
图像异常检测
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达


在机器学习中,处理异常检测任务是很常见的。数据科学家经常遇到必须显示,解释和预测异常的问题。在这篇文章中,我们主要讲述:从时间序列交换为图像。给定一张图像,我们要实现双重目的:预测异常的存在并对其进行个性化处理,从而对结果进行丰富多彩的表示。
我们从互联网上获得了数据:裂缝数据集包含墙壁裂缝的图像(URL格式)。提供了1428张图像:其中一半显示了新的且未损坏的墙块;其余部分显示了各种尺寸和类型的裂缝。第一步包括发出一个获取请求,以读取图像,调整大小并将其转换为数组格式。
images = []for url in tqdm.tqdm(df['content']):response = requests.get(url)img = Image.open(BytesIO(response.content))img = img.resize((224, 224))numpy_img = img_to_array(img)img_batch = np.expand_dims(numpy_img, axis=0)images.append(img_batch.astype('float16'))images = np.vstack(images)
从下面的示例中你们可以看到,在我们的数据中显示了不同类型的墙体裂缝,其中一些对我来说也不太容易识别。

开裂和不开裂的例子
我们想要建立一个机器学习模型,该模型能够对墙壁图像进行分类并同时检测异常的位置。为了达到这个双重目的,最有效的方法是建立一个强大的分类器,它将能够读取输入图像并将其分类为“损坏”或“未损坏”。在最后一步,我们将利用分类器学到的知识来提取有用的信息,这将有助于我们检测异常情况。在Keras中,仅需几行代码,这非常容易做到。
vgg_conv = vgg16.VGG16(weights='imagenet', include_top=False, input_shape = (224, 224, 3))for layer in vgg_conv.layers[:-8]:layer.trainable = False
详细地说,我们导入了VGG体系结构,可以训练最后两个卷积块。这将使我们的模型能够专门从事分类任务。为此,我们还排除了原始模型的顶层,将其替换为另一种结构。
x = vgg_conv.outputx = GlobalAveragePooling2D()(x)x = Dense(2, activation="softmax")(x)model = Model(vgg_conv.input, x)model.compile(loss = "categorical_crossentropy", optimizer = optimizers.SGD(lr=0.0001, momentum=0.9), metrics=["accuracy"])
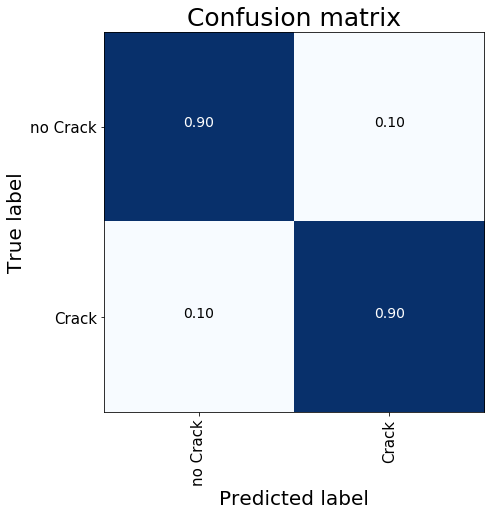
在分类阶段,GlobalAveragePooling层通过取每个要素图的平均值来减小前一层的大小。这种选择加上中间致密层的省略用法,可以避免过度拟合。如果你们可以使用GPU,则培训既简单又容易。COLAB为我们提供了加快这一过程所需的武器。我们还使用了Keras提供的简单数据生成器进行图像增强。最后,我们能够达到0.90的整体精度。
现在,在训练好模型之后,我们将对其进行操作以提取所有有用的信息,以使我们能够在墙壁图像中显示出裂缝。我们试图使此过程变得容易并且很容易在最后用热图表示法看到。我们需要的有用信息位于顶部,特别是我们可以访问:
卷积层:上层是VGG结构,还有网络创建的更多重要功能。我们选择了最后一个卷积层(“ block5_conv3 ”),并在此处剪切了我们的分类模型。我们已经重新创建了一个中间模型,该模型以原始图像为输入,输出相关的激活图。考虑到维度,我们的中间模型增加了初始图像的通道(新功能)并减小了尺寸(高度和宽度)。
最终密度层:对于每个感兴趣的类别,我们都需要这些权重,这些权重负责提供分类的最终结果。
有了这些压缩的物体,我们掌握了定位裂缝的所有知识。我们希望将它们“绘制”在原始图像上,以使结果易于理解且易于看清。“解压缩”此信息在python中很容易:我们只需进行双线性上采样即可调整每个激活图的大小并计算点积。执行一个简单的函数即可访问:
def plot_activation(img):pred = model.predict(img[np.newaxis,:,:,:])pred_class = np.argmax(pred)weights = model.layers[-1].get_weights()[0]class_weights = weights[:, pred_class]intermediate = Model(model.input,model.get_layer("block5_conv3").output)conv_output = intermediate.predict(img[np.newaxis,:,:,:])conv_output = np.squeeze(conv_output)h = int(img.shape[0]/conv_output.shape[0])w = int(img.shape[1]/conv_output.shape[1])act_maps = sp.ndimage.zoom(conv_output, (h, w, 1), order=1)out = np.dot(act_maps.reshape((img.shape[0]*img.shape[1],512)),class_weights).reshape(img.shape[0],img.shape[1])plt.imshow(img.astype('float32').reshape(img.shape[0],img.shape[1],3))plt.imshow(out, cmap='jet', alpha=0.35)plt.title('Crack' if pred_class == 1 else 'No Crack')
我在下面的图像中显示结果,在该图像中,我已在分类为裂纹的测试图像上绘制了裂纹热图。我们可以看到,热图能够很好地泛化并指出包含裂缝的墙块。
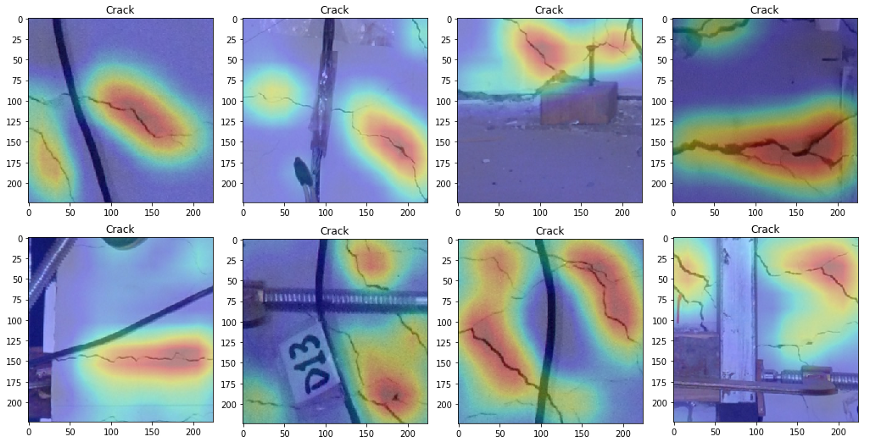
在这篇文章中,我们提供了一种用于异常识别和定位的机器学习解决方案。所有这些功能都可以通过实现单个分类模型来访问。在训练过程中,我们的神经网络会获取所有相关信息,从而可以进行分类。在此阶段之后,我们无需进行额外的工作就组装了最终零件,这些零件告诉我们图像中裂纹的位置!
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~