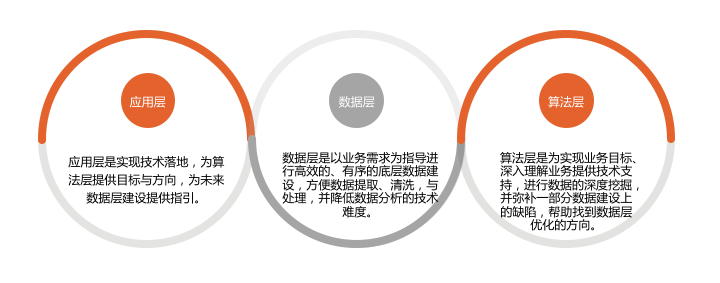
导读:一个成功的数据产品有三个核心层,包含一个中心(应用层)与两个基本点(数据层和算法层)。其中应用层最重要,就是说给谁创造价值,也可以叫业务目标。判断一个数据产品的好坏在于它有没有真正给受众创造价值,创造多大价值。
比如说,“5G红外成像测温”作为一个数据产品已逐步在全国各类重要区域投入使用。应用层是要做到在公共场所中(像飞机场,或火车站),如何无感、无接触、且快速精准的识别高温人员,这个业务目标对2020年的新冠防疫有非常大的价值。为了达到该业务目标,在数据层,我们很容易收集到大量有很高准确度的训练数据集。具体地说,通过挑选固定人群出现在各种公共场所中,并同时采他们的红外热成像数据和体温的信息。在算法层,基于前面大量的训练数据集,我们用人脸识别技术与红外热成像等相关的算法技术(像神经网络)来训练统计模型来精准地预测人体的体温,但是人与成像仪器的距离对预测的准确性会有很大的影响。如同例子所示,三个核心层相辅相成,相互制约,相互作用,缺一不可。具体地说,它们三个关系如下:
- 应用层是实现技术落地,为算法层提供目标与方向,为未来数据层建设提供指引。
- 数据层是以业务需求为指导进行高效的、有序的底层数据建设,方便数据提取、清洗与处理,并降低数据分析的技术难度。
- 算法层是为了实现业务目标,深入理解业务,提供技术支持,进行数据的深度挖掘,并弥补一部分数据建设上的缺陷,帮助找到数据层优化的方向。
应用层也分好几个层级的,核心点就是能够给一部分人群,企业或政府创造出价值,而这些层级主要是要从影响的受众多少和程度来区分,有大有小,我们来看几个例子:
- 可以做几个 R 包,像中山大学王学钦老师的球(Ball)软件包,如果有人用来分析数据,并得到正确结论,就是一种价值。
- 耶鲁大学的张和平老师有关不孕症的结果,能够影响一部分病人的治疗方案。
- 密西根大学的宋学坤老师和合作者解决了活体肾移植领域供受者不匹配的问题,使得肾脏配对的成功率比 Alvin Roth 方法提高了20~30%。
- 可以给政府/公司出一些专题分析,商业智能和报告(像北京大学陈松溪老师有关环境和新冠的报告受到政府机关的重视),给产品进行一些基本的分析,对决策提一些有深度的想法,以提高决策的精准度。
- 做个 app 或电商,像滴滴、京东,和阿里等等,这些平台把供给和需求打通,以增加贸易的效率。
- 像学而思这样的平台,给许多没有进私立学校和重点学校的学生们一个接触顶级教资的机会。
有了一个好的应用层问题,数据层就变得非常关键,就是能不能在一定成本下收集到有用的数据,以达到业务的目标。在现在许多场景中,相关数据产品之所以可以业务落地的一个关键点就是数据层上的突破,即能够相对容易地找到与业务目标相关的数据源和特征。现在各种 app,电商,搜索平台都汇集了许多用户的行为信息,它们是公司优惠策略的金矿,但是这些海量的数据到底能不能发挥应有的效果,主要是三点:- 数据需要服务于应用才有价值。比如说,许多平台收集了大量视频的数据,存储它们花费很大,所以需要删除大量与业务无关的东西,并进行压缩以降低成本。
- 数据收集是有成本的,是否要收集相关数据要看能不能真正为业务创造出价值,我们一定要平衡成本和收益。如果成本远大于的收益的话,我们可能就不需要相关的数据。
- 数据需要能转化为达成业务目标的策略,更直白地说,就是如何把数据转化成业务抓手,以正确地影响业务。
第一个场景是数据对业务价值有很强的确定性,就如“5G红外成像测温”的相关训练数据。我们再考虑另外一个非常有名的 ImageNet (http://image-net.org/),它是计算机视觉领域一个跨时代的数据集,以场景之丰富多样和各种复杂的问题而受到广泛关注,而它的一个关键突破就是最近十几年整个领域在标注能力和效率的提升, 而标注好坏的一个要点就是问题确定性的大小,也就是说能否很确定地找到与业务目标相关的特征。ImageNet 的问题虽然很复杂,但是不确定性是非常小的。用 ImageNet 这种高确定性的数据来打造商业落地的数据产品极度依赖于现在的算力和算法层的突破。第二个场景是数据对业务价值有很强的不确定性,这种不确定性有两个维度:在许多情况,我们根本不知道什么信息是最关键的,像许多疑难杂症,可能是因为“病”的定义本身都不清楚,像精神类的许多疾病,由此许多后续动作的不确定性很大。也可能是因为病理的整个机制都不清楚,我们无从下手。现在许多研究虽然收集了许多数据,其实我们根本不知道这些数据能不能真正可以帮助医生治病救人。许多病理研究都要测不同层级基因的信息,各个政府和机构投入了大量的资源来制造相关的仪器和收集相关数据。为什么? 因为这些仪器并不能满足应用的需求,也不能达到业务的目标=治病救人,所以科学家们还在不断的努力中。另外,因为对个人数据隐私的保护,各个国家开始进行了相关的立法,以规范各个商家,组织,和政府机关对个人数据的使用和管理,所以许多跟业务相关的数据并不能应用在一些策略中。算法层也是我们学术同仁所说的理论研究。统计学和机器学习里面许多有影响力的理论方法都是有很多应用场景和能解决实际问题的理论方法。比如说,抽样方法和实验设计方法(像方开泰老师的均匀设计)都是在收集数据方向,许多同仁在实践中抽象出来的有一定普实性的理论。像 MCMC,线性模型,随机森林,SVM,和神经网络等估计和预测方法都是在实践中得到广泛应用,并创造出相当大的价值。在互联网的领域,最流行的三种学习方法可能是简单的回归模型,随机森林(或 XGBoost),和深度学习。回归模型是研究一些被解释变量关于另一些解释变量的具体函数关系的方法。它通常用于数据建模,预测分析,时间序列模型以及发现变量之间的因果关系,是许多数据建模的第一选择。例如,我们可以用回归模型来研究司机的一些不良的驾驶行为(比如鲁莽驾驶,开车手机等等)与道路交通事故数据之间的关系。随机森林(或 XGBoost),是一个高度灵活和有效的学习方法, 它能够有效地处理大数据,而且它可以进行大量特征进行变量选择,是做回归和分类问题的首选工具之一。随机森林的应用前景非常多,包含客服进线问题的预测,推荐系统,实时分流,用户分层等等。深度学习是处理有时/空相关性数据的重要学习方法,特别是在图像识别、语音识别、和自然语言理解这三个领域都有非常不错的表现,可以说是这三个领域的首选模型。跟传统统计方法相比,深度学习能放大局部一些弱的信号,并把这些放大的信号拉齐到同一个位置。它最大的优点就是使得特征提取和特征选择自动化,学习到的特征对原始数据有更本质的刻画,可能更利于进行统计分类和推断,上海 ImageNet 的数据就引起了深度学习的发展和突破。我们最近一直在做网约车运营相关的策略和研究。通过这段时间的理解,我们越来越感觉实验设计,因果推断,和强化学习这三个方向起着关键的作用。因为篇幅的缘故,我们这里只稍微阐述一下它们的重要性。实验设计和因果推断可以说是医疗行业,工业应用,和互联网公司中被最广泛使用的统计方法。在大部分的应用场景中,我们关心的是业务中的因果关系,就是通过找到并改变一些抓手变量,来达到预期的业务目标,并考虑环境变量的影响。为了对因果关系进行推断,我们有的时候可以用观察的数据,但是这个需要一些强的假设条件。随机实验就依赖于实验设计,本质上就是一个设计一种实验方法收集一些有用且有效的数据,可以更科学的看清楚策略的实际效果,以进行因果推断。强化学习开始在应用中起着越来越重要的作用,主要是因为它的一个主要目的是找到达到最优的中长期奖励的策略。最近它在围棋和电子游戏中达到或超过了人类水平, 而且在精准医疗上也有很多的应用。随着大数据技术和科技的发展,因为我们收集的数据在时间上越来越精细,所以有可能设计一些动态的策略来达到业务的目标。
比如说,网约车平台汇集了大量车的时空轨迹和用户的行为轨迹,而平台策略主要影响用户的行为和供需匹配的效率。我们可以考虑一些策略来影响用户的短期行为,也可以考虑一些中长期的策略(像定价)。我们最近一直在用强化学习来做优化平台各种平台策略,具体的强化学习学习过程包含 (i) 输入是每个用户的历史轨迹,包括订单行为,呼叫记录和领劵行为等;(ii) 模型产出每个乘客/司机在不同 action 下的长期收益。
算法层是连接数据层和应用层的桥梁。不同业务目标对数据和算法的要求不一样。越是重要的决策和洞察越需要与业务紧密相关的数据(深度特征),以及更高深的算法,像因果推断。比如说,大部分公司希望对用户行为的进行一定的引导,特别是深层次和长期的目标,数据的不确定性就会越高,由此处理这些数据需要很强的算法和数学推导能力,像强化学习。此外,算法层也可以弥补一部分数据建设上的缺陷,就是用高深的算法来进行数据挖掘,这可以帮助我们找到未来数据层建设的方向, 这是为什么数据挖掘重要的根本原因。- 生存型:对于业务来说,我愿意为你买单,就是因为我离不开你,没有你就没有办法活,这个最重要。
- 服务型:有没有你,我的服务水平有很大的差异,这就是服务型。
- 品质型:有了你,我们的服务显得高大上,这个是品质型。
每一类数据产品的受众人群的大小和背景不一样。一个高水平的数据建设就是以应用层为引导,打造出最经济实惠的数据框架,并根据用户来定制对应的数据产品,而每个数据产品都是应用层,数据层和算法层三者的有机融合。
本文作者
▬