
一条SQL的奇妙旅行
VOL 157

10
2020-09
今天距2021年112天
这是ITester软件测试小栈第157次推文

点击上方蓝字“ITester软件测试小栈“关注我,每周一、三、五早上 08:30准时推送,每月不定期赠送技术书籍。
微信公众号后台回复“资源”、“测试工具包”领取测试资源,回复“微信群”一起进群打怪。
本文2006字,阅读约需6分钟
工作中我们经常查询数据库,用一个查询,得到想要的数据。可有想过,我们得到答案经过了哪些磨难?经历了哪些诱惑?
以下将以一条SQL的执行过程来了解 MySQL 整体架构,对MySQL有一个全面,清晰的认知,For造航母。
一
开始旅行
第1关
连接器
客户端发送一条查询给服务器,包含客户端相关信息(IP、用户、密码),服务器完成验证。

报告太君,自己人,可以放行! 
第2关
查询缓存
执行查询语句的时候,会先查询缓存,我们会发现某个查询,查询第二次的时候非常快便是这个原因(MySQL8.0 废除这个功能,太鸡肋)。
......

第3关
解析器
第一步:解析你的语法,主要是关键字;

单词别写错了,写错了,我可不会干活。
第二步:解析涉及到的对象是否存在;
人都没有,跟空气聊个啥呢?
第三步:涉及到的对象用户是否有对应的权限。
哎呀,不给钱就不给看,不给看。
第4关
优化器
当语法与语义都没有问题权限也匹配,此时数据库便开始真正为你服务了,根据一定得算法规则,对你的查询进行优化,寻找最优的执行计划。
国家分配的跟自己找的肯定还是不一样的,多数情况下,还是自己找的好。
第5关
执行
先判断数据是否在缓冲池中,若在,直接返回,若不在,则先从磁盘文件中加载到内存。
嘻嘻,反正今天要定了。
第6关
数据返回
数据返回是一边查询,一边返回,并不是一次返回,虽然看上去是一下突然返回的。
BTW,你看见的不一定是真的。
旅行图如下:
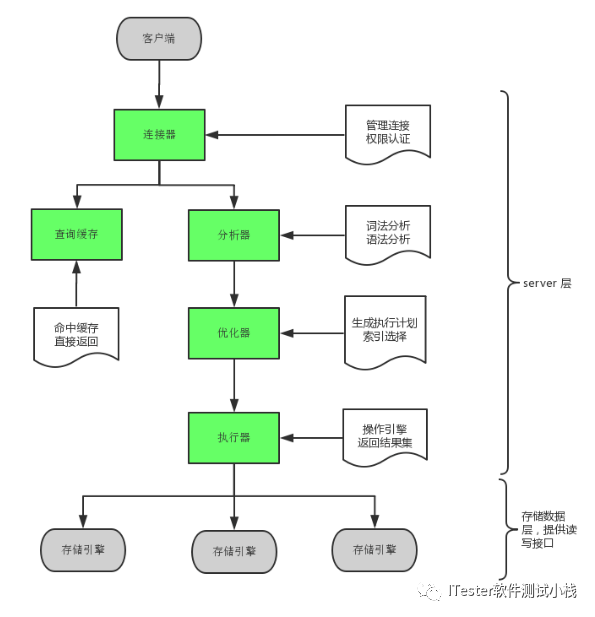
二
MySQL体系结构
最外层客户端:各种语言API连接数据库。
第1层
连接层
包含连接池,身份验证,查询缓存。
第2层
核心服务层
解析器,优化器,跨存储引擎的函数,存储过程,触发器,视图,SQL接口,管理服务工具组件。
第3层
存储引擎层
不同存储引擎即数据的存取方式不同。
第4层
文件系统
文件系统,底层存储数据的磁盘。
MySQL体系架构图如下:
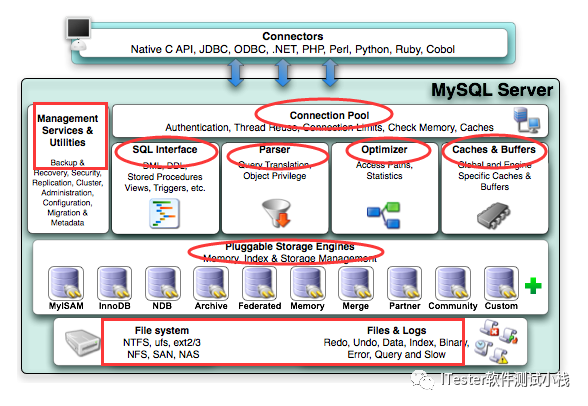
三
InnoDB存储引擎三大特性
特性1
自适应hash索引
B+树的高度一般为3~4层,故需要3~4次的查询,如果观察到建立哈希索引可以带来速度提升,则建立哈希索引,称之为自适应哈希索引(Adaptive Hash Index,AHI) AHI是通过缓冲池的B+树页构造而来,因此建立的速度很快,而且不需要对整张表构建哈希索引。InnoDB存储引擎会自动根据访问的频率和模式来自动地为某些热点页建立哈希索引 --来自INNODB 技术内幕(人工智能赶脚有没有)。
缺点: 跟普通索引一样需要额外开销维护。
特性2
插入缓冲
对于非聚集类索引的插入和更新操作,不是每一次都直接插入到索引页中,而是先插入到内存中。具体做法是:如果该索引页在缓冲池中,直接插入;否则,先将其放入插入缓冲区中,再以一定的频率和索引页合并,这时,就可以将同一个索引页中的多个插入合并到一个IO操作中,大大提高写性能(一定是非聚集索引)。
缺点:可能导致数据库宕机后实例恢复时间变长,占用太多缓冲池内存。
特性3
双写
当MySQL将脏数据flush到data file的时候, 先使用memcopy 将脏数据复制到内存中的double write buffer ,通过double write buffer再分2次,每次写入1MB到共享表空间,然后马上调用fsync函数,同步到磁盘上,避免缓冲带来的问题(前俩个是提升性能,双写主要保证数据页的可用性)。
InnoDB存储引擎内存结构图如下:
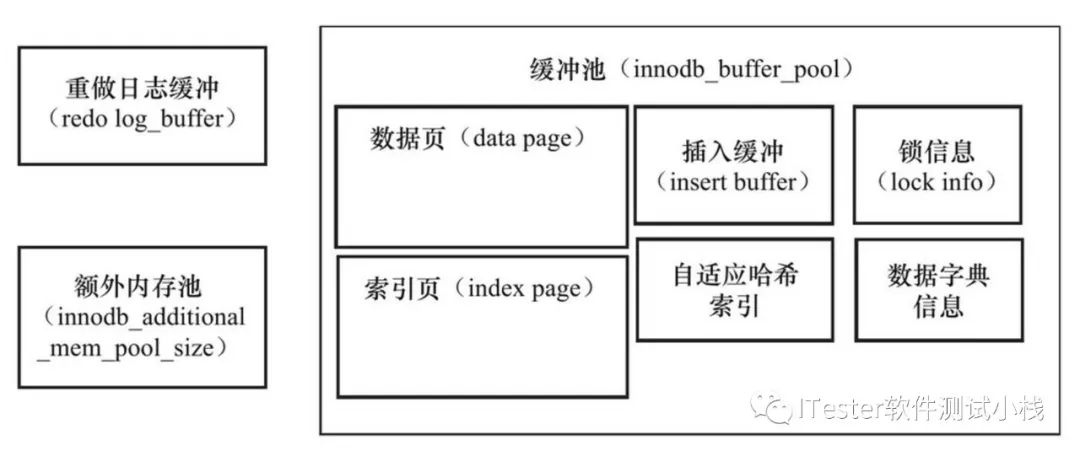
今日问题:
你知道MySQL索引的用途,以及主键索引与二级索引的区别是什么吗?
(欢迎在下方留言区发表你的看法)
以上
That‘s all
更多系列文章
敬请期待
ITester软件测试小栈
往期内容宠幸

想获取更多最新干货内容
快来星标 置顶 关注我
每周一、三、五 08:30见
后台
回复"微信群"一起打怪升级
个人微信:Cc2015123
添加请注明来意 :)
真爱三连,BiuBiuBiu~
