来源丨https://zhuanlan.zhihu.com/p/264887767
本文作者从图像空间、特征空间、 Loss profile 空间以及 利用backpropagated gradient信息做异常检测四个方面,结合2019年和2020的顶会论文,对工业图像上的异常检测的最新进展进行了总结。
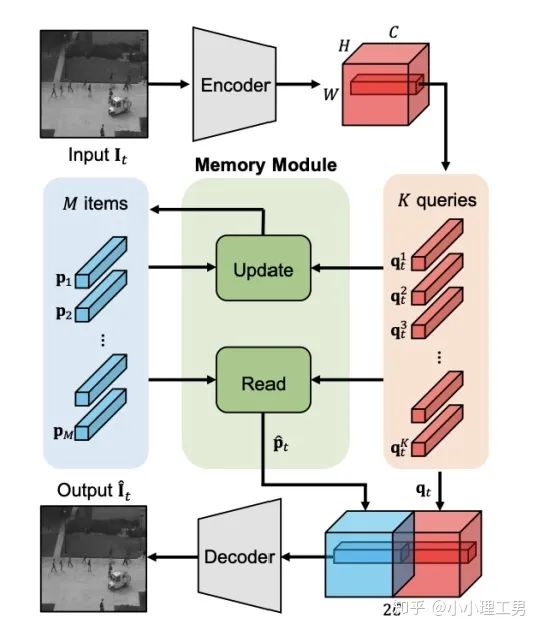
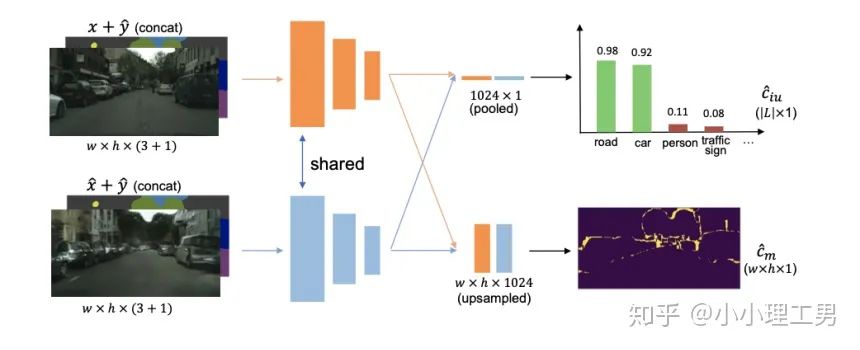
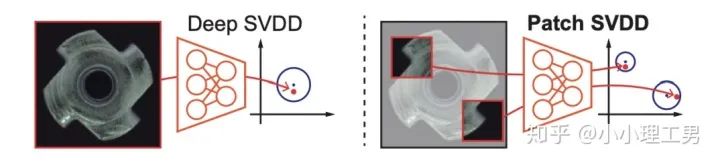
写在前面 这里对我最近的研究领域——工业图像上的异常检测中最新的一些进展做一个总结。主要总结的是在2019和2020的一些顶会上,关于Semi-supervised或者Unsupervised anomaly detection的一些比较有意思的文章,并给出我自己的一些看法。 由于水平有限,所以大家辩证地看就好,如有不当之处或可补充之处,欢迎指正~ 1. 简要地介绍一下什么是异常检测(anomaly detection) 如果将每个样本看作空间中的一个点的话,异常(anomaly)简单地来说就是离群点 ,或者说是“非主流”的点,即离大多数样本点都比较远。这里隐藏的意思是,异常通常是少数 。 下图很形象地展示了什么是异常。其中,黑色的点为正常的样本点,红色的点为异常点样本点。(更多的介绍可以参考Kiwi:异常检测概述(一):An Overview of Anomaly Detection Part I https://zhuanlan.zhihu.com/p/50384515 ) 异常检测的任务,就是找到正常样本与异常样本之间的界线,尽可能地将正常样本与异常样本分开。这里的界线,可以是在各种空间中的,例如图像空间、特征空间,甚至后文会介绍到的一篇论文中的loss profile空间(现在可能看到这个比较懵逼,后面的文章会介绍这篇文章,还是挺有意思的)。 目前实际的异常检测遇到的一个很大的困难,是在实际的场景中(例如工业流水线等),异常样本往往很难获得,甚至很多时候没有异常样本。这就迫使我们采用semi-supervised或者unsupervised的方法。接下来介绍的文章也都是semi-supervised或者unsupervised的方法。 下面我将以做异常检测的空间为划分标准,将最近的一些新方法做一个分类。预计将分3-4篇文章介绍完。 2. 图像空间上的异常检测方法 图像空间上的异常检测一般采用的是下图的Auto-encoder结构。 图像空间上的异常检测方法的主流结构 主要的思想是,如果我们只在正常样本的训练集上训练我们的Auto-encoder,则我们重构出来的图像会比较趋近于正常样本。利用这一个假设/性质,在推理阶段,即使输入的图像是异常样本,我们重构出来的图像也会像正常样本。所以我们只需对比原图和重构后的图,就可以判断输入的图像是否为异常,甚至可以定位到异常区域。 2.1 MemAE :利用Memory抑制模型的泛化能力 上文所说的Auto-encoder框架其实隐藏了一个问题:机器学习模型一般都是具有泛化能力的。也就是说,即使我们在只有正常样本的训练集上训练,在推理阶段,如果输入异常样本,由于泛化能力的存在,我们的模型也有一定的概率输出类似于异常的样本。这时候我们对比原图和重构后的图像,会发现非常相似... 这时候我们的异常检测方法就失效了QwQ。 所以ICCV 2019的一篇文章提出了MemAE来显式地抑制Auto-encoder的泛化能力。他们的思路是,既然Auto-encoder泛化能力有时候会过强,那么如果让输入decoder的embedding都由正常样本的embedding组合而成,能够预计decoder输出的重构图像也主要由正常样本的特征组成。这样,通过抑制泛化能力来逼迫重构后的图像贴近于正常样本。 具体做法是,将所有正常样本经过encoder得到的embedding保存在Memory中。当输入一个图像时,首先用encoder提取出其embedding,并逐一计算图像的embedding和memory中的各个embedding的相似度(例如cosine similarity),再用相似度作为权重,将memory中的embedding加权平均得到新的embedding。 得到的这个新的embedding将同时具有两个特点: 再将这个新的embedding输入decoder中,就可以得到既接近于原图、又贴近于正常样本的图像了。 首先是在加权Memory中embedding时weight的计算:
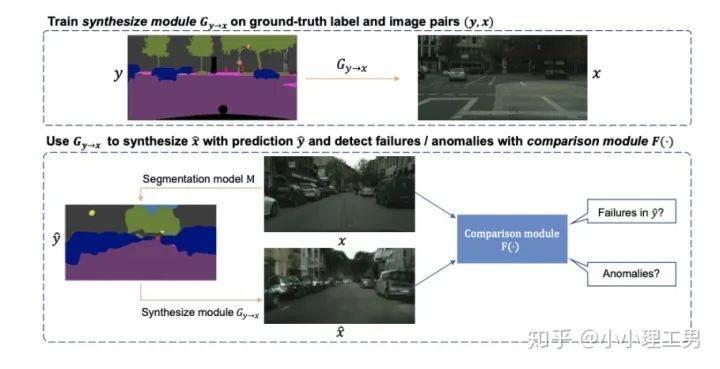
其中 为输入图像的embedding, 为memory中第 个embedding, 为 对应的权重。 文章中提到了一个有趣的现象,当memory中参与融合的embeding过多时,重构后的图像在异常检测中的效果会下降。这样比较好理解:毕竟正常的要素过多,也会组成异常。 为了抑制这个现象,文章中限制了参与融合的embedding个数。一种比较naive的方式如下: 优点: 这篇文章提出了一个非常好的想法来抑制auto-encoder的泛化能力——加入只由正常样本特征构成的memory。据我所知,这应该是第一篇将memory引入异常检测的文章,能够算是一篇挖坑之作。后续也有文章跟进这一方面的研究。缺点: 一般来说由于缺少类似于U-net中的skip connection的存在,auto-encoder重构出来的图像一般都比较糊。此篇也不例外。这就给异常区域的定位带来了一定的困难。所以可以看到此篇文章的实验都是在比较简单的数据集上(例如MNIST, cifar10等)做的实验,而且只能将图片分类为正常或异常,而不能定位到异常的位置。我觉得后续如何在只用正常样本的特征情况下,重构出清晰的图,从而定位到异常区域位置也是一个可以挖的点。2.2 Memory的进一步改进 这是CVPR 2020的一篇文章,可以看作是在上一篇文章之上的升级版。我个人认为这篇文章对上一篇文章的改进之处主要有以下几点: 增加了memory update的机制,只需存储固定个数的memory; 引入了feature compactness loss 和 feature separateness loss,减少需要保存的memory的数量; 采用了将原图的embedding和memory中的embedding结合输入decoder的方式,一定程度上解决了重构后的图像比较糊的缺点,从而可以定位到异常区域的位置,从而可以运用到一些更加复杂、贴近现实情况的数据集上。 这里主要介绍一下feature compactness loss和feature separateness loss。 feature copactness loss的作用是使得memory中的embedding和数据集中图像的embedding尽可能的接近。其计算公式如下图。具体地,对于图像的每一个embedding feature compactness loss公式. K为一个图像的embedding (query) 的个数,T为视频的帧数 feature separateness loss的作用则是使得memory中的embedding相距越大越好。想象一下,如果仅有feature compactness loss,则memory中的embedding会有一种趋于一致的趋势,那么memory就没有什么存在的意义了。 feature separateness loss的计算公式如下。对于图像的每一个embedding 2.3 利用bad quality reconstructed image做异常检测 这是CVPR 2020的一篇论文中的工作,是一种无监督异常检测的方法,模型名称为OGNet。 OGNet框架 这篇文章总体不是严格的Auto-encoder架构,而是采用另一种在异常检测领域也比较常用的架构——GAN。一般的用GAN做异常检测有两种思路: 用generator重构图像,discriminator只是用来帮助generator更好地重构图像。在判断异常时,类似于auto-encoder检测异常的思路,用generator重构后的图像和原图做对比,不同处认为是异常; 总体思路与1中类似,只是在检测异常时,综合generator和discriminator的结果作为判断异常的依据。 这篇文章的亮点就是将discriminator的任务做了转化:区分图像为原图还是generator生成的图 -> 区分是高质量重构图像还是低质量重构图像。 按照文章中的说法,这样可以使得在判断异常时,discriminator更能找到generator重构异常图像时的细微的扰动,从而更加取得更好的异常检测效果。第一个阶段按照通常的方法训练GAN,即generator负责重构图像,discriminator负责判断图像为原图还是重构的图像; 第二阶段选用两个generator:一个是第一阶段中训练好的generator(即图中的 此外,文章中还提出了另一种bad quality examples——伪异常重构图像(pseudo-anomaly recontructed image),即人为地伪造异常的图像。伪异常重构图像生成的方式如下图所示,即从训练集中随机选取两张图像,用 伪异常重构图像(pseudo-anomaly recontructed image)生成示意图 第一阶段中discriminator的任务和传统的方法相同,即判断图像为原图还是重构后的图像。如下图(6)式所示。 第二阶段中discriminator的任务发生了变化,原图 数据增强。用不充分训练的generator和人为伪造出来的异常图像作为负样本,来训练discriminator; 异常检测任务转移。将检测异常的任务从generator或者generator与discriminator共同承担,转移到由discriminator承担 2.4 利用image segmentation信息做异常检测 这是发表在ECCV 2020的一篇文章。也是做无监督的异常检测。 文章的核心方法是从image segmentation的结果出发,利用cGAN重构图像,再将重构后的图像与原图做比较,不同之处认为是异常。整个异常检测的流程为: 原图 -> image segmentation结果 -> 基于segmentation结果重构后的图像 -> 对比,检测异常 说白了就是用image segmentation模型和cGAN替代之前auto-encoder框架中auto-encoder的角色,不算是一个特别有意思的story。 文章除了上述用到了cGAN来重构图像的亮点之外,还将failure detection和anomaly detection融合到了同一个框架中,如下图所示。不过据我读文章时的认识,failure detection和anomaly detection只是流程框架一致,但是不能同时处理,更不能相辅相成。如果我理解的没错的话,也没有太多的意思。 特征空间的方法主要是将图像的数据通过某种方法映射到特征空间上,再通过特征空间中的距离判断是否为特征。 相比于图像空间上的异常检测,我个人更看好在特征空间上的异常检测。因为特征空间表达的是比图像空间更高层次、更抽象的信息;而且特征空间更加灵活,因为特征空间可以有非常多种定义,而图像空间只有一个。 3.1 利用teacher和students的差异做异常检测 这是CVPR 2020上的一篇文章,主要用teacher-students框架做无监督的异常检测。值得一提的是,这篇文章的作者也是MVTec AD这个异常检测数据集的提出者。所以这篇文章比较有借鉴意义。虽然他们没有公开代码,但是我自己曾复现过他们的结果,指标上还是基本一致的。 在仅包含正常样本的数据集上,让pretrained的teacher模型去教没有pretrain的student模型,使得teacher模型和student模型输出的embedding尽可能一致。那么在inference时,由于teacher只教过student如何embed正常样本,所以正常样本上teacher模型和student模型输出的embedding会比较相似,但异常样本上两者输出的embedding差异会比较大; 如果在1中的训练过程中,采用多个随即初始化的students模型和一个pretrained teacher模型,那么在正常样本上students之间的embedding比较一致,而在异常样本上,由于students是随机初始化的,且teacher并没有在异常样本上教过他们,所以在students之间embedding差异也会比较大。 利用这两个假设,在inference时,如果在某个样本上,teacher和students的embedding差异比较大,且students的embeddings之间差异也比较大,那么就说明该样本为异常样本。 此外,为了定位异常的位置,而不是仅仅判断某张图片是否为异常,teacher和students的输入是图片的patch,而不是整张图像。 这样,当在某个patch上teacher和students表现差异很大,或者students之间表现差异很大时,就可以认为这个patch为异常,从而定位到了异常的区域。 多尺度。由于模型的输入都是patch,所以patch的大小直接决定了异常检测的resolution。由于图像中的异常大小不尽相同,当异常区域比较大时,用比较大的patch可能会比较好;反之,比较小的patch效果会比较好。所以文章中采用了三种边长的正方形patch: 17, 33和64(单位为pixel)。将这三种patch size的结果做算数平均就得到了multi-scale的结果; 如何pretrain模型。现在有很多unsupervised pretrain的方法,例如MoCo。但是文章没有采用这种unsupervised方法,而是用pretrained resnet-18,通过蒸馏得到了teacher模型。我个人比较困惑的一点是为什么不直接用pretrained resnet-18,可能是为了更快吧...(迷) 优点:teacher students这个框架用在异常检测还是比较有新意的。这种方法既利用了在异常数据上pretrain过的模型和没有pretrain过的模型的差异,也利用了没有pretrain过的模型之间的差异;此外multi-scale也可以勉强算一个新意... 缺点:multi-scale过于粗糙,只采用三种patch size的结果叠加;另外复现出来之后看结果会发现一个比较致命的缺点,但是由于我目前做的工作与之相关,所以暂时保密 :-) 3.2 以patch为单位做SVDD 这是一篇挂在arxiv上的文章,主要将SVDD方法从以图像为单位扩展到了以patch为单位。SVDD是一个比较“古老”的one-class classification方法,因为异常检测也可以看作是一个one-class classification(正常样本为一类,之外的都是异常样本),所以SVDD通常也用作异常检测。 SVDD的主要思想是,用某种方法将样本投射到某个特征空间中,计算出所有样本投影的中心点,再规定一个半径 SVDD和Depp SVDD都有一个缺点,那就是他们处理的都是整个图像,也就是说,在投影的过程中将每个图像对应特征空间中的一个点。这样的缺点是,我们只能判别这个图像是否为异常,但是不能定位异常的区域。 所以patch SVDD做的事情就是将处理的对象从整个图像变为patch,每个patch对应特征空间上的一个点。 此外,由于不同的patch的特征可能会非常不同,即使是正常样本的patch,在特征空间中的距离也可能非常远,所以只用一个中心点是不可行的。patch SVDD将SVDD中的一个中心点,改为了用聚类的方式形成多个中心点, patch SVDD用到的backbone就是一个encoder,输入为patch,输出为patch的embedding. 文章的精髓就在于在训练时如何设计监督,使得patch的embedding能够自动地聚类为在多个中心周围(中心的个数是我们无法事先设定的,需要在训练中模型自己生成)。 Training阶段 ,作者设计了两个Loss,用来达到相邻patch的embedding相似,但patch embedding之间具有一定的区分度的效果 。第一个是SVDD loss,计算公式如下:其中 但是如果只用 其中, 如果所有patch embedding都极为相似,那么 Inference阶段,作者通过下面的式子计算patch的anomaly score: 其中 这篇文章的优点在story部分已经介绍得很详细,不再赘述。这里主要讲讲我个人认为的不足之处: 信息提取不充分(这里和我现在做的工作有关,所以不详细说了hhh) 训练时使相邻的patch特征聚合在一起,这个设想不一定合理 对于物品会旋转的类别,判断patch相对方位可能不合理 结构图 这是ECCV 2020 CMU的一篇文章,是一个semi-supervised的异常检测工作。他们提出了一个比较新颖的思路——在loss profile空间上做异常检测。所谓的loss profile,就是在训练过程中loss的记录曲线(横轴为iteration / epoch,纵轴为loss)。 这篇文章观察到了一个现象:当auto-encoder在正常样本为主的训练集上训练时,训练图像中正常区域的reconstruction loss随训练的iteration / epoch增加而稳步下降,而异常区域的reconstruction loss则不断波动。 所以作者提出利用loss随训练次数的变化趋势——loss profile来做异常检测。换句话说,将异常检测的空间从通常的图像空间/特征空间转化到了loss profile空间。因为在训练时训练集只要以正常样本为主即可,所以这个方法是semi-supervised的。 虽然上面的想法听起来很新颖且非常易懂,但是实际上文章的实现是比较复杂的,涉及到的细节非常多。所以这里只介绍模型的大致框架,感兴趣的朋友可以阅读原论文。 如《异常检测最新研究总结(三)》中所说,当需要定位图像中的异常区域时,一般模型的处理单位为图像的patch而不是整张图像。这篇文章为了定位到图像中的异常区域,也是以patch为单位处理。 Neural Batch Sampler是一个RL (reinforcement learing) 模型,其作用就是选出那些使得loss profile差距最大的正常和异常的patches。 这部分就是通常的auto-encoder,输入为图像的patch,输出为重构后的patch predictor用以预测图像中的pixel-wise的异常区域。其输入为经过FIFO Buffer累积的训练时的loss profile,输出为对图像中每个pixel是否为异常的pixel-wise的label。由于是semi-supervised的,所以可以用已知的正常和异常图像的ground truth做监督,得到 优点: 这篇文章最大的优点就是它的insight。利用loss profile做异常检测这个思路是非常新颖的,感觉是一个可以深挖的坑;此外,这个模型还可以定位到异常的位置,且从论文的实验部分可以看出,该模型在工业数据集MVTec AD上表现也还不错。所以是相对成熟的。缺点: 读这篇文章的时候就会发现,其实这篇文章涉及到的模型非常多,训练的tricks也很多。此外个人感觉这个模型虽然复杂,实际效果可能并不和其复杂度成正比,感觉有简化的空间。但是总体来说还是一篇非常不错、非常有借鉴意义的文章。 (CMU的四大之一的名头果然名不虚传)这一篇也是ECCV 2020上的一篇文章,做的是unsupervised的异常检测。他们也提出了一个比较新颖的角度:用backpropagated gradient做异常检测。个人感觉虽然没有上一篇那么新颖,但是这个insight还是非常不错的。 他们也是基于一个重要的观察:当一个auto-encoder在只包含正常样本的训练集上训练好之后,如果再在一个正常样本上训练,则模型通常只需要比较小的update;但是如果再在一个异常样本上训练,由于这个样本不同于之前所有的训练样本,则模型需要比较大的update。update的不同体现在backpropagated gradient上。所以利用gradient的差异(文中用的是cosine similarity),就可以将正常样本和异常样本区分开来。 模型的结构比较简单,其实就是一个auto-encoder。所不同的是他们用的loss。所以下面将重点介绍loss: 总的loss 计算公式如下: 其中, 乍一看很吓人,其实不复杂。 优点: 据我所知应该是第一篇将gradient用于异常检测的文章,虽然gradient在其他领域可能不算是新颖的idea,在异常检测领域还是比较新颖的;此外,如果阅读原论文的话,可以发现文章从Geometric和Theory两个角度对gradient的方法做了解读,让人不明觉厉 :-)缺点: 文章中只用gradient估计了图片的anomaly score,但没有定位anomaly的位置;此外,文章中experiment的datasets比较简单,在更加复杂的异常检测数据集上的表现有待检验。综合来说,这篇文章也算是一篇挖坑之作,虽然个人觉得相对于上一篇loss profile异常检测来说,idea不是那么新颖,且方法也没有那么成熟(数据集较简单且不能定位异常区域)。 到此为止,我最近看到的异常检测方面的最新论文就介绍完毕了(完结撒花~)。感谢大家的阅读、点赞、关注和评论中的鼓励。其实每天看到自己写的文章被阅读、点赞,或者新增了关注还是很开心的。 虽然现在还是一个非常小的号,但是我会一直坚持写下去,一方面是对自己的监督和总结,另一方面,人还是要有点梦想,说不定哪天我就成了百万大V了呢(逃 【1】Gong D, Liu L, Le V, et al. Memorizing normality to detect anomaly: Memory-augmented deep autoencoder for unsupervised anomaly detection[C]//Proceedin gs of the IEEE International Conference on Computer V i sion. 2019: 1705-1714. 【2】Park H, Noh J, Ham B. Learning Memory-guided Normality for Anomaly Detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 14372-14381. 【3】Zaheer M Z, Lee J, Astrid M, et al. Old is Gold: Redefining the Adversarially Learned One-Class Classifier Training Paradigm[C]//Proceedings of the IEEE/CVF Conference on Computer 【4】Xia Y, Zhang Y, Liu F, et al. Synthesize then Compare: Detecting Failures and Anomalies for Semantic Segmentation[J]. arXiv preprint arXiv:2003.08440, 2020. 【5】Bergmann, P., Fauser, M., Sattlegger, D., & Steger, C. (2020). Uninformed students: Student-teacher anomaly detection with discriminative latent embeddings. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 4183-4192). 【6】Bergmann, P., Fauser, M., Sattlegger, D., & Steger, C. (2019). MVTec AD--A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 9592-9600). 【7】He, K., Fan, H., Wu, Y., Xie, S., & Girshick, R. (2020). Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 9729-9738). 【8】Yi, J., & Yoon, S. (2020). Patch SVDD: Patch-level SVDD for Anomaly Detection and Segmentation. arXiv preprint arXiv:2006.16067 【9】Chu W H, Kitani K M. Neural Batch Sampling with Reinforcement Learning for Semi-Supervised Anomaly Detection[D]. Carnegie Mellon University Pittsburgh, 2020. 【10】Kwon G, Prabhushankar M, Temel D, et al. Backpropagated Gradient Representations for Anomaly Detection[J]. arXiv preprint arXiv:2007.09507, 2020. 阅读原文 可以参与异常检测实践


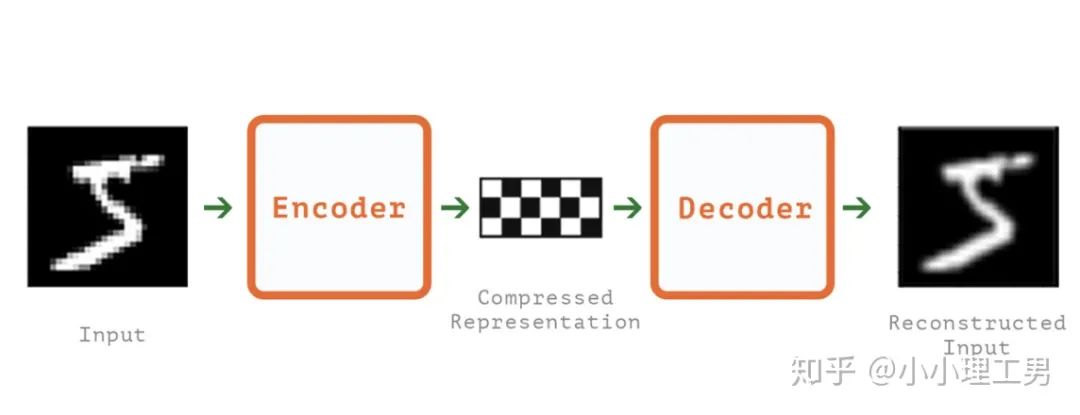 图像空间上的异常检测方法的主流结构
图像空间上的异常检测方法的主流结构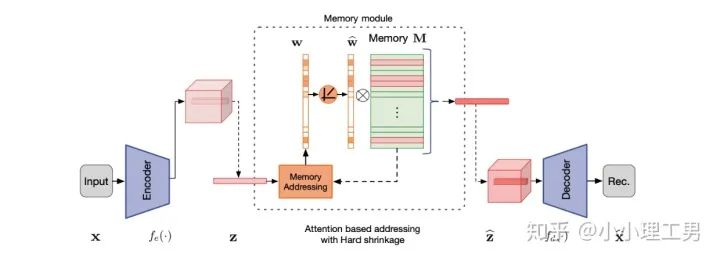
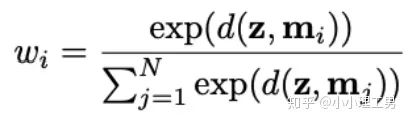
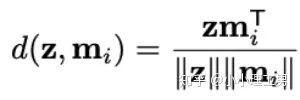
 为输入图像的embedding,
为输入图像的embedding,  为memory中第
为memory中第  个embedding,
个embedding, 为
为

 ,找到memory中与其距离最近的embedding
,找到memory中与其距离最近的embedding  ,使得它们的距离越小越好。
,使得它们的距离越小越好。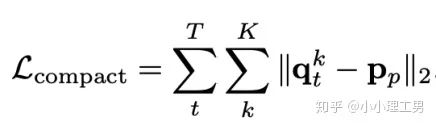
 和距离第二近的embedding
和距离第二近的embedding  ,使得
,使得 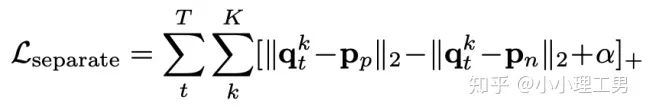
 OGNet框架
OGNet框架 ),另一个是第一阶段中训练的次数较少的generator(即图中的
),另一个是第一阶段中训练的次数较少的generator(即图中的  )。认为
)。认为  (其实这个三角形应该在X上面,但是我查不到怎么打出来QwQ,大家意会一下即可),再将
(其实这个三角形应该在X上面,但是我查不到怎么打出来QwQ,大家意会一下即可),再将  .
.
 和高质量重构图像
和高质量重构图像  为positive的类别,低质量重构图像
为positive的类别,低质量重构图像  和伪异常重构图像
和伪异常重构图像 

 。距离中心点在
。距离中心点在 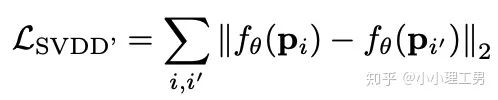
 是encoder,
是encoder, 和
和  是相邻的某两个patch,上面
是相邻的某两个patch,上面  的作用就是让相邻的patch的embedding尽可能接近。
的作用就是让相邻的patch的embedding尽可能接近。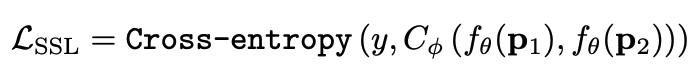
 是一个分类器,
是一个分类器,  是分类的label。大家读到这里可能一头雾水,我结合下面这张图来解释
是分类的label。大家读到这里可能一头雾水,我结合下面这张图来解释  是怎么让不同patch的embedding具有区分度的。
是怎么让不同patch的embedding具有区分度的。
 )周围8个方向分别有8个patch,我们将这8个patch按照相对于中心patch的方位依次标记为
)周围8个方向分别有8个patch,我们将这8个patch按照相对于中心patch的方位依次标记为  。然后从这8个patch中随机选一个patch(记为
。然后从这8个patch中随机选一个patch(记为  ),将
),将  和
和  )输入分类器
)输入分类器 
 为待检测异常的patch,而
为待检测异常的patch,而  则是训练集中正常的patch。通过寻找在embedding空间上与
则是训练集中正常的patch。通过寻找在embedding空间上与 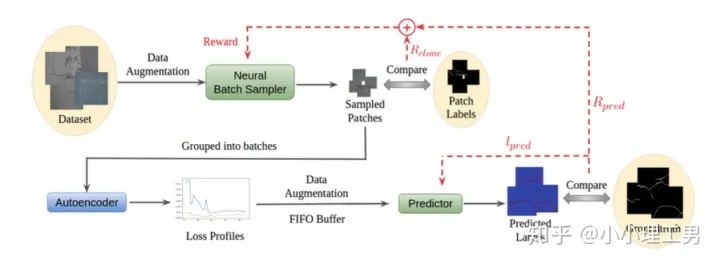 结构图
结构图 ,还可以顺带给neural batch sampler一个reward
,还可以顺带给neural batch sampler一个reward 

 计算公式如下:
计算公式如下: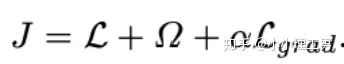
 为reconstruction loss,
为reconstruction loss, 为latent loss,都是auto-encoder中常用的loss,这里就不多加赘述。
为latent loss,都是auto-encoder中常用的loss,这里就不多加赘述。  是文章的重点,正常样本和异常样本的gradient的差异就体现这个
是文章的重点,正常样本和异常样本的gradient的差异就体现这个 
 是当前训练次数,
是当前训练次数, 就是前
就是前  次训练的gradient平均,
次训练的gradient平均,  就是当前训练的gradient。通过计算两者的cosine similarity,如果cosine similarity较小,说明当前训练带给模型的变化较大,
就是当前训练的gradient。通过计算两者的cosine similarity,如果cosine similarity较小,说明当前训练带给模型的变化较大,