.log("点击的这一刻,props中info为 " + this.props.info);
};
handleClick = () => {
setTimeout(this.showMessage, 3000);
console.log(`当前props中的info为${this.props.info},一致就说明准确的关联到了此时的render结果`)
};
render() {
return <div onClick={this.handleClick}>
<div>点击类组件div>
div>;
}
}
复制代码
函数组件:
function CompFunction(props) {
const showMessage = () => {
console.log("点击的这一刻,props中info为 " + props.info);
};
const handleClick = () => {
setTimeout(showMessage, 3000);
console.log(`当前props中的info为${props.info},一致就说明准确的关联到了此时的 render结果`)
};
return <div onClick={handleClick}>点击函数组件div>;
}
复制代码
那也就说这两者不同写法是等价的,对么?
答案是:通常情况下是等价的,但是有种情况二者不同,比如
export default function App() {
const [info, setInfo] = useState(0);
return (
<div>
<div onClick={()=>{
setInfo(info+1)
}}>父组件的info信息>> {info}div>
<CompFunction info = {info}>CompFunction>
<CompClass info = {info}>CompClass>
div>
);
}
复制代码
通过代码能够看出:
在组件 App中,有个状态info其初始值为0,并且可以通过点击修改CompFunction和CompClass是作为子组件显示,并且都接受父组件的info作为参数,这两个组件都有一个点击回调,点击之后都会触发一个延迟3秒的 setTimeout,然后把从父组件App中获得info,log出来
那就操作一下:
就是快速点击 CompFunction和CompClass,以触发其内部的setTimeout,等待3秒之后,看看打印从父组件App中获得info信息然后再点击父组件进而修改 info,只要变了就行,假设变成了5。
(建议动手试一下。)
结果:
函数组件 CompFunction会输出:0类组件 CompClass会输出:5
结果不同,按道理讲应该等价啊,为什么不同呢?
解释:
函数组件执行,就会形成一个闭包,可以形象地说成render结果,其中包括props,而点击事件的处理函数同样也包括在内,那它无论是立即执行还是延迟执行,都应该与触发执行的那一刻的render结果(你也可以理解为那一刻的快照)相关联。所以回调函数showMessage所应该log出的info,应该为事件触发的那一刻render结果中的info,也就是"1",无论外部的info怎么变。
而类组件就会输出info的最新值,也就是"5"。
结论:
这个“小差异”就叫做capture value
每次 Render 的内容都会形成一个快照并保留下来,因此当状态变更而 Rerender 时,就形成了 N 个 Render 状态,而每个 Render 状态都拥有自己固定不变的 Props 与 State。[1]
class组件想做到这一点,多少有点难,毕竟this这个奶酪被React给动了。
capture value是一把双刃剑,不过没关系有办法解决(后面会讲)
hooks 之后
hooks让这个“render”函数成精了
如果说在hooks之前,函数组件有一些“硬伤”,其独特之处不足以支撑它与类组件分庭抗礼,但是当hooks的到来之后,橘势就不一样了,这个曾经的“render”函数一下就走起来了。
hooks帮函数组件打碎了基因锁。
我们之前聊了,函数组件最大的硬伤就是"次次重来,无法延续" ,很难让它具备跟类组件那样的能力,比如用状态和生命周期函数,而如今hooks的加持,很好的粉碎了被类组件克制的枷锁。
所以说在了解如何使用hooks之前,最好要先了解函数组件是怎么拥有了延续性,这样使用hooks就”有谱“,否则你就会觉得hooks到处都是黑魔法,这么整就不是很”靠谱“了。
想要了解Hooks延续的奥秘,你可能得认识一下Fiber
没有延续性,遑论其他,真正让函数组件有延续性的幕后真大佬实际上是Fiber,为了能够很好的了解React怎么实现的这么多种hooks,那么Fiber你是绕不开的,不过学习Fiber不用太用力,点到为止,我会尽可能的浅出,我们的目标就是能够更好的理解和使用Hooks,毕竟吃饺子嘛,不用非得那么清楚怎么做的。
fiber 的结构
type Fiber = {
// 函数组件记录以链表形式存放的hooks信息,类组件存放`state`信息
memoizedState: any,
// 将diff得出的结果提交给的那个节点
return: Fiber | null,
// 单链表结构 child:子节点,sibling:兄弟节点
child: Fiber | null,
sibling: Fiber | null,
...
// 每个workinprogress都维护了一个effect list(很复杂,不会也不耽误我们吃饺子)
nextEffect: Fiber | null,
firstEffect: Fiber | null,
lastEffect: Fiber | null,
...
}
复制代码
Fiber 的由来
React到底是如何将项目渲染出来的。
首先这个过程称为“reconciler”,可以先粗略讲reconciler划分出两个阶段。
reconciliation :通过diff获得变动的结果。 commit:将变动作用到画面上( side effect即副作用,如dom操作)。
reconciliation是异步的,commit是同步的。
在fiber之前,React是如何实现的reconciliation
从头创建一个新的虚拟dom即vdom,与旧的vdom进行比对,从而得出diff结果,这个过程是递归,需要一气呵成,不能停的,这样JavaScript长时间的占用主线程,就会阻塞画面的渲染,就很卡。
因为JavaScript在浏览器的主线程上运行,恰好与样式计算、布局以及许多情况下的绘制一起运行。如果JavaScript运行时间过长,就会阻塞这些其他工作,可能导致掉帧。
(引自Optimize JavaScript Execution[2])
那么可以说,旧的方式暴露了两点问题:
自顶向下遍历,不能停。 React长时间的执行耽误了浏览器工作。
vdom进化成为Fiber
Fiber可以理解为将上述整个reconciliation工作拆分了,然后通过链表串了起来,变成了一个个可以中断/挂起/恢复的任务单元。并且结合浏览器提供的requestIdleCallback API(有兴趣可以了解)进行协同合作。
Fiber核心是实现了一个基于优先级和requestIdleCallback的循环任务调度算法。(参考:fiber-reconciler[3])
直白的说:就一碗面条,一双筷子,以前React吃的时候,浏览器只能看着,现在就变成React吃一口换浏览器吃一口,一下就和谐了。
Fiber就是按照vdom来拆分的,一个vdom节点对应一个Fiber节点,最后形成一个链表结构的fiber tree,大体如图:
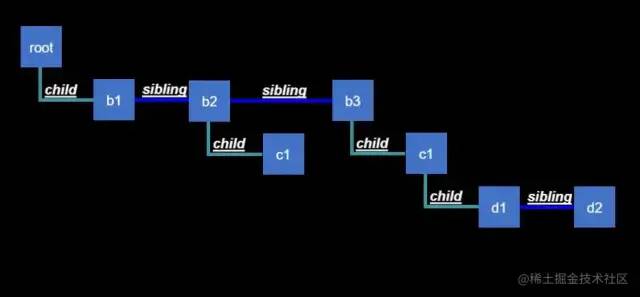
child:指向子节点的指针 sibling:指向兄弟节点指针 return:提交变动结果(effectList)到指定的目标节点(图中没标示,下文会有动态演示)
所以说Fiber tree就是可切片的vdom tree都不为过。
那么vdom还存在么?
这个问题我思考了很久,请原谅这方面的源码我还没看透,我现在通过查阅多篇相关的文章,得出了一个我能接受,逻辑能自洽的解释:
Fiber出来之后,vdom的作用只是作为蓝本进行构建Fiber树。
em~,龙珠熟悉吧,vdom就好像是超级赛亚人1之前够用了,现在不行了,进化到了超级赛亚人2,即Fiber。
Fiber是如何工作的
首先我已经知道,Fiber tree是一个链表结构,React是通过循环处理每个Fiber工作单元,在一段时间后再交还控制权给浏览器,从而协同的合作,让页面变得更加流畅。
要弄清函数组件怎么有的延续性的答案就藏在了这个工作循环中。
探索一下workLoop
为了能够摆脱又困又长的源码分析,可以试着先简单的理解workLoop。
首先Loop啥呢?
工作单元,即work。
work又可以粗略的分为:
beginWork:开始工作 completeWork:完成工作
那么结合之前的Fiber tree,看一下
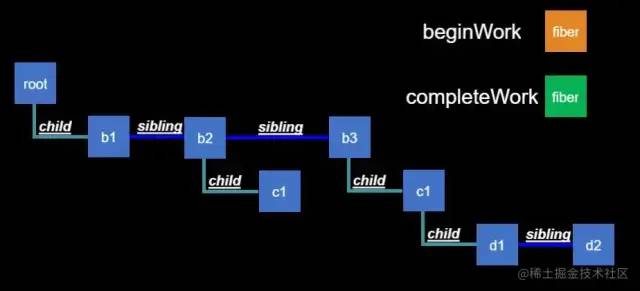
那么看下大体的运转过程:
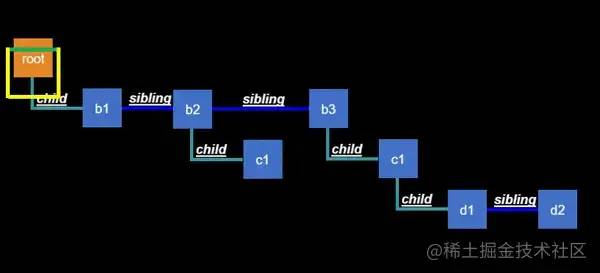
那么通过动画我初步了解了整个workLoop的流转过程,简单描述下:
自顶 root向下,流转子节点b1b1开始 beginWork,工作目标根据情况diff处理,获得变动结果(effectList),然后判断是是否有子节点,没有那结束工作completeWork,然后流转到兄弟节点b2b2开始工作,然后判断有子节点c1,那就流转到c1c1工作完了,completeWork获得effectList,并提交给b2然后 b2完成工作,流转给b3,那么b3就按照这套路子,往下执行了,最后执行到了最底部d2最后随着光标的路线,一路整合各节点的 effectList,最后抵达Root节点,第1阶段-reconciliation结束,准备进入Commit阶段
再进一步,“延续”的答案就快浮出水面了
我们已经大致的了解了workLoop,但还不能解释函数组件怎么“延续”的,我们还要再深入了解,那么再细致一点分解workLoop,实际上是这样的:
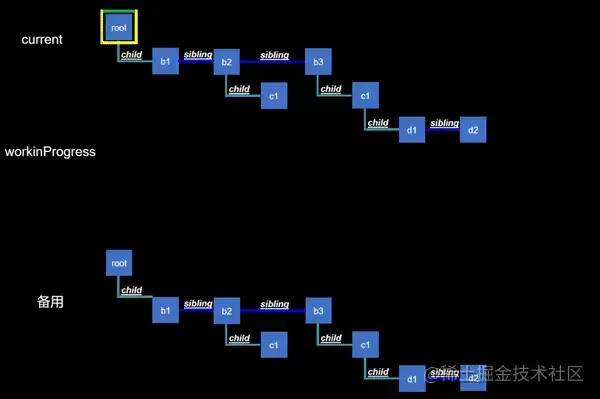
(动画中“current”和“备用”是一体,为了看起来容易理解:“构建wip树是尽可能服用current树”,动画结束时,current再用备用来描述,以表达current树是作为备用的)
描述一下过程:
根据 current fiber treeclone出workinProgress fiber tree,每clone一个workinProgress fiber都会尽可能的复用备用fiber节点(曾经的current fiber)当构建完整个 workinProgress fiber tree的时候,current fiber tree就会退下去,作为备用fiber节点树,然后workinProgress fiber tree就会扶正,成为新的current fiber tree然后就将已收集完变动结果( effect list)的新current fiber tree,送去commit阶段,从而更新画面
其中几个点我要注意:
current fiber tree为主决定屏幕上显示内容,workinProgress fiber tree为辅制作完毕成为下一个current fiber tree构建 workinProgress fiber tree的过程,就是diff的过程,主要的工作都是发生在workinProgress fiber上,有变动就会维护一个effect list,当完成工作的时候就会提交格给return所指向的节点。要退位的 current fiber tree作为备用,充当了构建workinProgress fiber tree的原料,最大程度节约了性能,这样周而复始,。收集到的 effect list只会关注有改动的节点,并且从最深处往前排列,这也就对应上了,刷新顺序是子节点到父节点。
双fiber树就是问题关键
有两个阶段:
首次渲染:直接先把 current fiber tree构建出来更新渲染:延续 current fiber tree构建workinProgress fiber tree
蜕变之中必有延续
更新阶段,两棵fiber树如双生一般,current fiber与workinProgress fiber之间用alternate这个指针进行了关联,也就是说,可以在处理workinProgress fiber工作的时候,能够获得current fiber的信息,除非是全新的,那就重新创建。
每构建一个workinProgress fiber,如果这个fiber对应的节点是一个函数组件,并且可以通过alternate获得current fiber,那么就进行延续,承载延续的精华的便是current fiber的memoizedState这个属性
延续的精华尽在memoizedState
首次渲染时
依次执行我们在函数组件的hooks,每执行一个种类hooks,都会创建一个对应该种类的hook对象,用来保存信息。
useState 对应 state信息 useEffect 对应 effect对象 useMemo 对应 缓存的值和deps useRef 对应 ref对象 ...
这些信息都会以链表的形式保存在current fiber的memoizedState中
更新渲染时
每次构建对应的是函数组件的workinProgress fiber时,都会从对应的current fiber中延续这个以链表结构存储的hooks信息。
如该函数组件:
export default function Test() {
const [info1, setInfo1] = useState(0);
useEffect(() => {}, [info1]);
const ref = useRef();
const [info2, setInfo2] = useState(0);
const [info3, setInfo3] = useState(0);
return (
<div>
<div ref={ref}> {`${info1}${info2}${info3}`}div>
div>
);
}
复制代码
那么hooks的延续就如下图这样:
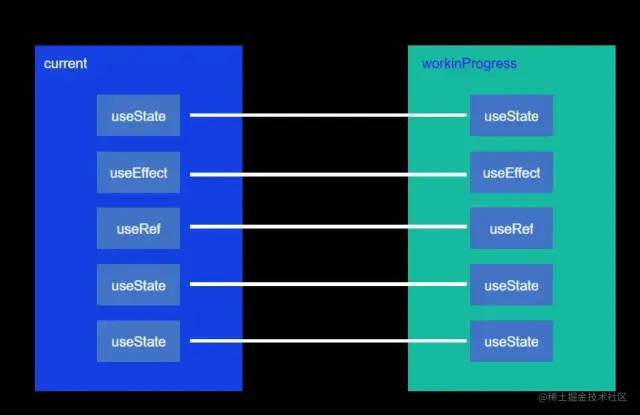
通过链表的顺序去延续,如果其中的一个hooks写在条件语句中,代码如下:
export default function Test() {
const [info1, setInfo1] = useState(0);
let ref;
useEffect(() => {
setInfo1(info1+1)
}, [info1]);
if(info1==0){
ref = useRef();
}
const [info2, setInfo2] = useState(0);
const [info3, setInfo3] = useState(0);
return (
<div>
<div ref={ref}> {`${info1}${info2}${info3}`}div>
div>
);
}
复制代码
那么就会破坏延续的顺序,获得信息就会驴唇不对马嘴,就像这样:
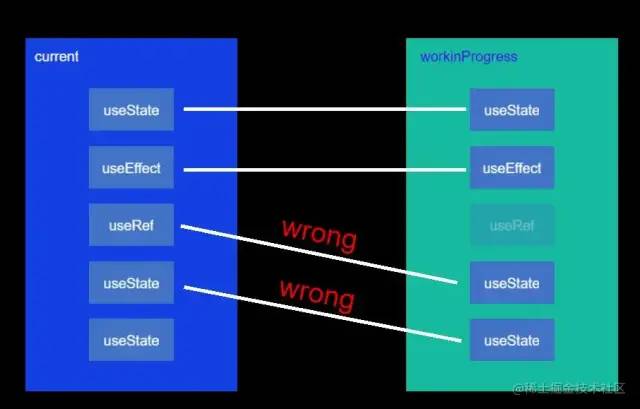
所以这就是不能把hooks写在条件语句中的原因
而这就是Hooks能够延续的奥秘,作为支撑其实现各种功能,从而与class组件相媲美的前提基础。
hooks整的那些活儿
了解一下capture value以及闭包陷阱
capture value顾名思义,“捕获的的值”,函数组件执行一次就会产生一个闭包,就好像一个快照, 这跟我们上面分析说的“关联render结果”或者“那一刻快照”呼应上了。
当capture value遇上hooks出现了因使用“过期快照”而产生的问题,那就称为闭包陷阱。
不过叫什么不重要,归根节点都是“过期闭包”的问题,而在useEffect中的暴露的问题最为明显。
先举个🌰:
let B = (props) => {
const { info } = props;
const [count,setCount] = useState(0);
useEffect(()=>{
setInterval(()=>{
//这才是dispatch函数正确的使用方式
setCount((old)=>{
return old+1;
})
},1000)
},[])
useEffect(()=>{
setInterval(()=>{
console.log("info为:"+info+" count为:"+count)
},1000)
},[])
return <div>div>
}
let A = (props) => {
const [info,setInfo] = useState(0);
useEffect(()=>{
setInterval(()=>{
//这才是dispatch函数正确的使用方式
setInfo((old)=>{
return old+1;
})
},1000)
},[])
return <div>
<B info={info}>B>
{info}
div>
}
export default function App() {
return (
<div>
<A>
A>
div>
);
}
复制代码
这种log出来的一直都是info:0 count:0,很显然使用的关联的“过期快照”中的数据。
解决办法:
通过useRef获得ref对象
ref的结构是这样的:
{
current:null
}
复制代码
我们把需要托管的数据赋值给current,值得一提的你只能赋值给current,ref对象是不支持扩展的。
然后我们重写一下代码:
let B = (props) => {
const { info } = props;
const [count,setCount] = useState(0);
const refInfoFromProps = useRef();
const refCountFromProps = useRef();
refInfoFromProps.current = info;
refCountFromProps.current = count;
useEffect(()=>{
setInterval(()=>{
//这才是dispatch函数正确的使用方式
setCount((old)=>{
return old+1;
})
},1000)
},[])
useEffect(()=>{
setInterval(()=>{
console.log("info为:"+refInfoFromProps.current+" count为:"+refCountFromProps.current)
},1000)
},[])
return <div>div>
}
复制代码
这样就能每次都访问最新的数据了。
当然还有很多别的办法,比如使用useReducer,有兴趣可以研究一下。
useState的事儿
这样设置刷新么?
先看下这段代码
let A = ((props) => {
const [count,setCount] = useState({a:1})
return <div onClick={()=>{
count.a = Date.now();
setCount(count)
}}>
测试是否刷新
div>
})
复制代码
当我点击之后触发了setCount,请问刷新么?
答案是不刷新,因为我们在使用React的时候,心里应该常提醒自己,就是:
不可变值,不可变值,不可变值
上面的代码问题主要两点:
直接的修改了state,这样破坏了不可变值的规矩,你应该通过 Object.assign或者扩展运算符来重新创建一个对象进行设置。React内部会针对传入的参数进行浅比较,引用类型的数据比较的是其指向的地址,而不是内容,切记,所以光内容变了没用。
正确的写法
let A = ((props) => {
const [count,setCount] = useState({a:1})
return <div onClick={()=>{
setCount({...count,a:Date.now()})
}}>
测试是否刷新
div>
})
复制代码
useState和setState不太一样
useState的set函数跟类组件的setState命名很像,会让有种错觉它俩一样,其实不然,前者实际上是一个dispath,因为useState内部是基于useReducer实现的。而且也不用非得命名set***,你可以随便起名。
其中有三点不同,值得指出:
setState:
第二个参数是一个函数,可以在状态值设置生效后进行回调,我们就可以在这里面拿到最新的状态值。 setState具备浅合并功能,比如state是 {a:1,b:2,c:{e:0}},setState({c:{f:0},d:4}),state就会合并成{a:1,b:2,c:{f:0},d:4}setState设置状态就会引发刷新,即使设置的是相同的值也一样,除非用PureComponent实现才能解决
set函数
没有第二个参数,但是可以借助 useEffect组合实现,也还好没有合并功能,设置啥就是啥。。。,不过自己动手优化一下也是可以的。 设置相同的状态是不会触发刷新的,这一点无需进行配置。
接下来深入讨论一个有趣的问题。
useState的set函数是同步的还是异步的?setState是同步还是异步的?
答案惊人的一致,即:
大部分时候异步,有些时候同步
具体什么时候同步呢?就是
如果是由React引发的事件处理(比如通过onClick引发的事件处理),调用setState不会同步更新this.state,除此之外的setState调用会同步执行this.state[4]
不信,那看下代码:
export default function Test() {
const [info1, setInfo1] = useState(0);
const [info2, setInfo2] = useState(0);
const ref1 = useRef();
const ref2 = useRef();
ref1.current = info1;
ref2.current = info2;
useEffect(() => {
setInfo1(ref1.current + 1);
setInfo1(ref1.current + 1);
setInfo1(ref1.current + 1);
console.log("info1:"+ref2.current); // info1:0
setTimeout(() => {
setInfo2(ref2.current + 1);
setInfo2(ref2.current + 1);
setInfo2(ref2.current + 1);
console.log("info2:"+ref2.current);// 同步输出 info2:3
});
}, []);
return <div>{info1}div>;
}
复制代码
输出的日志是: info1:0 info2:3
那么useState的set函数这一点上就跟setState一样了,所以再说useState的set函数是异步还是同步的时候,知道怎么说了吧。
useEffect的事儿
useEffect有两个参数,一个effect执行的回调函数,一个是是依赖数组
同时useEffect可以写多个,这样就可以按照业务独立拆分,做到关注点分离
生命周期
useEffect是函数组件实现生命周期函数的重要手段
可以模拟的生命周期分别是:
componentDidMount componentWillUnmount componentDidUpdate
代码如下:
useEffect(() => {
// 相当于 componentDidMount
return () => {
// 相当于 componentWillUnmount
}
}, [])
useEffect(() => {
// 相当于 componentDidUpdate
})
复制代码
useEffect的清除函数的执行时机
首先清除函数执行有两种情况:
一个是卸载的时候,这个众所周知。 一个是effect重新执行的时候,也会执行,这点大家要注意,容易马虎
然后再看下这段代码
useEffect(
() => {
...
return () => {
...
console.log("test")
}
},
[flag]],
)
复制代码
请问:当flag从true设置成了false,这个return的清除函数会执行么?
答案是:执行
再难一点
useEffect(
() => {
if (flag) {
...
return () => {
...
console.log("test")
}
}
},
[flag]],
)
复制代码
请问执行么?
答案是:执行
你可以记住一个铁律:
当effect重新执行的时候,会清除上一次effect
useEffect和useLayoutEffect区分
useEffect是异步的,useLayoutEffect是同步的 所谓的异步就是利用requestIdleCallback,在浏览器空闲时间执行传入的callback,也就是继续处理js逻辑 大部分情况没什么区别,但是当有耗时的逻辑,useLayoutEffect就会造成渲染阻塞
先贴出一段代码,这是我在网上遇到了很有趣的例子。[5]
function TestEffectApi() {
const [lapse, setLapse] = useState(0)
const [running, setRunning] = useState(false)
useEffect(
() => {
if (running) {
const startTime = Date.now() - lapse
const intervalId = setInterval(() => {
setLapse(Date.now() - startTime)
}, 2)
console.log(intervalId)
return () => {
clearInterval(intervalId)
}
}
},
[running],
)
function handleRunClick() {
setRunning(r => !r)
}
function handleClearClick() {
setRunning(false)
setLapse(0)
}
return (
<div>
<label>{lapse}mslabel>
<button onClick={handleRunClick}>
{running ? '暂停' : '开始'}
button>
<button onClick={handleClearClick}>
暂停并清0
button>
div>
)
}
复制代码
通过代码可以看出,当我点击“暂停并清0”按钮的时候,我们设置了两个状态一个running和lapse,前者控制定时器运行,后者控制数据显示,而点击之后的预期是:定时器关闭,同时显示的数据为“0”,但是实际情况却是偶发出现显示不为“0”的情况
原因:
因为useEffect是异步的,当通过设置running关闭定时器和设置lapse为“0”时,并没有第一时间关闭定时器,而是阴差阳错的出现了一种情况:lapse已经设置为零,定时器还没关闭就要关闭的这一霎,又一次的执行了,便出现了这种问题。而用同步执行的LayoutEffect就没有这个问题
通过上面这个例子,useEffect和LayoutEffect的区别应该能可见一斑了。
useRef真有用啊
useRef是真有用啊,凭借“跨渲染周期”保存数据的能力,即拥有在整个组件生命周期只维护一个引用的特性,可以解决很多问题。
不但可以保存dom节点还可以保存其他数据,比如上面提到的过期闭包的问题中保存外部的prop和state。
除此之外还有一个有趣的用处,就是可以结合forwardRef和useImperativeHandle这两个api,让函数组件可以像类组件那样暴露函数给其他节点使用
代码如下:
let A = forwardRef((props, ref) => {
useImperativeHandle(ref, () => {
return {
test: () => {
console.log("123")
}
}
})
const [info, setInfo] = useState(0);
return <div>
{info}
div>
})
export default function App() {
const ref = useRef(null);
return (
<div onClick={() => {
ref.current.test()
}}>
<A ref={ref}>
A>
div>
);
}
复制代码
在父组件中创建一个ref,然后给到子组件的A 但是子组件是函数组件,不能直接给,那就用forwardRef这个HOC包装一下,就能收到了,并作为继props之后第二个参数传入 拿到ref作为useImperativeHandle的第一个参数,第二个参数是一个函数,用于返回装有暴露数据的对象。
对于forwardRef这个Hoc,我认为完全可以不用,我改造一下代码
let A = ((props) => {
const {testRef} = props;
useImperativeHandle(testRef, () => {
return {
test: () => {
console.log("ok")
}
}
})
const [info, setInfo] = useState(0);
return <div>
{info}
div>
})
export default function App() {
const ref = useRef(null);
return (
<div onClick={() => {
ref.current.test()
}}>
<A testRef={ref}>
A>
div>
);
}
复制代码
这么写也是可以的,看着还简洁了不少,仅供参考。
useContext可以一定程度的替代第三方的数据管理库
先贴出完整可运行代码
import {
createContext,
useContext,
useReducer,
} from "react";
export const TestContext = createContext({})
const TAG_1 = 'TAG_1'
const reducer = (state, action) => {
const { payload, type } = action;
switch (type) {
case TAG_1:
return { ...state, ...payload };
dedault: return state;
}
};
export const A = (props) => {
const [data, dispatch] = useReducer(reducer, { info: "本文作者" });
return (
<TestContext.Provider value={{ data, dispatch }}>
<B>B>
TestContext.Provider>
);
};
let B = () => {
const { dispatch, data } = useContext(TestContext);
let handleClick = ()=>{
dispatch({
type: TAG_1,
payload: {
info: "闲D阿强",
},
})
}
return (
<div>
<input
type="button"
value="测试context"
onClick={handleClick}
/>
{data.info}
div>
);
};
复制代码
使用api有:
createContext useReducer useContext
实现的步骤:
函数组件A
使用 createContextapi创建一个TestContext,进而使用Provider然后使用 useReducerapi创建一个reducer,将reducer返回的data,dispatch,通过Provider进行共享函数组件B
在其内部使用 useContextapi并传入创建好的TestContext,从而获得data,dispatch使用 data中info值作为显示,通过点击事件调用dispatch进行修改,看反馈是否正确
em~,目前来看可以在一定程度上替代数据管理库,对,是一定程度。
自定义hook不同于以往封装的工具函数
自定义hook,大概是这个样子的
const useMousePosition = () => {
const [position, setPosition] = useState({x: 0, y: 0 })
useEffect(() => {
const updateMouse = (e) => {
setPosition({ x: e.clientX, y: e.clientY })
}
document.addEventListener('mousemove', updateMouse)
return () => {
document.removeEventListener('mousemove', updateMouse)
}
})
return position
}
复制代码
我曾纠结过一个问题,写一个自定义hook和单纯封装一个函数有区别么?
现在看来,答案是肯定,至于如何去区分,我觉得是这样的:
自定义hook与其他工具函数的区别就在于可以使用官方提供的hooks和其他自定义hook,拥有自己的状态,就好比说一个自定义hook就像一个不用返回jsx的组件函数。当然你也可以不用这个优势,那么就跟普通函数没啥区别了。。。但就这一手,拆分共用逻辑,避免代码重复的发挥空间就大了不知多少。
函数组件的性能优化的方式
memo
memo是一个高阶组件,使用方法很简单:
let A = memo((props) => {
return <div >
memo测试
div>
})
复制代码
很多文章说memo相当于PureComponent,我觉得不对,我更愿意这么理解:
函数组件本身就有继承PureComponent创建的类组件有类似的能力 memo对标的应该是类组件的shouldComponentUpdate
比如用PureComponent创建一个类组件:
class C extends PureComponent{
state={
a:1
}
render(){
return <div onClick={
()=>{
this.setState({
a:1
})
}
}>测试组件是否刷新div>
}
}
复制代码
点击设置状态变量a相同的值1,页面是不刷新的,你用Component创建的组件是刷新的 但这点,函数组件本身就有了,不用刻意为之。
而memo最主要的就是避免函数组件不必要的刷新,这点跟shouldComponentUpdate如出一辙。
shouldComponentUpdate是一个生命周期,代码如下:
...
shouldComponentUpdate (nextProps, nextState) {
if (nextProps.name === this.props.name) return false
return true
}
...
复制代码
memo 的实现,传入第二个参数propsAreEqual,代码是这样的:
let propsAreEqual = (prevProps, nextProps)=>{
// 根据具体业务判断传入的参数是否相当决定刷新
// true 表示相等,不刷新,函数组件就不会执行
// false 表示不等,刷新,就会执行
return false
}
let A = memo((props) => {
return <div >
memo测试
div>
},propsAreEqual)
复制代码
一个叫“shouldComponentUpdate”,"我能刷新么"
一个叫做“propsAreEqual”,"参数相等么"
"相等为true"当然"不能刷新false",em~ 它俩是相反的。
useMemo
避免重复计算,类似计算属性
useMemo(()=>{return "计算的值"},[依赖的值])
复制代码
注意闭包陷阱,逻辑中用到什么,最后就依赖什么
useCallback
首先函数是引用类型,本质也是一个对象,函数组件内部会创建一些函数来组织业务,并且还会作为参数传入子节点。
那么每次函数刷新,即使函数本身没有变化,也会重新创建新的函数对象,有可能会引起不必要的刷新,频繁创建也会浪费性能。
那就用useCallback记忆一下,依赖不变,函数的引用就不变,可以理解为是一个配置依赖以响应更新的useRef
写法如下:
useCallback(() => {}, [依赖的值]);
复制代码
注意闭包陷阱,逻辑中用到什么,最后就依赖什么
总结
那么我们梳理一下思路,我们从hooks助力函数组件聊起,对hooks能够延续的魔法而感到着迷,进而探索内部的运行原理,了解到了延续的奥秘尽在fiber之中,最后再说了说使用hooks开发的的二三事,试着建立从原理到使用的一条细细的通路,目的就是先把思路调通,这样之后学习和补充更有主见,正所谓先迷后得主。
题外话
每当我着迷hooks的精妙,去查阅相关资料的时候,起初真的看的一头雾水,并没第一时间觉得文章有多好,随着我反复的阅读并动手调试React源码去印证一些疑惑,终于如我一般普通的coder也能勉强感受到文章的功力,但这引发了我的一个思考,是不是文章发力太深,就算力量再强,打不到读者也是弱,当好与大家越来越远,渐渐地没有了欣赏,那么也就没有了好,中庸的我希望能够粘合住二者,找一个合适位置发出我的力,如果这个力能打到尽可能多的的人,那么再弱的力也是强,这样就有可能帮助更多的人去欣赏真正好的文章,大家都想当“玉”,那么我就去当个“砖头”吧。
React源码调试项目,可调试v16.x和v17.x[6]
关于本文
来源:闲D阿强
https://juejin.cn/post/7033750813986324510
Node 社群
我组建了一个氛围特别好的 Node.js 社群,里面有很多 Node.js小伙伴,如果你对Node.js学习感兴趣的话(后续有计划也可以),我们可以一起进行Node.js相关的交流、学习、共建。下方加 考拉 好友回复「Node」即可。
如果你觉得这篇内容对你有帮助,我想请你帮我2个小忙:
1. 点个「在看」,让更多人也能看到这篇文章 2. 订阅官方博客 www.inode.club 让我们一起成长 点赞和在看就是最大的支持❤️