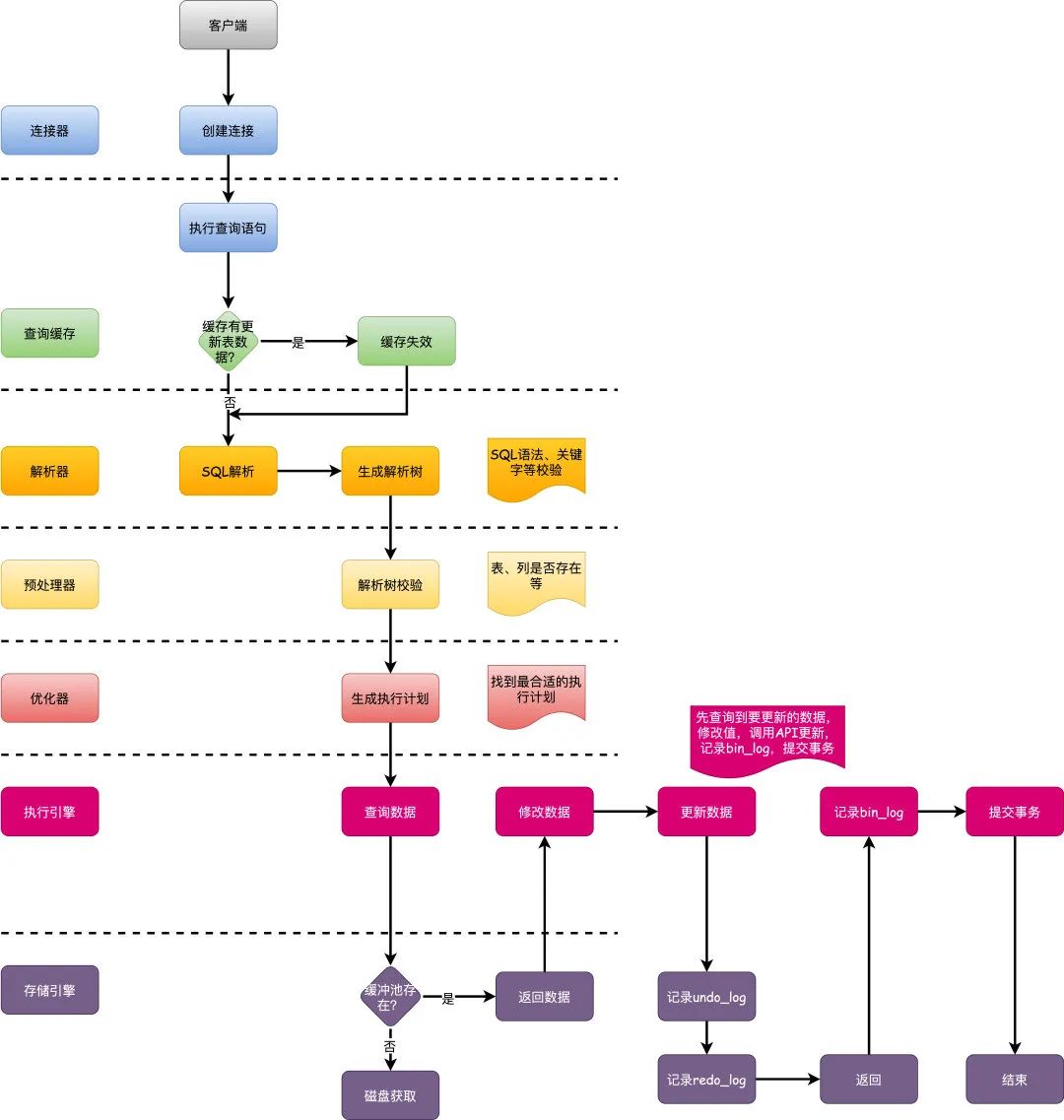
面试官:你说说一条更新SQL的执行过程?

对于一个SQL语句的更新来说,前面的流程都可以说类似的,通过解析器进行语法分析,优化器优化,执行引擎去执行,这个都没有什么问题,重点在于多了一点东西,那就是redo_log、undo_log和binlog。
执行流程大致如下:
首先客户端发送请求到服务端,建立连接。 服务端先看下查询缓存,对于更新某张表的SQL,该表的所有查询缓存都失效。 接着来到解析器,进行语法分析,一些系统关键字校验,校验语法是否合规。 然后优化器进行SQL优化,比如怎么选择索引之类,然后生成执行计划。 执行引擎去存储引擎查询需要更新的数据。 存储引擎判断当前缓冲池中是否存在需要更新的数据,存在就直接返回,否则去从磁盘加载数据。 执行引擎调用存储引擎API去更新数据。 存储引擎更新数据,同时写入undo_log、redo_log信息。 执行引擎写binlog,提交事务,流程结束。
可以看到相比于查询流程,实际上更新多了关于undo_log和redo_log的流程,接下来再具体探讨一下这几个流程的执行过程是什么样子。
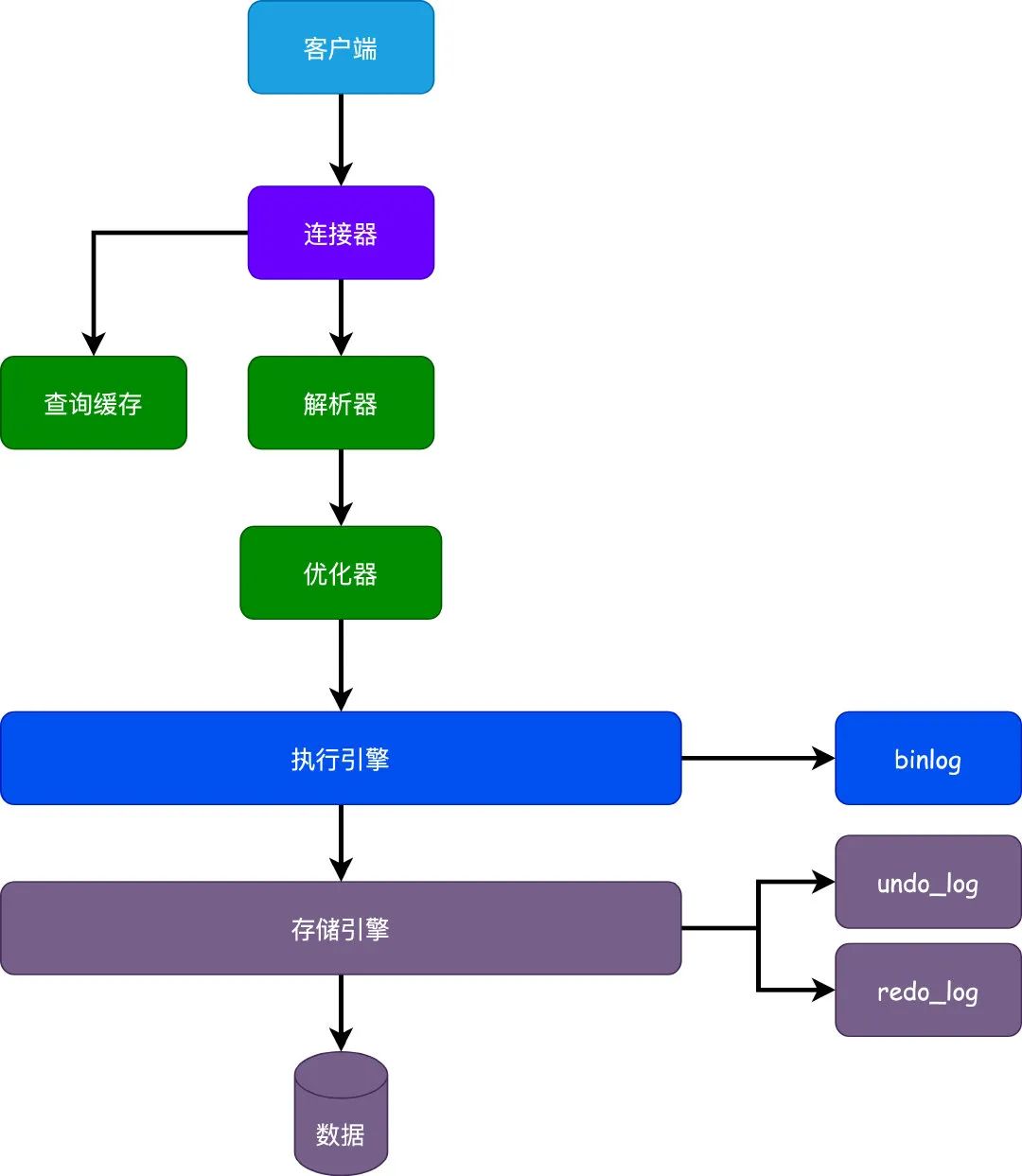
redo_log
redo_log按照字面翻译称为重做日志,是InnoDB存储引擎特有的,用于保证事务的原子性和持久性。怎么理解呢?简单来说就是保存我们执行的更新语句的记录,如果服务器或者Mysql宕机,通过redo_log可以恢复更新的数据。
按照上述流程来举例的话,比如update user set age=20 where id=1这样的简单更新SQL,我们不管执行引擎怎么拿到的数据,不管是从缓冲池拿的还是磁盘拿到的,这条现在数据都在缓冲池里面,然后去缓冲池的数据把age改成10。
缓冲池内存中的数据已经更新好了,那么接下来就该开始写redo_log了,只是redo_log也不是直接写文件的,一般都是这样对吧,直接写的话性能太差了,所以就有redo_log_buffer叫做redo_log缓冲。

在写redo_log的时候先把数据写到redo_log缓冲区,然后异步写入磁盘,很显然,极端情况下会有丢失数据的可能。
控制这个刷盘策略的的参数叫做innodb_flush_log_at_trx_commit。
这个参数有3个值:0|1|2,默认的话是1。
0代表提交事务时不会写入磁盘,这样的话性能当然最好,但是在Mysql宕机的情况会丢失上一秒的事务的数据。
1代表提交事务一定会进行一次刷盘,同步当然性能最差,但是也最安全。
2代表写入文件系统的缓存,不进行刷盘。这个选项性能略差于1,Mysql宕机的话对数据没有任何影响,只有在操作系统宕机才会丢失数据,这种情况下默认Mysql每秒会执行一次刷盘。
使用0或者2虽然提高了性能,但是变相的也丧失了事务的持久性。
undo_log
重做日志保证了事务的持久性,保证能够在宕机后恢复事务的数据,那么另外一种情况就是事务在需要回滚的时候怎么办?这时候就是undo_log的作用了,它保证了事务的一致性。
对于undo_log来说,简单理解就是做了逆向操作。
比如insert一条数据,就对应生成delete,update语句则生成相反的更新语句,这样做到将数据修改回之前的状态。
binlog
binlog称为二进制日志,大家都很熟悉,记录了改变数据库的那些SQL语句,对于这里来说,更新语句当然是了。
通过不同于redo_log是独属于存储引擎独有的东西,binlog则是Mysql本身产生的日志。
不同于redo_log是物理日志,binlog和undo_log都属于逻辑日志。
这有什么区别呢?
简单来说,逻辑日志可以认为就是存储的SQL本身,而物理日志看看redo_log存储的是啥就知道了,关于page_id页ID,offset偏移量啊这些东西,记录的是对页的修改。
另外物理日志可以保证幂等性,而逻辑日志则不一定能,除非本身SQL就是幂等的。
上面我们提到了redo_log的刷盘策略,binlog就和它非常类似了,控制参数是sync_binlog。
默认值为0,相当于是innodb_flush_log_at_trx_commit的值为2,由文件系统控制,同样如果服务器宕机,binlog丢失,当然我们也可以改成1,就和redo_log的效果是一样,每1次事务提交都同步写入磁盘。
事务
为了保证写redo_log和binlog的一致性,实际采用了二阶段提交的方式。
prepare阶段:根据innodb_flush_log_at_trx_commit设置的刷盘策略决定是否写入磁盘,标记为prepare状态。
commit阶段:写入binlog日志,事务标记为提交状态。
总结