
有没有什么可以节省大量时间的 Deep Learning 效率神器?
点击左上方蓝字关注我们

1
作者:Fing
https://www.zhihu.com/question/384519338/answer/1160886439

wandb,weights&bias,最近发现的一个神库。
深度学习实验结果保存与分析是最让我头疼的一件事情,每个实验要保存对应的log,training curve还有生成图片等等,光这些visualization就需要写很多重复的代码。跨设备的话还得把之前实验的记录都给拷到新设备去。
wandb这个库真是深得我心,只要几行代码就可以把每一次实验打包保存在云端,而且提供了自家的可视化接口,不用每次都自己写一个logger,也省掉了import matplotlib, tensorboard等一大堆重复堆积的代码块。
最关键的是,它是免费的:)
https://github.com/wandb/client
2
作者:jpzLTIBaseline
https://www.zhihu.com/question/384519338/answer/1196326124
关于实验管理,其他人的回答已经写得十分详细了。虽然我自己还是习惯直接Google Sheet然后在表格里的每一行记录【git commit hashcode】、【server name】、【pid】、【bash script to run exp】、【实验具体结果】、【notes】、【log position】、【ckpt position】,而且Google Sheet增加column以及合并格子用起来还是很flexible的。
这里我提一下其他方面的一些有助于提高效率的工具:
给自己的model起一个酷炫的缩写:http://acronymify.com/
现在越来越多的论文标题(尤其是Deep Learning方向)都是 [model缩写]: [正经论文题目] 的格式,而且一个朗朗上口的名字确实有助于记忆与传播。
写paper时候的用词搭配:https://linggle.com/
作为一个non-native speaker,写paper的时候词语搭配真是让人头秃。这个网站可以比较方便地找一些词语搭配。
手写/截图 转 LaTex公式:https://mathpix.com/
LaTex如果所有公式都要自己手打还是很痛苦的。(虽然很多时候一篇Deep Learning方向的paper公式数量只有十个左右(这还是在强行加上LSTM等被翻来覆去写烂的公式的情况下))
颜色搭配(色盲友好型):http://colorbrewer2.org/
这个网站不仅能很方便找到各种常用的 color schemes,而且都是 grayscale friendly and colorblind-friendly,对于paper里画图帮助比较大。
找前人paper的code:https://paperswithcode.com/
有的时候自己复现真是玄学,这个网站和搜索引擎 "[论文题目] site:http://github.com"配合使用即可。
暂时想到这么多,有空再更。
Update:
文字转语音:https://cloud.google.com/text-to-speech
有的paper需要做一个video来介绍,对自己口语不是很有信心的话可以用G家的text2speech(这个领域Google应该是当之无愧的霸主),还能调节语速,非常贴心。
3
作者:McGL
https://www.zhihu.com/question/384519338/answer/1534457655
写深度学习网络代码,最大的挑战之一,尤其对新手来说,就是把所有的张量维度正确对齐。如果以前就有TensorSensor这个工具,相信我的头发一定比现在更浓密茂盛!
【此处防脱发洗发水广告位火热招租......】
TensorSensor,码痴教授 Terence Parr 出品,他也是著名 parser 工具 ANTLR 的作者。
在包含多个张量和张量运算的复杂表达式中,张量的维数很容易忘了。即使只是将数据输入到预定义的 TensorFlow 网络层,维度也要弄对。当你要求进行错误的计算时,通常会得到一些没啥用的异常消息。为了帮助自己和其他程序员调试张量代码,Terence Parr 写了一个名叫 TensorSensor 的库(pip install tensor-sensor 直接安装) 。TensorSensor 通过增加消息和可视化 Python 代码来展示张量变量的形状,让异常更清晰(见下图)。它可以兼容 TensorFlow、PyTorch 和 Numpy以及 Keras 和 fastai 等高级库。
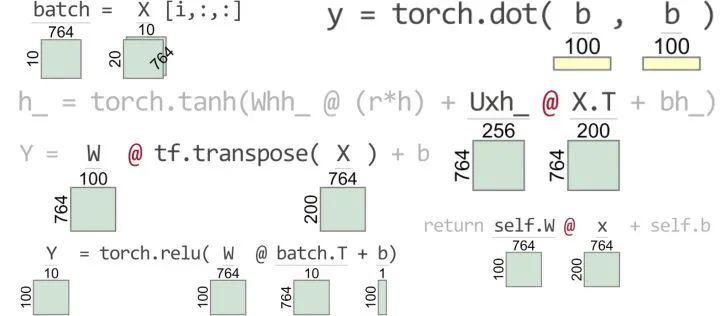
在张量代码中定位问题令人抓狂!
即使是专家,执行张量操作的 Python 代码行中发生异常,也很难快速定位原因。调试过程通常是在有问题的行前面添加一个 print 语句,以打出每个张量的形状。这需要编辑代码添加调试语句并重新运行训练过程。或者,我们可以使用交互式调试器手动单击或键入命令来请求所有张量形状。(这在像 PyCharm 这样的 IDE 中不太实用,因为在调试模式很慢。)下面将详细对比展示看了让人贫血的缺省异常消息和 TensorSensor 提出的方法,而不用调试器或 print 大法。
调试一个简单的线性层
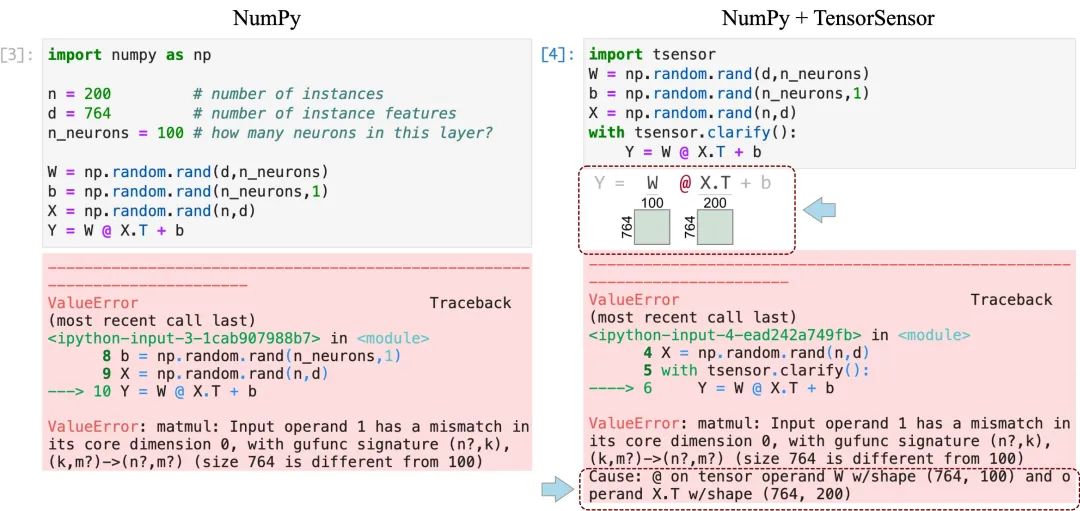
让我们来看一个简单的张量计算,来说明缺省异常消息提供的信息不太理想。下面是一个包含张量维度错误的硬编码单(线性)网络层的简单 NumPy 实现。
import numpy as npn = 200 # number of instancesd = 764 # number of instance featuresn_neurons = 100 # how many neurons in this layer?W = np.random.rand(d,n_neurons) # Ooops! Should be (n_neurons,d) <=======b = np.random.rand(n_neurons,1)X = np.random.rand(n,d) # fake input matrix with n rows of d-dimensionsY = W @ X.T + b # pass all X instances through layer
执行该代码会触发一个异常,其重要元素如下:
...---> 10 Y = W @ X.T + bValueError: matmul: Input operand 1 has a mismatch in its core dimension 0, with gufunc signature (n?,k),(k,m?)->(n?,m?) (size 764 is different from 100)
异常显示了出错的行以及是哪个操作(matmul: 矩阵乘法),但是如果给出完整的张量维数会更有用。此外,这个异常也无法区分在 Python 的一行中的多个矩阵乘法。
接下来,让我们看看 TensorSensor 如何使调试语句更加容易的。如果我们使用 Python with 和tsensor 的 clarify()包装语句,我们将得到一个可视化和增强的错误消息。
import tsensorwith tsensor.clarify():Y = W @ X.T + b
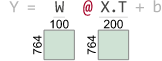
...ValueError: matmul: Input operand ...Cause: @ on tensor operand W w/shape (764, 100) and operand X.T w/shape (764, 200)
从可视化中可以清楚地看到,W 的维度应该翻转为 n _ neurons x d; W 的列必须与 X.T 的行匹配。您还可以检查一个完整的带有和不带阐明()的并排图像,以查看它在笔记本中的样子。下面是带有和没有 clarify() 的例子在notebook 中的比较。
clarify() 功能在没有异常时不会增加正在执行的程序任何开销。有异常时, clarify():
增加由底层张量库创建的异常对象消息。
给出出错操作所涉及的张量大小的可视化表示; 只突出显示异常涉及的操作对象和运算符,而其他 Python 元素则不突出显示。
TensorSensor 还区分了 PyTorch 和 TensorFlow 引发的与张量相关的异常。下面是等效的代码片段和增强的异常错误消息(Cause: @ on tensor ...)以及 TensorSensor 的可视化:
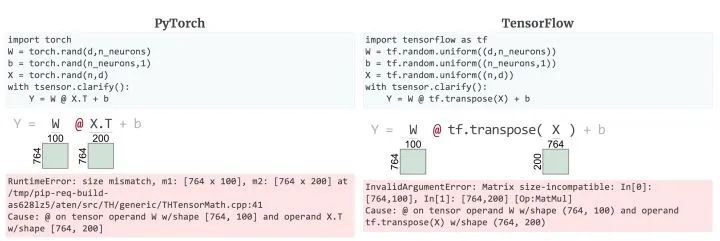
PyTorch 消息没有标识是哪个操作触发了异常,但 TensorFlow 的消息指出了是矩阵乘法。两者都显示操作对象维度。
调试复杂的张量表达式
缺省消息缺乏具体细节,在包含大量操作符的更复杂的语句中,识别出有问题的子表达式很难。例如,下面是从一个门控循环单元(GRU)实现的内部提取的一个语句:
h_ = torch.tanh(Whh_ @ (r*h) + Uxh_ @ X.T + bh_)这是什么计算或者变量代表什么不重要,它们只是张量变量。有两个矩阵乘法,两个向量加法,还有一个向量逐元素修改(r*h)。如果没有增强的错误消息或可视化,我们就无法知道是哪个操作符或操作对象导致了异常。为了演示 TensorSensor 在这种情况下是如何分清异常的,我们需要给语句中使用的变量(为 h _ 赋值)一些伪定义,以得到可执行代码:
nhidden = 256Whh_ = torch.eye(nhidden, nhidden) # Identity matrixUxh_ = torch.randn(d, nhidden)bh_ = torch.zeros(nhidden, 1)h = torch.randn(nhidden, 1) # fake previous hidden state hr = torch.randn(nhidden, 1) # fake this computationX = torch.rand(n,d) # fake inputwith tsensor.clarify():h_ = torch.tanh(Whh_ @ (r*h) + Uxh_ @ X.T + bh_)
同样,你可以忽略代码执行的实际计算,将重点放在张量变量的形状上。
对于我们大多数人来说,仅仅通过张量维数和张量代码是不可能识别问题的。当然,默认的异常消息是有帮助的,但是我们中的大多数人仍然难以定位问题。以下是默认异常消息的关键部分(注意对 C++ 代码的不太有用的引用) :
---> 10 h_ = torch.tanh(Whh_ @ (r*h) + Uxh_ @ X.T + bh_)RuntimeError: size mismatch, m1: [764 x 256], m2: [764 x 200] at /tmp/pip-req-build-as628lz5/aten/src/TH/generic/THTensorMath.cpp:41
我们需要知道的是哪个操作符和操作对象出错了,然后我们可以通过维数来确定问题。以下是 TensorSensor 的可视化和增强的异常消息:
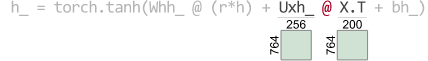
---> 10 h_ = torch.tanh(Whh_ @ (r*h) + Uxh_ @ X.T + bh_)RuntimeError: size mismatch, m1: [764 x 256], m2: [764 x 200] at /tmp/pip-req-build-as628lz5/aten/src/TH/generic/THTensorMath.cpp:41Cause: @ on tensor operand Uxh_ w/shape [764, 256] and operand X.T w/shape [764, 200]
人眼可以迅速锁定在指示的算子和矩阵相乘的维度上。哎呀, Uxh 的列必须与 X.T的行匹配,Uxh_的维度翻转了,应该为:
Uxh_ = torch.randn(nhidden, d)现在,我们只在 with 代码块中使用我们自己直接指定的张量计算。那么在张量库的内置预建网络层中触发的异常又会如何呢?
理清预建层中触发的异常
TensorSensor 可视化进入你选择的张量库前的最后一段代码。例如,让我们使用标准的 PyTorch nn.Linear 线性层,但输入一个 X 矩阵维度是 n x n,而不是正确的 n x d:
L = torch.nn.Linear(d, n_neurons)X = torch.rand(n,n) # oops! Should be n x dwith tsensor.clarify():Y = L(X)
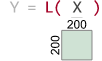
增强的异常信息
RuntimeError: size mismatch, m1: [200 x 200], m2: [764 x 100] at /tmp/pip-req-build-as628lz5/aten/src/TH/generic/THTensorMath.cpp:41Cause: L(X) tensor arg X w/shape [200, 200]
TensorSensor 将张量库的调用视为操作符,无论是对网络层还是对 torch.dot(a,b) 之类的简单操作的调用。在库函数中触发的异常会产生消息,消息标示了函数和任何张量参数的维数。
更多的功能比如不抛异常的情况下解释张量代码,可视化3D及更高维度张量,以及可视化子表达式张量形状等请浏览官方Blog。
参考:
Clarifying exceptions and visualizing tensor operations in deep learning code
4
作者:崔权
https://www.zhihu.com/question/384519338/answer/1206812752
如何在睡觉的时候也调参!?
最近试了一下PFN (Preferred Networks)出品的自动调参工具optuna,觉得使用起来非常方便,在自己的code上也很好集成,写个东西分享一下用法,扒一个PyTorch的example code。
Quick Start Example
optuna的官网还是很有意思的,直接上来就用code说话,贴了一个quick start example code:
import optunadef objective(trial):x = trial.suggest_uniform('x', -10, 10)return (x - 2) ** 2study = optuna.create_study()study.optimize(objective, n_trials=100)study.best_params # E.g. {'x': 2.002108042}
要使用optuna,只需要用户自己定义一个objective函数,剩下的就交给optuna自己完成就行。所以对这个例子的解读我们也分两个部分,第一个是定义objective函数,第二个是optuna对超参的自动优化;
1)定义的objective函数只有一个参数trial,在这个例子里,trial调用了一个函数「suggest_uniform()」,这个函数用来将变量'x'标记为需要optimize的超参,且是从-10到10的uniform分布里采的值。objective函数返回的是需要maximize or minimize的数值 (例如Acc, mAP, 等),这个例子里需要优化的就是(x-2)^2;
2)要使用optuna自动优化超参'x',需要创建一个study对象 (optuna.create_study),然后将objective当作参数传入study的optimize函数就可以实现对超参的自动搜索了。另一个需要给optimize的参数是n_trials,这个参数可以理解为要搜多少次;
等搜完以后就可以用best_params查看最合适的参数啦。
Optuna简介
简单介绍一下optuna里最重要的几个term,想直接看在PyTorch里咋用可以直接跳过。
1)在optuna里最重要的三个term:
(1)Trial:对objective函数的一次调用;
(2)Study:一个优化超参的session,由一系列的trials组成;
(3)Parameter:需要优化的超参;
在optuna里,study对象用来管理对超参的优化,optuna.create_study()返回一个study对象。
2)study又有很多有用的property:
(1)study.best_params:搜出来的最优超参;
(2)study.best_value:最优超参下,objective函数返回的值 (如最高的Acc,最低的Error rate等);
(3)study.best_trial:最优超参对应的trial,有一些时间、超参、trial编号等信息;
(4)study.optimize(objective, n_trials):对objective函数里定义的超参进行搜索;
3)optuna支持很多种搜索方式:
(1)trial.suggest_categorical('optimizer', ['MomentumSGD', 'Adam']):表示从SGD和adam里选一个使用;
(2)trial.suggest_int('num_layers', 1, 3):从1~3范围内的int里选;
(3)trial.suggest_uniform('dropout_rate', 0.0, 1.0):从0~1内的uniform分布里选;
(4)trial.suggest_loguniform('learning_rate', 1e-5, 1e-2):从1e-5~1e-2的log uniform分布里选;
(5)trial.suggest_discrete_uniform('drop_path_rate', 0.0, 1.0, 0.1):从0~1且step为0.1的离散uniform分布里选;
PyTorch Example Code
扒一个官方给的PyTorch例子,链接在这:
https://github.com/optuna/optuna/blob/master/examples/pytorch_simple.py
import osimport torchimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optimimport torch.utils.datafrom torchvision import datasetsfrom torchvision import transformsimport optunaDEVICE = torch.device("cpu")BATCHSIZE = 128CLASSES = 10DIR = os.getcwd()EPOCHS = 10LOG_INTERVAL = 10N_TRAIN_EXAMPLES = BATCHSIZE * 30N_VALID_EXAMPLES = BATCHSIZE * 10
到目前为止是一些package的导入和参数的定义;
def define_model(trial):# We optimize the number of layers, hidden untis and dropout ratio in each layer.n_layers = trial.suggest_int("n_layers", 1, 3)layers = []in_features = 28 * 28for i in range(n_layers):out_features = trial.suggest_int("n_units_l{}".format(i), 4, 128)layers.append(nn.Linear(in_features, out_features))layers.append(nn.ReLU())p = trial.suggest_uniform("dropout_l{}".format(i), 0.2, 0.5)layers.append(nn.Dropout(p))in_features = out_featureslayers.append(nn.Linear(in_features, CLASSES))layers.append(nn.LogSoftmax(dim=1))return nn.Sequential(*layers)def get_mnist():# Load MNIST dataset.train_loader = torch.utils.data.DataLoader(datasets.MNIST(DIR, train=True, download=True, transform=transforms.ToTensor()),batch_size=BATCHSIZE,shuffle=True,)valid_loader = torch.utils.data.DataLoader(datasets.MNIST(DIR, train=False, transform=transforms.ToTensor()),batch_size=BATCHSIZE,shuffle=True,)return train_loader, valid_loader
这一段代码里有个很有趣的用法,定义了一个函数define_model,里面用定义了一个需要优化的变量n_layers,用来搜索网络的层数,所以其实optuna还可以用来做NAS之类的工作,return成nn.Module就可以搜起来了;
def objective(trial):# Generate the model.model = define_model(trial).to(DEVICE)# Generate the optimizers.optimizer_name = trial.suggest_categorical("optimizer", ["Adam", "RMSprop", "SGD"])lr = trial.suggest_loguniform("lr", 1e-5, 1e-1)optimizer = getattr(optim, optimizer_name)(model.parameters(), lr=lr)# Get the MNIST dataset.train_loader, valid_loader = get_mnist()# Training of the model.model.train()for epoch in range(EPOCHS):for batch_idx, (data, target) in enumerate(train_loader):# Limiting training data for faster epochs.if batch_idx * BATCHSIZE >= N_TRAIN_EXAMPLES:breakdata, target = data.view(-1, 28 * 28).to(DEVICE), target.to(DEVICE)# Zeroing out gradient buffers.optimizer.zero_grad()# Performing a forward pass.output = model(data)# Computing negative Log Likelihood loss.loss = F.nll_loss(output, target)# Performing a backward pass.loss.backward()# Updating the weights.optimizer.step()# Validation of the model.model.eval()correct = 0with torch.no_grad():for batch_idx, (data, target) in enumerate(valid_loader):# Limiting validation data.if batch_idx * BATCHSIZE >= N_VALID_EXAMPLES:breakdata, target = data.view(-1, 28 * 28).to(DEVICE), target.to(DEVICE)output = model(data)pred = output.argmax(dim=1, keepdim=True) # Get the index of the max log-probability.correct += pred.eq(target.view_as(pred)).sum().item()accuracy = correct / N_VALID_EXAMPLESreturn accuracy
这里是最重要的objective函数,首先定义了几个需要优化的parameter,「optimizer_name, lr和model里的n_layers和p」。剩下的就是一些常规的训练和测试代码,其中N_TRAIN_EXAMPLES和N_VAL_EXAMPLES是为了筛选出一小部分数据集用来搜索,毕竟用整个数据集来搜还是挺费劲的。
值得注意的是,objective函数返回的是accuracy,讲道理,搜索参数的目标是为了最大化该分类任务的accuracy,所以在创建study object的时候指定了direction为"maximize"。如果定义objective函数时返回的是类似error rate的值,则应该将direction指定为"minimize"。
if __name__ == "__main__":study = optuna.create_study(direction="maximize")study.optimize(objective, n_trials=100)print("Number of finished trials: ", len(study.trials))print("Best trial:")trial = study.best_trialprint(" Value: ", trial.value)print(" Params: ")for key, value in trial.params.items():print(" {}: {}".format(key, value))
这里就是一些optuna的调用代码,很容易理解就不多说了。
自己使用optuna的思路
1)sample个靠谱的子数据集;
2)大概写个objective函数的训练和测试代码,objective函数返回一个需要优化的metric;
3)把要优化的变量定义成optuna的parameter(通过trial.suggest_xxx);
4)copy个main部分代码,开始搜超参;
5)睡觉;
6)醒来用最优的参数在整个数据集上跑跑效果;
在自己的code上试了一下optuna,搜出来的参数和我手调的最佳参数差不太多,感觉还是靠谱的。祝大家使用愉快!
END
点赞三连,支持一下吧↓