
Hive SQL经典优化案例
点击上方“数据管道”,选择“置顶星标”公众号
干货福利,第一时间送达

1.1 将要执行的查询(执行了 1个多小时才出结果):
SELECT dt as DATA_DATE,STRATEGY,AB_GROUP,SOURCE,count(distinct case when lower(event) not like '%push%' and event!='corner_mark_show' then udid else null end) as DAU,count(case when event='client_show' then 1 else null end) as TOTAL_VSHOW,count(distinct case when event='client_show' then vid else null end) as TOTAL_VIDEO_VSHOW,count(case when event='video_play' then 1 else null end) as TOTAL_VV_VP,count(distinct case when event='video_play' then udid else null end) as TOTAL_USERS_VP,count(case when event='effective_play' then 1 else null end) as TOTAL_VV_EP,count(distinct case when event='effective_play' then udid else null end) as TOTAL_USERS_EP,sum(case when event='video_over' then duration else 0 end) as TOTAL_DURATION,count(case when event='video_over' then 1 else null end) as TOTAL_VOVER,sum(case when event='video_over' then play_cnts else 0 end) as TOTAL_VOVER_PCNTS,count(case when event='push_video_clk' then 1 else null end) as TOTAL_PUSH_VC,count(distinct case when event='app_start' and body_source = 'push' then udid else null end) as TOTAL_PUSH_START,count(case when event='post_comment' then 1 else null end) as TOTAL_REPLY,count(distinct case when event='post_comment' then udid else null end) as TOTAL_USERS_REPLYFROM dwb_v8sp_tmp.base_report_bystrategy_byab_source_column_zklgroup by dt,strategy,ab_group,source;
1.2 查询语句涉及到的表有 7.7亿+ 数据。(查询如下)
jdbc:hive2://ks-hdp-master-01.dns.rightpad (default)> select count(*) from dwb_v8sp_tmp.base_report_bystrategy_byab_source_column_zkl;
1.3 优化思路:既然将要执行的查询是按照 dt, strategy, ab_group, source 这4个字段分组, 那么在建表的时候,就按这四个字段中的N个(1 或 2 或 3 或4)个字段组合分区,直接让 count(distinct xx) 之类的查询定位到“更少的数据子集”,其执行效率就应该更高了(不需要每个子任务均从 7.7亿+ 的数据中(去重)统计)。
1.4 先看每个字段将会有多少分区(因为 Hive 表分区也不宜过多,一般一个查询语句涉及到的 hive分区 应该控制在2K内)
jdbc:hive2://ks-hdp-master-01.dns.rightpad (default)>select count(distinct dt) as dis_dt, count(distinct strategy) as dis_strategy,count(distinct ab_group) as dis_ab_group,count(distinct source) as dis_sourcefrom dwb_v8sp_tmp.base_report_bystrategy_byab_source_column_zkl;

[hue@ks-hdp-client-v02 10:55:08 /usr/local/hue]$ pythonPython 2.7.12 (default, Dec 4 2017, 14:50:18)[GCC 5.4.0 20160609] on linux2Type "help", "copyright", "credits" or "license" for more information.> 2*14*722016-- 2016 个分区还可以接受。
1.5 根据原表,新建分区表,并将原表数据插入新表:
show create table dwb_v8sp_tmp.base_report_bystrategy_byab_source_column_zkl;jdbc:hive2://ks-hdp-master-01.dns.rightpad (default)> show create table dwb_v8sp_tmp.base_report_bystrategy_byab_source_column_zkl;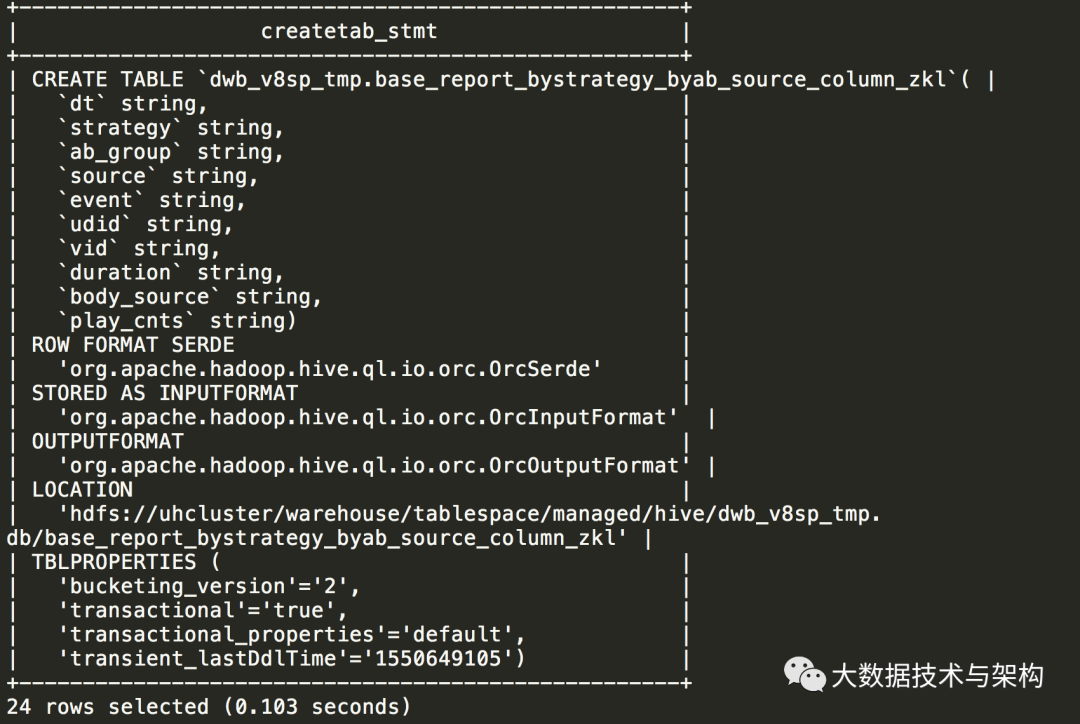
创建新表:按 dt,source,stragegy,ab_group 分区(注意先后顺序,一般习惯分区数越少的越靠前,根据1.5的查询可知:dt=1,source=2,strategy=14,ab_group=72)
create external table `dwb_v8sp_tmp.base_report_bystrategy_byab_source_column_lym`(event string,udid string,vid string,duration string,body_source string,play_cnts string)PARTITIONED BY (dt string,source string,strategy string,ab_group string);
将原表数据插入新表:
insert into `dwb_v8sp_tmp.base_report_bystrategy_byab_source_column_lym` partition(dt,source,strategy,ab_group)select event,udid,vid,duration,body_source,play_cnts,dt,source,strategy,ab_groupfrom `dwb_v8sp_tmp.base_report_bystrategy_byab_source_column_zkl`;
核对两表的数据是否一致:
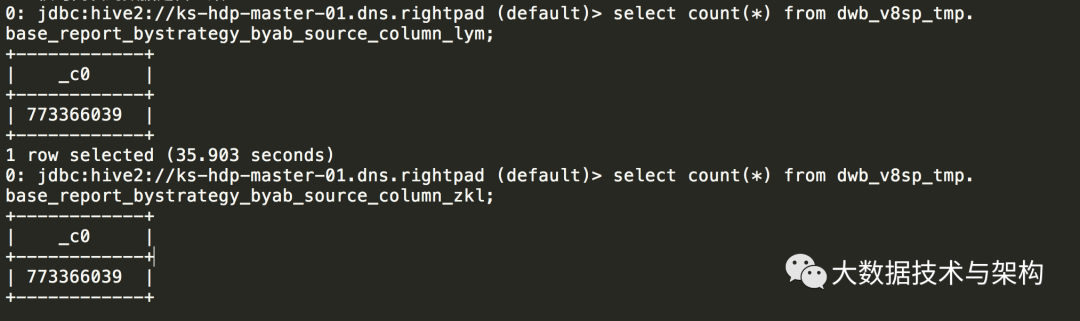
1.6 基于新表执行查询(执行5分钟出结果):

HiveSQL经典优化案例二:
问题描述:一个复杂的SQL,查询执行一段时间后报错:基本上是查不出来;
分析函数对于大表来说不是 hive的强项,这个时候我们将其分解成很多子集,并且合理利用 hive 分区表的优势,然后去 join 。
2.1 将要执行的查询
create table bi_tmp.aloha_UserLoyalty_190301_190303 asselect aid, imei, idfa, udid, event, duration, dt, time_local, hour, source,first_value(time_local) over(partition by udid, event order by time_local) as first_time,last_value(time_local) over(partition by udid, event order by time_local) as last_time,count(time_local) over(partition by udid, event, dt) as event_count_per_day,sum(duration) over(partition by udid, event, dt) as event_duration_each_dayfrom dwb_v8sp.event_column_info_new_hourwhere event in ('app_start', 'app_exit', 'effective_play', 'share_succ', 'like', 'unlike', 'like_comment', 'unlike_comment','comment_success')and dt >= '2019-03-01' and dt <= '2019-03-03';select count(*)from dwb_v8sp.event_column_info_new_hourwhere event in ('app_start', 'app_exit', 'effective_play', 'share_succ', 'like', 'unlike', 'like_comment', 'unlike_comment', 'comment_success')and dt >= '2019-03-01' and dt <= '2019-03-03';
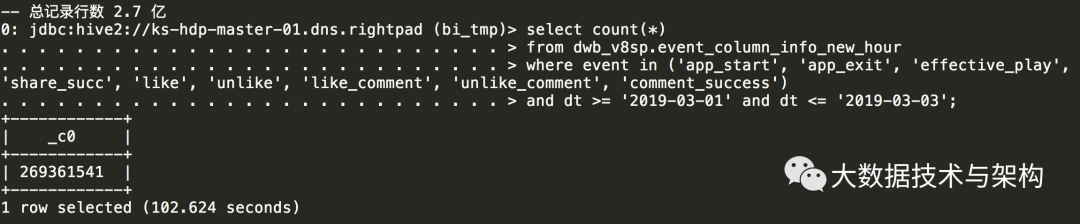
select count(distinct event) as dis_eventfrom dwb_v8sp.event_column_info_new_hourwhere event in ('app_start', 'app_exit', 'effective_play', 'share_succ', 'like', 'unlike', 'like_comment', 'unlike_comment', 'comment_success')and dt >= '2019-03-01' and dt <= '2019-03-03';
分解成三个子集,并保存到三张表: bi_tmp.zyt1, bi_tmp.zyt2, bi_tmp.zyt3
-- drop table if exists bi_tmp.zyt1;create table bi_tmp.zyt1 partitioned by(event)asselect udid,min(time_local) as first_time,max(time_local) as last_time,eventfrom dwb_v8sp.event_column_info_new_hourwhere event in ('app_start', 'app_exit', 'effective_play', 'share_succ', 'like', 'unlike', 'like_comment', 'unlike_comment', 'comment_success')and dt >= '2019-03-01' and dt <= '2019-03-03'group by udid, event;-- drop table if exists bi_tmp.zyt2 purge;create table bi_tmp.zyt2 partitioned by(dt,event)asselect udid,count(time_local) as event_count_per_day,sum(duration) as event_duration_each_day,dt,eventfrom dwb_v8sp.event_column_info_new_hourwhere event in ('app_start', 'app_exit', 'effective_play', 'share_succ', 'like', 'unlike', 'like_comment', 'unlike_comment', 'comment_success')and dt >= '2019-03-01' and dt <= '2019-03-03'group by udid, dt, event;create table bi_tmp.zyt3 partitioned by(dt,event)as select aid, imei, idfa, udid, duration, time_local, hour, source, dt, eventfrom dwb_v8sp.event_column_info_new_hour t3where event in ('app_start', 'app_exit', 'effective_play', 'share_succ', 'like', 'unlike', 'like_comment', 'unlike_comment','comment_success')and dt >= '2019-03-01' and dt <= '2019-03-03';-- 插入目标表:create table bi_tmp.aloha_UserLoyalty_190301_190303 asselect t3.aid, t3.imei, t3.idfa, t3.udid, t3.event, t3.duration, t3.dt, t3.time_local, t3.hour, t3.source,t1.first_time,t1.last_time,t2.event_count_per_day,t2.event_duration_each_dayfrom bi_tmp.zyt1 t1 join bi_tmp.zyt2 t2 on t1.event=t2.event and t1.udid=t2.udidjoin bi_tmp.zyt3 t3 on t2.dt=t3.dt and t2.event= t3.event and t2.udid=t3.udid;-- 验证数据:(与上面的查询记录行数对的上)

HiveSQL经典优化案例三:
如下SQL,用到了 PERCENTILE_APPROX 函数,问题描述:如下SQL,用到了 PERCENTILE_APPROX 函数,个人初步分析认为:由于用到该函数的次数太多,导致性能严重下降。
我仔细查了一下该函数,发现:它是支持“数组传参”的,那么就不难找到优化该SQL的方法了。
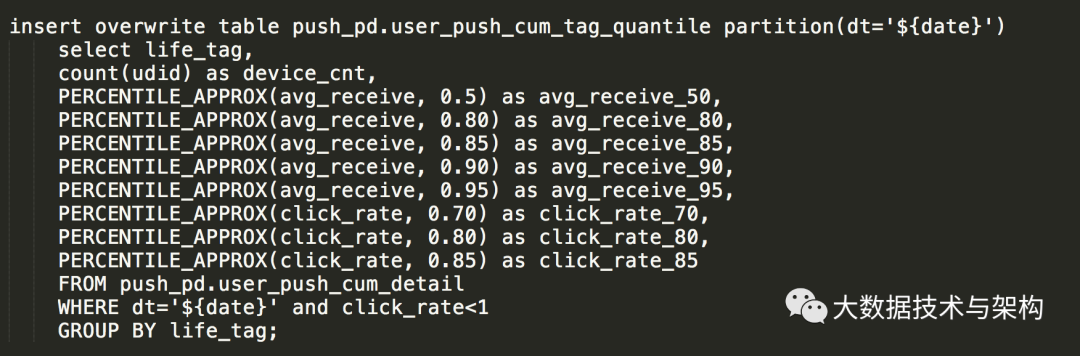
3.1 原SQL性能测试:
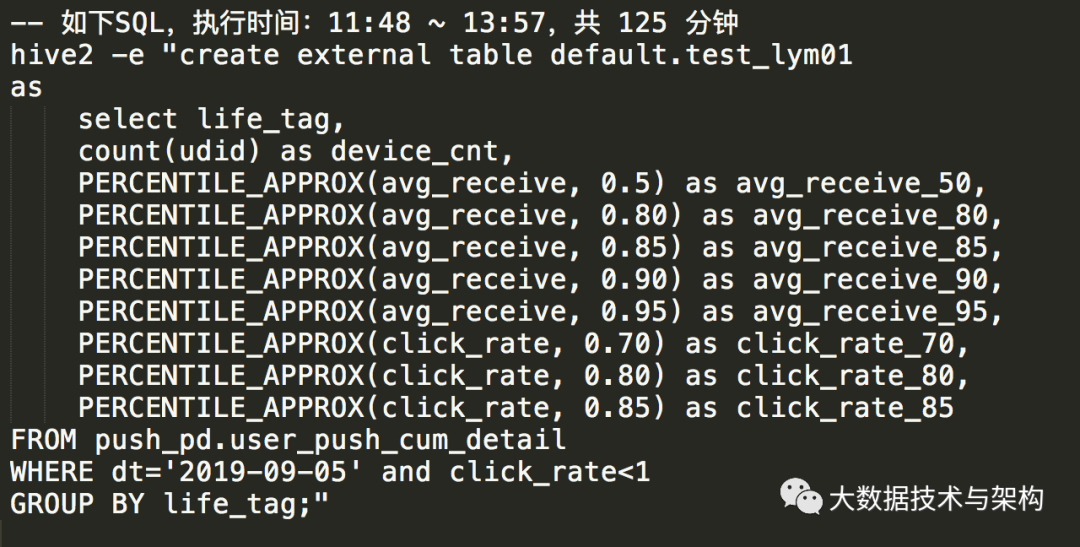
3.2 优化后的SQL,性能测试:

优化后的SQL,性能提升了4倍多。



版权声明: