
工业图像异常检测最新研究总结(2019-2020)
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
导读
本文作者从图像空间、特征空间、Loss profile 空间以及利用backpropagated gradient信息做异常检测四个方面,结合2019年和2020的顶会论文,对工业图像上的异常检测的最新进展进行了总结。
写在前面
1. 简要地介绍一下什么是异常检测(anomaly detection)

2. 图像空间上的异常检测方法
 图像空间上的异常检测方法的主流结构
图像空间上的异常检测方法的主流结构2.1 MemAE:利用Memory抑制模型的泛化能力
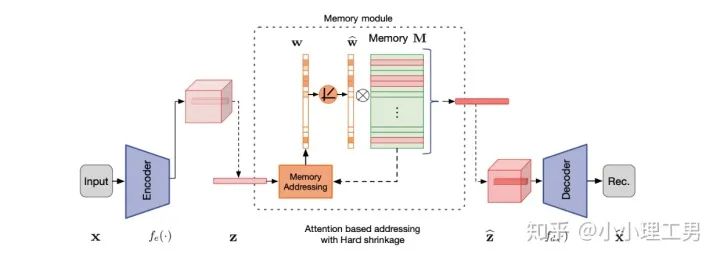
比较接近原本图像的embedding; 由正常样本的特征构成。
首先是在加权Memory中embedding时weight的计算: 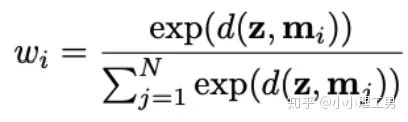

 为输入图像的embedding,
为输入图像的embedding,  为memory中第
为memory中第  个embedding,
个embedding, 为对应的权重。
为对应的权重。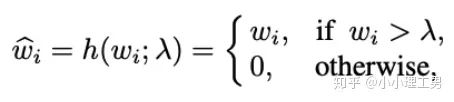
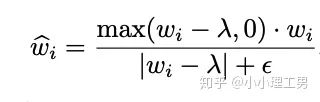
2.2 Memory的进一步改进
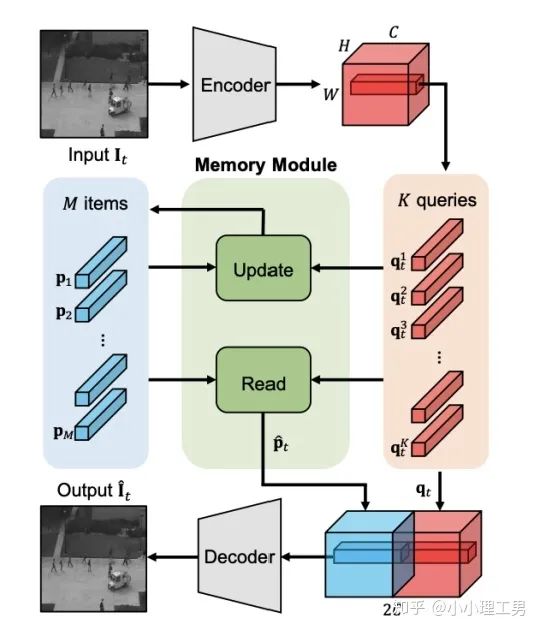
增加了memory update的机制,只需存储固定个数的memory; 引入了feature compactness loss 和 feature separateness loss,减少需要保存的memory的数量; 采用了将原图的embedding和memory中的embedding结合输入decoder的方式,一定程度上解决了重构后的图像比较糊的缺点,从而可以定位到异常区域的位置,从而可以运用到一些更加复杂、贴近现实情况的数据集上。
 ,找到memory中与其距离最近的embedding
,找到memory中与其距离最近的embedding  ,使得它们的距离越小越好。
,使得它们的距离越小越好。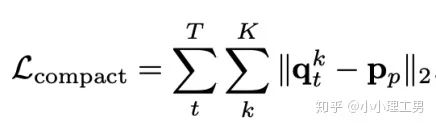 ,找到memory中与其距离最近的embedding
,找到memory中与其距离最近的embedding  和距离第二近的embedding
和距离第二近的embedding  ,使得 和 的距离越小越好, 和 的距离越大越好。
,使得 和 的距离越小越好, 和 的距离越大越好。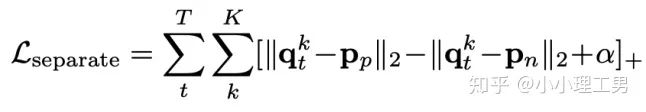
2.3 利用bad quality reconstructed image做异常检测
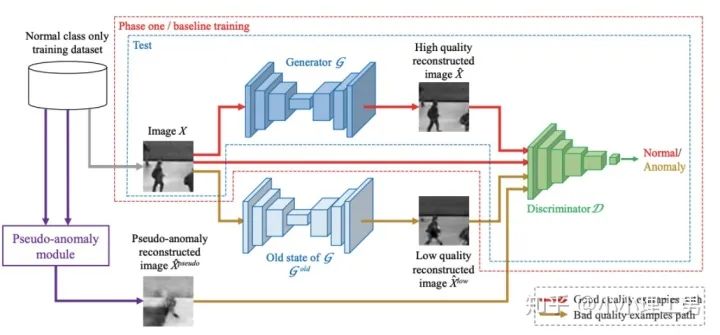 OGNet框架
OGNet框架Story:
用generator重构图像,discriminator只是用来帮助generator更好地重构图像。在判断异常时,类似于auto-encoder检测异常的思路,用generator重构后的图像和原图做对比,不同处认为是异常; 总体思路与1中类似,只是在检测异常时,综合generator和discriminator的结果作为判断异常的依据。
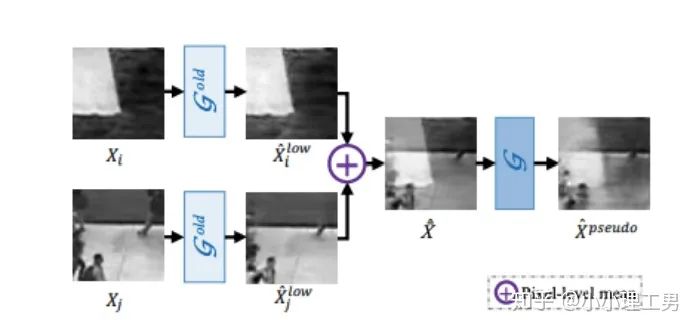
如何生成高质量和低质量的重构图像?
 ),另一个是第一阶段中训练的次数较少的generator(即图中的
),另一个是第一阶段中训练的次数较少的generator(即图中的  )。认为 生成的图像为高质量重构图像, 生成的图像为低质量重构图像。 重构后将结果做pixel-level的平均,得到新的伪异常图像
)。认为 生成的图像为高质量重构图像, 生成的图像为低质量重构图像。 重构后将结果做pixel-level的平均,得到新的伪异常图像  (其实这个三角形应该在X上面,但是我查不到怎么打出来QwQ,大家意会一下即可),再将 用 再重构一遍就得到了伪异常重构图像
(其实这个三角形应该在X上面,但是我查不到怎么打出来QwQ,大家意会一下即可),再将 用 再重构一遍就得到了伪异常重构图像  .
.
 和高质量重构图像
和高质量重构图像  为positive的类别,低质量重构图像
为positive的类别,低质量重构图像  和伪异常重构图像 为negative的类别。如下图(7)式所示。
和伪异常重构图像 为negative的类别。如下图(7)式所示。
数据增强。用不充分训练的generator和人为伪造出来的异常图像作为负样本,来训练discriminator; 异常检测任务转移。将检测异常的任务从generator或者generator与discriminator共同承担,转移到由discriminator承担
2.4 利用image segmentation信息做异常检测
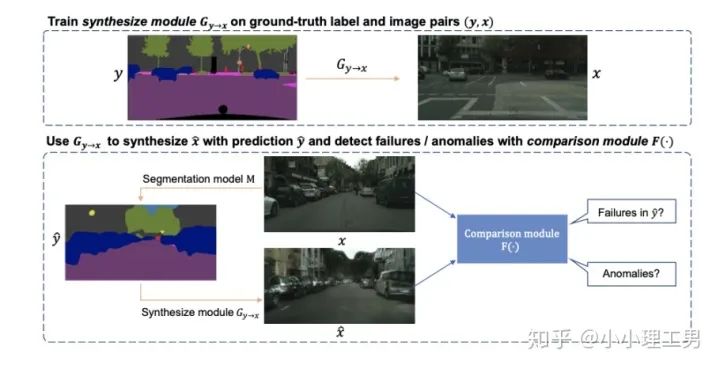

3. 特征空间上的异常检测方法
3.1 利用teacher和students的差异做异常检测
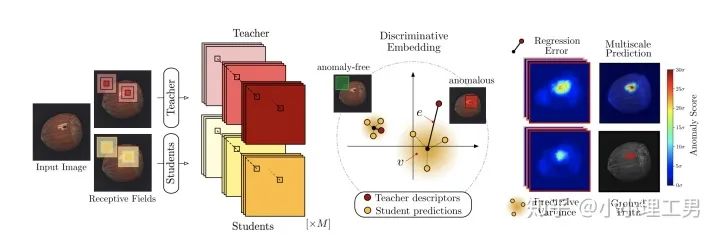
在仅包含正常样本的数据集上,让pretrained的teacher模型去教没有pretrain的student模型,使得teacher模型和student模型输出的embedding尽可能一致。那么在inference时,由于teacher只教过student如何embed正常样本,所以正常样本上teacher模型和student模型输出的embedding会比较相似,但异常样本上两者输出的embedding差异会比较大; 如果在1中的训练过程中,采用多个随即初始化的students模型和一个pretrained teacher模型,那么在正常样本上students之间的embedding比较一致,而在异常样本上,由于students是随机初始化的,且teacher并没有在异常样本上教过他们,所以在students之间embedding差异也会比较大。
多尺度。由于模型的输入都是patch,所以patch的大小直接决定了异常检测的resolution。由于图像中的异常大小不尽相同,当异常区域比较大时,用比较大的patch可能会比较好;反之,比较小的patch效果会比较好。所以文章中采用了三种边长的正方形patch: 17, 33和64(单位为pixel)。将这三种patch size的结果做算数平均就得到了multi-scale的结果; 如何pretrain模型。现在有很多unsupervised pretrain的方法,例如MoCo。但是文章没有采用这种unsupervised方法,而是用pretrained resnet-18,通过蒸馏得到了teacher模型。我个人比较困惑的一点是为什么不直接用pretrained resnet-18,可能是为了更快吧...(迷)
3.2 以patch为单位做SVDD
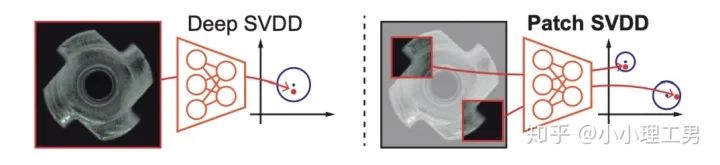
 。距离中心点在 以内的认为是正常样本,否则认为是异常样本。Deep SVDD则是将这个投影的过程用深度神经网络处理,所以在SVDD前加了Deep。
。距离中心点在 以内的认为是正常样本,否则认为是异常样本。Deep SVDD则是将这个投影的过程用深度神经网络处理,所以在SVDD前加了Deep。
 是encoder,
是encoder, 和
和  是相邻的某两个patch,上面
是相邻的某两个patch,上面  的作用就是让相邻的patch的embedding尽可能接近。 ,那么模型就会有让所有的patch都输出同一个embedding的趋势,这肯定不是我们想要的。所以作者加入了另一个loss,SSL(self-supervised learning) loss,来使得不同patch的embedding具有一定区分度:
的作用就是让相邻的patch的embedding尽可能接近。 ,那么模型就会有让所有的patch都输出同一个embedding的趋势,这肯定不是我们想要的。所以作者加入了另一个loss,SSL(self-supervised learning) loss,来使得不同patch的embedding具有一定区分度: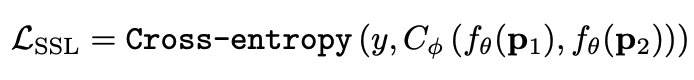 是encoder,
是encoder,  是一个分类器,
是一个分类器,  是分类的label。大家读到这里可能一头雾水,我结合下面这张图来解释
是分类的label。大家读到这里可能一头雾水,我结合下面这张图来解释  是怎么让不同patch的embedding具有区分度的。
是怎么让不同patch的embedding具有区分度的。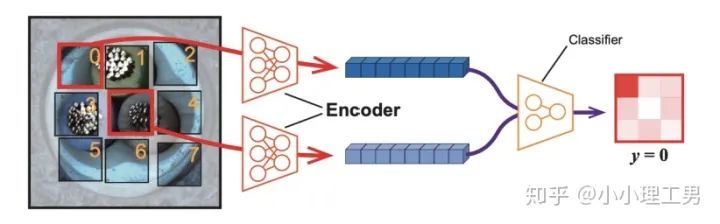
上图中,中间的patch(记为
 )周围8个方向分别有8个patch,我们将这8个patch按照相对于中心patch的方位依次标记为
)周围8个方向分别有8个patch,我们将这8个patch按照相对于中心patch的方位依次标记为  。然后从这8个patch中随机选一个patch(记为
。然后从这8个patch中随机选一个patch(记为  ),将 和 的embedding(分别是
),将 和 的embedding(分别是  和
和  )输入分类器 中,让 来分类 相对于 的方位(即标签 ),最后用Cross Entropy Loss来计算分类器结果和标签之间的损失。 将无法分辨出相邻patch之间的相对方位,就会非常大。这样就通过加入 避免了patch embedding完全一致的情况。
)输入分类器 中,让 来分类 相对于 的方位(即标签 ),最后用Cross Entropy Loss来计算分类器结果和标签之间的损失。 将无法分辨出相邻patch之间的相对方位,就会非常大。这样就通过加入 避免了patch embedding完全一致的情况。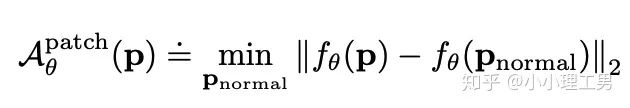
 为待检测异常的patch,而
为待检测异常的patch,而  则是训练集中正常的patch。通过寻找在embedding空间上与 最近的那个正常patch,计算它们俩embedding之间的距离,作为 的anomaly score。即与正常patch的最近距离越大,异常越严重。
则是训练集中正常的patch。通过寻找在embedding空间上与 最近的那个正常patch,计算它们俩embedding之间的距离,作为 的anomaly score。即与正常patch的最近距离越大,异常越严重。信息提取不充分(这里和我现在做的工作有关,所以不详细说了hhh) 训练时使相邻的patch特征聚合在一起,这个设想不一定合理 对于物品会旋转的类别,判断patch相对方位可能不合理
4. Loss profile 空间上做异常检测
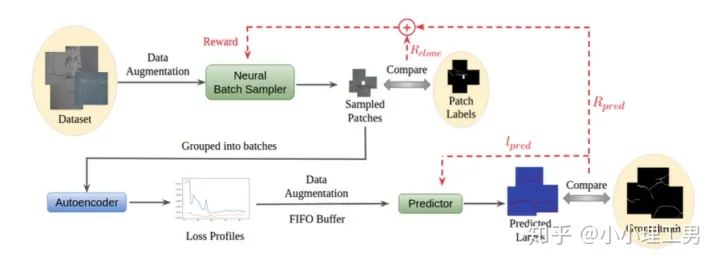 结构图
结构图Neural Batch Sampler
 ,还可以顺带给neural batch sampler一个reward
,还可以顺带给neural batch sampler一个reward 
5. 利用backpropagated gradient信息做异常检测
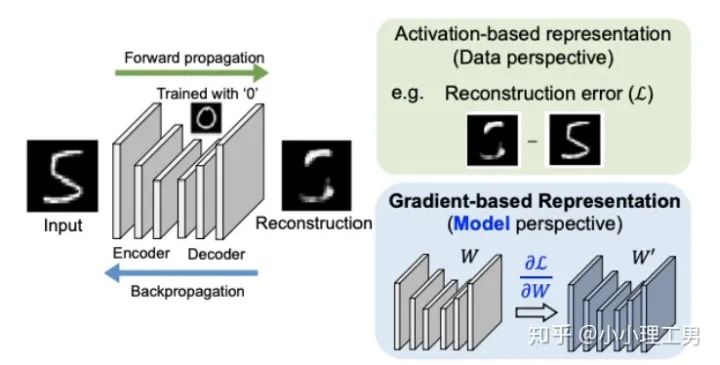
 计算公式如下:
计算公式如下: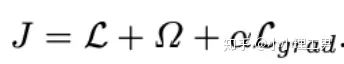
 为reconstruction loss,
为reconstruction loss, 为latent loss,都是auto-encoder中常用的loss,这里就不多加赘述。
为latent loss,都是auto-encoder中常用的loss,这里就不多加赘述。  是文章的重点,正常样本和异常样本的gradient的差异就体现这个 上。 的计算公式如下:
是文章的重点,正常样本和异常样本的gradient的差异就体现这个 上。 的计算公式如下:
 是当前训练次数,
是当前训练次数, 就是前
就是前  次训练的gradient平均,
次训练的gradient平均,  就是当前训练的gradient。通过计算两者的cosine similarity,如果cosine similarity较小,说明当前训练带给模型的变化较大, 也较大;反之说明当前训练对模型改变不大, 也相应较小。
就是当前训练的gradient。通过计算两者的cosine similarity,如果cosine similarity较小,说明当前训练带给模型的变化较大, 也较大;反之说明当前训练对模型改变不大, 也相应较小。写在后面
评论