
一个SQL的执行过程详解
链接:https://www.jianshu.com/p/e2926d6a808f
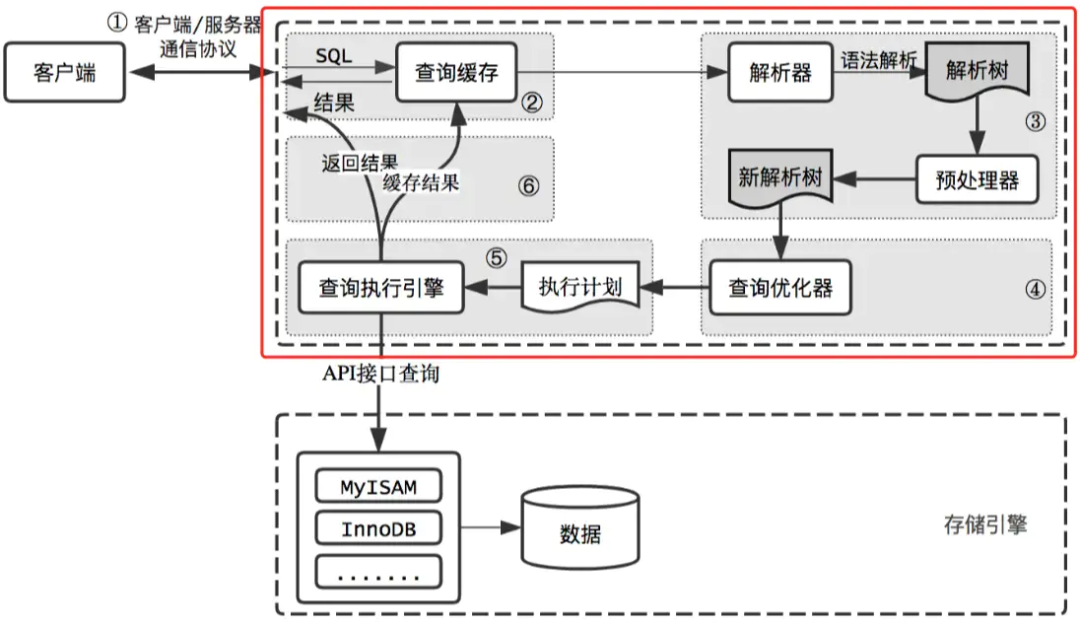
一、 组成部分
客户端,如:php 的 pdo_mysql扩展。MySQL 服务:
二、 大概流程
MySQL server 层的 连接器对来自客户端的连接进行验证,包含:MySQL server 层的 查询缓存对客户源原始SQL进行缓存命中检测:命中则直接返回,未命中则进一步执行查询。MySQL server 层的
解析器对查询语句进行解析,得到查询语句的解析树。MySQL server 层的
预处理器对解析树进一步验证。MySQL server 层的
优化器将解析树转化为执行计划。MySQL 存储引擎 层得到执行结果,返回给 MySQL server 层。MySQL server 层将结果交由
查询缓存进行缓存,并返回给客户端
三、 查询缓存
关键逻辑:
`查询缓存` 缓存了 `执行计划` 的完整结果,当缓存命中时,直接返回缓存中的结果,从而跳过了 `解析-优化-执行` 的过程。
`查询缓存` 可以理解将 `执行计划` 的结果缓存在 hashtable 中,key 是 `客户端发来的原始查询sql` 的 hash 值,因此:
的 hash 值并不相同。即:`即使同一条SQL,如果大小写、空格、单引号、双引号、注释等不同,都会使用不同的缓存 key`
因为在 `查询缓存` 阶段,还没有进行 `解析器` 解析的工作,因此:`所有查询都会尝试去 get 缓存,但总是不命中`。
相关配置: 如果查询结果比较大,超过了query_cache_min_res_unit的值,MySQL将一边检索结果,一边进行保存结果。 根据自身情况设置合适的大小:太大会造成大量的 `内存碎片`,太小又需要 `频繁的申请内存`。 `have_query_cache`,当前的MYSQL版本是否支持“查询缓存”功能。 `query_cache_limit`,能够缓存的最大查询结果,查询结果大于该值时不会被缓存,默认值是 1MB `query_cache_min_res_unit`,查询缓存分配的最小块(字节)。默认值是4096(4KB)。 `query_cache_size`,为缓存查询结果分配的总内存。 `query_cache_type`,默认为on,可以缓存除了以 `select sql_no_cache` 开头的所有查询结果。 `query_cache_wlock_invalidate`,如果该表被锁住,是否返回缓存中的数据,默认是关闭的。 优缺点: 对于频繁变动(`修改表结构、新增、删除、修改数据`)的表,由于一旦 `变动` 就会清除该表的所有缓存,导致:命中率极低,每次SQL还增加了 `查询缓存` 的额外工作。 搜索公众号互联网架构师回复“2T”,送你一份惊喜礼包。 参与 hash 计算的是客户端发来的原始SQL,还未经过 `解析器` 解析,`完全一样` 的sql才能命中缓存。 `查询缓存` 实质上是缓存 `SQL的hash值` 和 `该SQL的查询结果`,省去了大量重复SQL查询的 `解析-优化-执行` 过程。 优点:
四、 `解析器` 和 `预处理器`
解析器 和 预处理器 的工作主要包含:对
原始SQL进行语法解析,验证语法规则,如:关键字是否正确
得到 `语法解析树` 进一步验证 语法解析树,如:库、表是否存在
调用函数、识别别名等
五、 优化器
优化器是基于Cost-Based Optimizer模型,预估每条执行方式的成本,选择成本最小的执行方式,转化为执行计划。每种执行方式的成本 cost预估包含几个方面:Cost-Based Optimizer对复杂语句的成本预估会产生偏差,这时候就需要用到我们了,哈哈。
六、 存储引擎
具体的 执行计划 如何执行,依赖于各种不同的 存储引擎 的索引算法,如:
七、 结果返回客户端
增量、逐步返回 的过程。即:在查询生成第一条结果时,MySQL就可以开始向客户端逐步返回结果集了。正文结束
1.心态崩了!税前2万4,到手1万4,年终奖扣税方式1月1日起施行~

评论