
一条SQL引发的“血案”:与SQL优化相关的4个案例
点击关注上方“SQL数据库开发”,
设为“置顶或星标”,第一时间送达干货 SQL专栏 SQL基础知识第二版
SQL高级知识第二版
导读:笔者早年间从事了多年开发工作,后因个人兴趣转做数据库。在长期的工作实践中,看到了数据库工作(特别是SQL优化)面临的种种问题。本文通过几个案例探讨一下SQL优化的相关问题。
作者:马立和 高振娇 韩锋
来源:大数据DT(ID:hzdashuju)

具体分析
SELECT /*+ INDEX (A1 xxxxx) */ SUM(A2.CRKSL), SUM(A2.CRKSL*A2.DJ) ...
FROM xxxx A2, xxxx A1
WHERE A2.CRKFLAG=xxx AND A2.CDATE>=xxx AND A2.CDATE<xxx;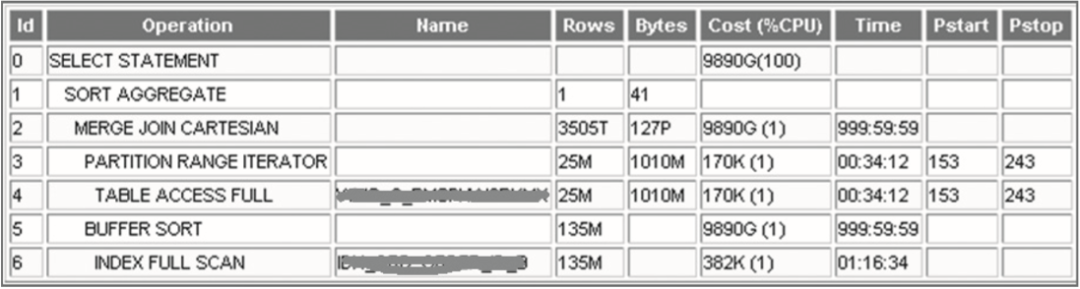
分析结论
开发人员的一个疏忽造成了严重的后果,原来数据库竟是如此的脆弱。需要对数据库保持“敬畏”之心。 电脑不是人脑,它不知道你的需求是什么,只能根据写好的逻辑进行处理。 不要去责怪开发人员,谁都会犯错误,关键是如何从制度上保证不再发生类似的问题。

create table t1 as select * from dba_objects where 1=0;
alter table t1 add id int primary key;
create table t2 as select * from dba_objects where 1=0;
alter table t2 add id varchar2(10) primary key;
insert into t1
select 'test','test','test',rownum,rownum,'test',sysdate,sysdate,'test','test','','','',rownum
from dual
connect by rownum<=3200000;
insert into t2
select 'test','test','test',rownum,rownum,'test',sysdate,sysdate,'test','test','','','',rownum
from dual
connect by rownum<=3200000;
commit;
execdbms_stats.gather_table_stats(ownname => 'hf',tabname => 't1',cascade =>true,estimate_percent => 100);
execdbms_stats.gather_table_stats(ownname => 'hf',tabname => 't2',cascade =>true,estimate_percent => 100);
select * from t1 where id>= 3199990;
11 rows selected.
--------------------------------------------------------------------------------
| Id | Operation | Name |Rows |Bytes|Cost (%CPU)| Time |
---------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 11 | 693 | 4 (0) | 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| T1 | 11 | 693 | 4 (0) | 00:00:01 |
|* 2 | INDEX RANGE SCAN |SYS_C0025294| 11 | | 3 (0) | 00:00:01 |
---------------------------------------------------------------------------------
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
6 consistent gets
0 physical readsselect * from t2 where id>= '3199990';
755565 rows selected.
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2417K| 149M| 8927 (2)| 00:01:48 |
|* 1 | TABLE ACCESS FULL| T2 | 2417K| 149M| 8927 (2)| 00:01:48 |
--------------------------------------------------------------------------
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
82568 consistent gets
0 physical reads字符类型在索引中是“乱序”的,这是因为字符类型的排序方式与我们的预期不同。从“select * from t2 where id>= '3199990'”执行返回755 565条记录可见,不是直观上的10条记录。这也是当初在做表设计时,开发人员没有注意的问题。 字符类型还导致了聚簇因子很大,原因是插入顺序与排序顺序不同。详细点说,就是按照数字类型插入(1..3200000),按字符类型('1'...'32000000')t排序。
select table_name,index_name,leaf_blocks,num_rows,clustering_factor
from user_indexes
where table_name in ('T1','T2');
TABLE_NAME INDEX_NAME LEAF_BLOCKS NUM_ROWS CLUSTERING_FACTOR
-------------- -------------- ---------------- ---------- ---------------------
T1 SYS_C0025294 6275 3200000 31520
T2 SYS_C0025295 13271 3200000 632615
在对字符类型使用大于运算符时,会导致优化器认为需要扫描索引大部分数据且聚簇因子很大,最终导致弃用索引扫描而改用全表扫描方式。
select * from t2 where id between '3199990' and '3200000';
--------------------------------------------------------------------------------
| Id | Operation | Name |Rows|Bytes |Cost(%CPU)| Time |
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 6| 390 | 5 (0)|00:00:01|
| 1 | TABLE ACCESS BY INDEX ROWID| T2 | 6| 390 | 5 (0)|00:00:01|
|* 2 | INDEX RANGE SCAN | SYS_C0025295 | 6| | 3 (0)|00:00:01|
--------------------------------------------------------------------------------
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
13 consistent gets
0 physical reads糟糕的数据结构设计往往是致命的,后期的优化只是补救措施。只有从源头上加以杜绝,才是优化的根本。 在设计初期能引入数据库审核,可以起到很好的作用。

select ... from ...
where
(
(
order_creation_date>= to_date(20120208,'yyyy-mm-dd') and
order_creation_date<to_date(20120209,'yyyy-mm-dd')
)
or
(
send_date>= to_date(20120208,'yyyy-mm-dd') and send_date<to_date(20120209, 'yyyy-mm-dd')
)
)
andnvl(a.bd_id,0) = 1
--------------------------------------------------------------------------------
| Id | Operation | Name |Cost (%CPU)| Time |Pstart | Pstop |
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2470K(100)| | | |
| 1 | SORT GROUP BY | | | | | |
| 2 | TABLE ACCESS BY GLOBAL INDEX ROWID
| XXXX | 5 (0) | 00:00:01 | ROW L | ROW L |
| 3 | NESTED LOOPS | | 2470K (1) | 08:14:11 | | |
| 4 | VIEW |VW_NSO_1| 2470K (1) | 08:14:10 | | |
| 5 | FILTER | | | | | |
| 6 | HASH GROUP BY | | 2470K (1)| 08:14:10 | | |
| 7 | TABLE ACCESS BY GLOBAL INDEX ROWID
| XXXX | 5 (0)| 00:00:01 | ROW L | ROW L |
| 8 | NESTED LOOPS | | 2470K (1)| 08:14:10 | | |
| 9 | SORT UNIQUE | | 2340K (2)| 07:48:11 | | |
| 10 | PARTITION RANGE ALL
| | 2340K (2)| 07:48:11 | 1 | 92 |
| 11 | TABLE ACCESS FULL
| XXXX | 2340K (2)| 07:48:11 | 1 | 92 |
| 12 | INDEX RANGE SCAN
| XXXX | 3 (0)| 00:00:01 | | |
| 13 | INDEX RANGE SCAN | XXXX | 3 (0)| 00:00:01 | | |
--------------------------------------------------------------------------------
select ...
from ...
where
order_creation_date >= to_date(20120208,'yyyy-mm-dd') and
order_creation_date<to_date(20120209,'yyyy-mm-dd')
union all
select ...
from ...
where
send_date>= to_date(20120208,'yyyy-mm-dd') and
send_date<to_date(20120209,'yyyy-mm-dd') and
nvl(a.bd_id,0) = 5
select ...
from ...
where
(
(
order_creation_date>= to_date(20120208,'yyyymmdd') and
order_creation_date<to_date(20120209,'yyyymmdd')
)
or
(
send_date>= to_date(20120208,'yyyymmdd') and
send_date<to_date(20120209,'yyyymmdd')
)
);
--------------------------------------------------------------------------------
| Id | Operation | Name | Cost(%CPU)|Time | Pstart | Pstop |
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 42358 (1)| 00:08:29 | | |
| 1 | SORT AGGREGATE | | | | | |
| 2 | CONCATENATION | | | | | |
| 3 | PARTITION RANGE SINGLE
| | 17393 (1)| 00:03:29 | 57 | 57 |
|* 4 | TABLE ACCESS FULL
| XXXX | 17393 (1)| 00:03:29 | 57 | 57 |
|* 5 | TABLE ACCESS BY GLOBAL INDEX ROWID
| XXXX | 24966 (1)| 00:05:00 | ROWID | ROWID |
|* 6 | INDEX RANGE SCAN
| XXXX | 658 (1)| 00:00:08 | | |
---------------------------------------------------------------------------------
规范的SQL写法,不但利于提高代码可读性,还有利于优化器生成更优的执行计划。 分区功能是Oracle应对大数据的利器,但在使用中要注意是否真正会用到分区特性;否则,可能适得其反,使用分区会导致效率更差。
select...
from xxx a join xxx b on a.order_id = b.lyywzdid
left join xxx c on b.gysid = c.gysid
whereb.cdate>= to_date('2012-03-31', 'yyyy-mm-dd') – 3 and ...
a.send_date>= to_date('2012-03-31', 'yyyy-mm-dd') - 1 and
a.send_date<to_date('2012-03-31', 'yyyy-mm-dd');
--------------------------------------------------------------------------------
|Id | Operation |Name | Rows | Bytes | Cost (%CPU) |Pstart|Pstop|
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 104 | 9743(1)| | |
| 1 | HASH JOIN OUTER | | 1 | 104 | 9743(1)| | |
| 2 | TABLE ACCESS BY LOCAL INDEX ROWID
| XXXX | 1 | 22 | 0(0)| 1189 | 1189|
| 3 | NESTED LOOPS | | 1 | 94 | 9739(1)| | |
| 4 | PARTITION RANGE ITERATOR
| | 1032 | 74304 | 9739(1)| 123 | 518 |
| 5 | TABLE ACCESS FULL
| XXXX | 1032 | 74304 | 9739(1)| 123 | 518 |
| 6 | PARTITION RANGE SINGLE
| | 1 | | 0(0)| 1189 | 1189 |
| 7 | INDEX RANGE SCAN
| XXXX | 1 | | 0(0)| 1189 | 1189 |
| 8 | TABLE ACCESS FULL
| XXXX | 183 | 1830 | 3(0)| | |
--------------------------------------------------------------------------------
exec dbms_stats.gather_index_stats(
ownname=>'xxx',
indname=>'xxx',
partname=>'PART_xxx',
estimate_percent => 10);
统计信息是优化器优化的重要参考依据,一个完整、准确的统计信息是必要条件。往往在优化过程中,第一步就是查看相关对象的统计信息。 分区机制是Oracle针对大数据的重要解决手段,但也很容易造成所谓“放大效应”。即对于普通表而言,统计信息更新不及时可能不会导致执行计划偏差过大;但对于分区表、索引来说,很容易出现因更新不及时出现0的情况,进而导致执行计划产生严重偏差。
最后给大家分享我写的SQL两件套:《SQL基础知识第二版》和《SQL高级知识第二版》的PDF电子版。里面有各个语法的解释、大量的实例讲解和批注等等,非常通俗易懂,方便大家跟着一起来实操。 有需要的读者可以下载学习,在下面的公众号「数据前线」(非本号)后台回复关键字:SQL,就行 数据前线 后台回复关键字:1024,获取一份精心整理的技术干货 后台回复关键字:进群,带你进入高手如云的交流群。 推荐阅读

评论