
一条查询SQL是如何执行的
作者:捡田螺的小男孩
前言
日常开发中,我们经常需要写查询SQL。但是,大家知道一条查询SQL在mysql内部是如何执行的嘛?比如这条简单的SQL:
select * from test_db.user_info_tab where user_id =123;
我们知道在mySQL客户端,输入一条查询SQL,然后看到返回查询的结果。这条查询语句在 MySQL 内部到底是如何执行的呢?本文跟大家探讨一下哈,我们先来看下MySQL基本架构~
MySQL 基本架构
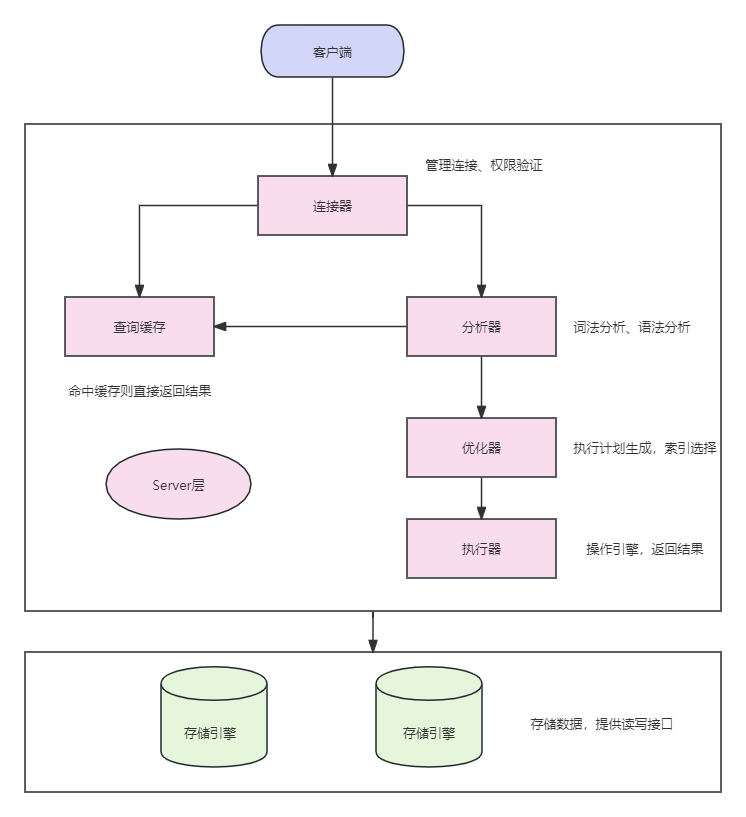
总体来说,MySQL大体分为两部分,分别是Server 层和存储引擎层。
Server 层
它包括连接器、查询缓存、分析器、优化器、执行器等。比如存储过程,触发器,视图都是在这一层实现的。
- 连接器(Connection Manager):负责处理客户端与服务器之间的连接。它接受来自客户端的请求,并进行身份验证和权限检查,建立和管理连接。
- 查询缓存(Query Cache):在旧版 MySQL 中有,但在较新的版本中已不推荐使用。它能够缓存查询和对应的结果,以提高查询性能。然而,在高并发和大型数据库中,它反而可能成为性能瓶颈,因为它在某些情况下会引起锁和不必要的开销。
- 分析器(Parser):负责分析 SQL 查询语句,验证其语法和语义,确保查询的正确性。它将 SQL 语句转换成内部数据结构供优化器和执行器使用。
- 优化器(Optimizer):接收来自分析器的查询请求,并决定如何最有效地执行查询。优化器的目标是找到最佳的执行路径,选择合适的索引、连接顺序和访问方法,以提高查询性能。
- 执行器(Executor):负责执行优化器生成的执行计划,获取存储引擎返回的数据,并处理客户端请求。它与存储引擎交互,执行查询并返回结果给用户。
存储引擎层: 它负责数据的存储和提取。Mysql支持InnoDB、MyISAM、Memory 等多个存储引擎。我们日常开发中,一般用的存储引擎就是InnoDB。从 MySQL 5.5 版本开始,InnoDB 就成为了默认的存储引擎。
介绍完MySQL基本架构,带大家看一下,每个组件,一条查询SQL主要做什么事~~
连接器
我们要执行查询SQL,一般在MySQL客户端, 需要输入连接命令,连接到MySQL服务端。在MySQL服务端,就是连接器负责跟你的客户端建立连接、获取权限、维持和管理连接。
连接命令如下:
mysql -h(ip地址) -P(端口) -u(用户名) -p
输入完连接命令之后,我们接着输入正确的密码,经过经典的TCP握手之后,就可以成功连接到MySQL服务器啦,如下:
C:\MySQL\MySQL Server 8.0\bin>mysql -h 127.0.0.1 -P 3306 -u root -p
Enter password: ******
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 50
Server version: 8.0.31 MySQL Community Server - GPL
Copyright (c) 2000, 2022, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
如果输入密码错误,则会收到一个 Access denied的错误信息,如下:
C:\Program Files\MySQL\MySQL Server 8.0\bin>mysql -h 127.0.0.1 -P 3306 -u root -p
Enter password: *****
ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: YES)
连接成功之后,大家就可以直接输入查询SQL,就可以看到结果啦。
mysql> select * from test_db.user_info_tab where user_id =123;
+---------+----------------+------+------+--------+---------+--------------------------+
| id | user_name | age | city | status | user_id | password |
+---------+----------------+------+------+--------+---------+--------------------------+
| 1570091 | 捡田螺的小男孩 | 28 | 深圳 | 活跃 | 123 | 523da7ne+yndc5nb1zWWlA== |
+---------+----------------+------+------+--------+---------+--------------------------+
1 row in set (0.01 sec)
大家注意一下哈,如果连接成功后,没有后续的输入查询SQL等其他操作。这时候,这个连接是空闲的哈,可以用show processlist查看。
查询缓存
在老版本的MySQL中,连接成功后,我们执行查询SQL,会先执行查询缓存。
也就是说MySQL接受到一个查询SQL请求时,会先去查询缓存看看,如果缓存有这条SQL的查询结果,会直接返回。如果查询缓存没有,就继续往下执行,执行完之后,把结果写入缓存。其中,这个查询缓存是key-value的结果,你可以把它理解为一个map吧,其中key就是这个查询SQL,value则是这个查询的结果。
同时,如果你查询的表进行更新的时候,会清空缓存的。一个表更新比较频繁的话,使用查询缓存命中率会很低,你刚查完放到缓存,更新SQL又清空了,就很不划算。有些时候,一些静态配置表,很少更新的,才建议使用查询缓存。其他更新频繁的表,则不建议使用查询缓存,你可以通过这个参数query_cache_type 设值是否走查询缓存。
其实,MySQL 比较新的版本,如8.0 已经废弃了查询缓存,并且相应的参数 query_cache_type 也不再存在。因为在高并发和大型数据库环境下,查询缓存可能导致性能问题,并且在实际测试中发现,禁用查询缓存可能会提高整体性能和可伸缩性。
分析器
如果查询SQL没有命中查询缓存的话,继续往下执行,就到分析器上场了。它负责分析 SQL 查询语句,验证其语法和语义,确保查询的正确性。
你扔个SQL给MySQL服务器,它肯定需要先解析,才知道这个SQL是做什么的,对吧。它会派出分析器,先做词法分析。你提交过来的查询SQL是由很多个字符创和空格组成的,MySQL会先解析出这些字符串表示什么意思。
select * from test_db.user_info_tab where user_id =123;
它先把关键字select解析出来,然后把user_info_tab解析成表,user_id解析成列名。做完词法分析之后,开始做语法分析。语法分析主要就是判断,你的SQL是否满足MYSQL的语法。
如果你的SQL写错了,语法分析就会报错误提示: ERROR 1064 (42000): You have an error in your SQL syntax;
mysql> select * rom test_db.user_info_tab where user_id =123;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'rom test_db.user_info_tab where user_id =123' at line 1
平时大家看到这个错误的时候,只需要,关注关键词 syntax to use near 就可以快速知道哪里写错啦。比如这个例子,就是我的from写错了,少了f。
优化器
经过分析器之后,MySQL已经知道需要做什么了。但是在经过执行器之前,还会先经过优化器。优化器做的事情就是,怎么去做才是最好的。对于一条查询SQL来说就是:怎么去查是最佳效率的。
比如这个查询SQL:
select * from test_db.user_info_tab where user_id =123 and user_name='田螺';
其中,在user_info_tab表中,user_id为索引字段,user_name也是索引字段。
这条SQL执行的时候,可能使用索引user_id,也可能使用使用user_name。选择不同的索引,执行效率是不一样的。具体怎么选择,就是优化器所做的事情。
大家是否还记得explain。我们使用它加在我们查询的SQL,就可以帮助了解优化器在执行查询时,选择的执行计划和相应的优化策略。
经过优化器之后,就来到了执行器阶段。也就是真正执行查询SQL了。
执行器
select * from test_db.user_info_tab where user_id =123 ;
在要开始执行时候,会判断一下,该用户是否对这个SQL有查询的权限,如果没有,则会报权限错误。如果有权限的时候,打开表直接执行。执行的过程,其实类似于执行调用引擎提供的接口。
我们现在假设user_id不是索引字段,我们使用的是InnoDb存储引擎,这个查询SQL执行过程就是这样:
- 调用
InnoDb存储引擎提供的接口,获取user_info_tab表的第一行。 - 判断
user_id是不是为123,如果不是,跳过这一行。如果是,把这一行放到结果集。 - 调用
InnoDb存储引擎提供的接口,获取user_info_tab表的下一行。 - 判断
user_id是不是为123,如果不是,跳过这一行。如果是,把这一行放到结果集。 - 重复3、4步骤,一直扫描完
user_info_tab表的所有行。最后把结果集返回客户端。
聊到这里,其实一条查询SQL的执行过程,已经讲完啦,是不是很简单呀~~

关注公众号↑↑↑:DotNet开发跳槽❀