
谈谈技术人员如何做好团队管理
点击上方“码农突围”,马上关注
这里是码农充电第一站,回复“666”,获取一份专属大礼包
真爱,请设置“星标”或点个“在看”

很多技术人员在职业上对自己要求高,工作勤奋,承担越来越大的责任,最终得到信任,被提拔到管理岗位。但是往往缺乏专业的管理知识,在工作中不能从整体范围优化工作流程,仍然是“个人贡献者”的工作方式,遇到问题自己上,经常耽误了本职工作。
于是翻了很多书,看了很多文章,学习了很多“为人处世的艺术”和“企业发展的战略”,最终把自己干成了研发部主管,技术却逐渐荒废。管理工作是什么呢,技术和管理是截然不同的两条发展方向吗?
不是的。技术和管理都要做到量化分析,全局优化,存在很多相似的方法。这里用一个系统性能优化的场景举个例子,大家可以体会一下:
公司里有一个程序,运行在10台服务器的集群上。现在业务量增加了,请求处理不完。老板把你找来,要你优化这个程序。接到这个头疼的任务,你把开发测试运维各个部门的人都找来开会想办法,有人说数据库该升级了,有人说代码写的太烂要优化,有人说机器太少再加5台,还有人说我们要改架构上云,上了云以后就再也没有这种问题了。你该听谁的呢?
先别着急动手。有一句话叫做“没有度量就没有优化”,首先要“度量”这个现象。先把设计人员找来,了解一下这个程序是什么功能,工作流程是什么样的。
程序架构:这个程序处理图片识别的业务,从网络端口接收图片,识别图片里面的信息,然后在图片库里进行对比,最后输出相似图片。处理过程是这样的:
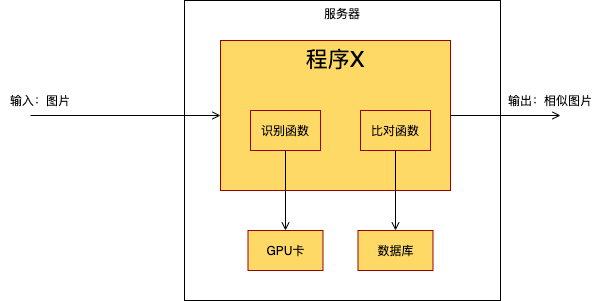
搞清楚程序架构,接下来我们需要度量数据。有一些数据很容易得到,还有一些数据似乎没人搞得清。于是你给研发团队布置了一个任务,让他们在程序里面埋点,尽快收集一些数据指标。开发人员改了一版程序,部署上去。在生产线上跑了一天,得到一些数据指标:
输入:每天需要处理100万张图片,这是从上游工序收集到的
识别函数:识别1张图片平均时间是0.5秒
比对函数:比对1个图片的平均时间是0.4秒
现在我们计算一下:处理1张图片的时间是0.9秒(0.5 + 0.4),1台机器1天可以处理图片96000(86400 / 0.9),10台机器1天可以处理图片96万(96000 * 10),达不到100万。要完成每天100万的处理量,需要服务器10.4台(100万 / 96000),约等于11台。
是不是告诉老板必须要买服务器了呢:“需要买1台服务器,带GPU的!”。先别着急。
我们分析一下程序运行过程:识别函数和比对函数是串行执行的。识别函数忙碌的时候,比对函数是空闲的,它在等待识别的结果。同样的,比对函数忙碌的时候,识别函数也是无事可做的。也就是说,服务器的资源并没有得到充分利用,GPU卡和数据库的资源都有很大的浪费。
怎样提高资源利用率呢?可以改变一下程序的架构,调整成下面这样:
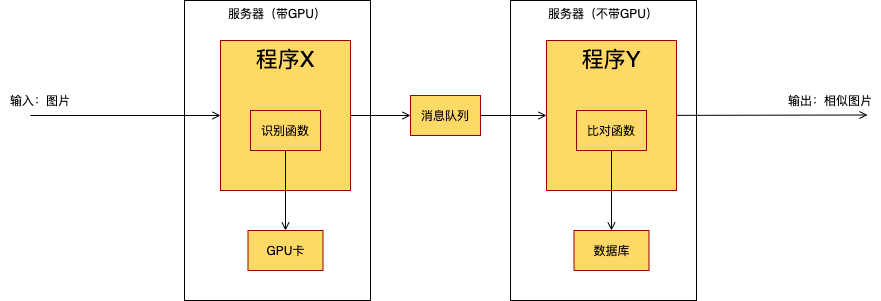
把原来的程序一分为二,分别部署在两台服务器上,中间用一个消息队列交换数据。现在两个程序都可以充分利用服务器的资源。我们再来计算一下吞吐量:
程序X:处理一个图片需要0.5秒,1台服务器1天处理图片172800(86400 / 0.5),100万图片需要服务器5.8 台(100万 / 172800),约等于6台。
程序Y:处理一个图片需要0.4秒,1台服务器1天处理图片216000(86400 / 0.4),100万图片需要服务器4.6台(100万 / 216000),约等于5台。
仍然需要服务器11台,好像没有什么改进嘛。我们再分析一下:原方案需要11台带GPU的服务器,现在只需要6台,我们省下了5块GPU卡,这已经是一笔不少的费用。
架构师又提供了一个信息:在原方案里面,识别函数和比对函数串行执行,所以只能用同样的并发线程数执行。新方案已经分离到两个程序中,所以比对函数就可以设置更高的并发线程数,可以提高到原来的4倍。
这是一个好消息,程序Y的吞吐量可以提高4倍,这样一来,只需要1.16台服务器就可以处理完100万数据,约等于2台。
按照改进后的架构,只需要6台带GPU的服务器,再加2台不带GPU的服务器,总计需要8台服务器。不仅可以完成处理任务,还可以预留一些GPU卡,以备以后业务发展。
例子说完了,以上就是优化一个IT系统运行效率的过程。其实,企业管理也是相似的过程,只是优化的对象不再是机器和程序,而是人的活动。
在一家软件企业,有需求收集、产品研发、项目实施等多个流程,有时这些流程会有卡顿、缓慢的现象,看上去和一个IT系统的问题是一样的。有一个著名的问题是:“在你的团队里,只涉及一行代码的变更需要多久才能上线?” 从需求到交付,这个路程有多远。
我们可能经常会遇到这样的问题:某个现场运维反馈了一个缺陷,看上去只是很小的问题,修复也不麻烦,却花了很长时间才解决。事后回顾这个问题,每个部门的人都有话要说:
运维:我一发现这个问题,就在Jira平台上提出来了,当时开发也没有回复,我就下班了。
开发:我当时正在开发新版本的功能,写一段很复杂的代码。看到这个问题的时候,已经是下班时间了。运维只描述了问题现象,没有说明现场部署的版本。我不知道在哪个版本上修复这个问题,只好在最新的发布版上先把它改掉了,然后把包发给测试。我在Jira上也回了消息,要求运维把现场版本号发出来。
测试:我收到开发的包,打算做一下测试。整个集成环境已经升级了,我需要把测试环境恢复到老的版本。这事我搞了一上午,下午的时候搞了一遍测试,发现几个缺陷,把问题提给开发了。
开发:我收到测试提的Bug,修改以后又发了一个版,这次应该没问题了。
运维:环境上的包没有版本标识,我花了很长时间核对所有版本的Md5码,才找到了版本号,在Jira上回了。这个问题很紧急,我想尽快解决,于是就拿测试给我的最新版,想尝试安装一下。我不知道这个包能不能兼容现场的环境,只能试试看。我在预发布环境上搞了一天,也没把他装上去,看起来是不行的。
开发:我看到现场版本号,这是一个非常老的版本,已经一年多了。我进入这个项目才三个月,在微信上AT了好几个人。代码基线也不知道在哪里,找了很久才找到,修复之后已经很晚了,还是要交给测试测一下。
测试:集成环境还是要恢复一下,我搞了三个小时。测试确认没有问题,就交给运维了。
运维:我收到安装包,在预发布环境上试了一下,没什么问题。生产环境要麻烦一些,我一开始只更新了一个节点,发现问题仍然间歇性的出现。后来才知道要还有2个节点也要部署。这次搞了一天,下次再有这样的情况,我就知道怎么做了。
从每个人的角度看,自己都很忙碌,花了很多时间解决问题。但是从缺陷解决的角度看,事情在不断的卡顿、等待。在这些劳动过程中,真正有效的、能产生价值的劳动占多少呢?这就是DevOps需要解决的价值流动问题,需要建立一套体系,衡量这个流程,不断优化它。
从上面一个缺陷解决的过程来看,技术部门存在很多问题,有一些问题是单点的,比如:
代码管理:代码基线不明确,版本无法回溯
发布管理:发布文档没有妥善保管
版本管理:版本号没有明确的烙印,编号不清楚。无法判断新老版本的兼容关系
基础设施管理:研发人员没有办法迅速得到基础设施,为了建立一个测试环境需要花很长时间
部署管理:测试人员手工部署,需要花很久才能完成一次部署
环境管理:现场的服务器上部署了哪些进程,没有一套管理办法,需要登录上去查看
看到这些问题,是不是就可以开始改进了呢?还是不要着急。像优化一个IT系统一样,我们要搞清楚工作流程,然后度量这个流程,再整体优化。在整体情况不清楚的情况下,局部优化是没有用的,优化一个局部的效率,可能适得其反,造成更大的浪费。
把整体流程搞清楚,当然是存在很多困难的。一个大问题就是:企业工作流程不像IT系统流程一样清楚。IT系统一般有各种文档,至少有源代码可以查看。企业工作流程经常存在一些模糊的地方,部门和岗位职责的定义不是十分清楚。人也不会像程序一样“听话”,为了完成自己的工作任务,人是有创造性的。
所以每个企业都要整理岗位和工作流程,努力把这些模糊的流程整理清楚,按照自己的业务特点制定一套流程规范,这是十分必要的工作。技术岗位上的人更熟悉实际的工作流程,他们走上管理岗位,在这方面是有优势的。
作者:小陆
来源:www.cnblogs.com/lane_cn/p/13685179.html
版权申明:内容来源网络,仅供分享学习,版权归原创者所有。除非无法确认,我们都会标明作者及出处,如有侵权烦请告知,我们会立即删除并表示歉意。谢谢!
(完)
码农突围资料链接
1、卧槽!字节跳动《算法中文手册》火了,完整版 PDF 开放下载!
2、计算机基础知识总结与操作系统 PDF 下载
3、艾玛,终于来了!《LeetCode Java版题解》.PDF
4、Github 10K+,《LeetCode刷题C/C++版答案》出炉.PDF欢迎添加鱼哥个人微信:smartfish2020,进粉丝群或围观朋友圈