
Python 分析邓紫棋微博粉丝分布实战教程
客官,想看看邓紫棋微博粉丝分布吗?跟我一起逛一逛吧。
本文主要有三个地方需要逛一逛:python爬虫,数据可视化,数据分析。
一、微博爬虫类型介绍
微博有关的爬虫,由于根据网址的不同,可分为三种类型:
1.移动端爬取:利用selenium去模拟登录然后再去爬取,比较麻烦,但是可以根据个人需求依据关键词进行指定爬取。
2.手机端爬取:网址为手机端微博网址,这在我之前的博客中也有提及微博超话内容爬取,在此不再赘述。无需登录,利用Chrome进行抓包即可实现,而且较selenium来说,性能也是更高一点。(不过要注意设置随机睡眠时间)
3.旧版网址爬取:这是微博最简化版本的网址weibo.cn(感觉回到了诺基亚的年代),界面简单无需抓包,直接利用正则或者xpath等方式提取即可(需要拿到登录后的cookie值)
建议:如果只是爬取指定用户的评论、基本信息这些,后两种方法就够用了;如果涉及到更复杂的需求时再考虑selenium爬取
二、明星粉丝信息爬虫
旧版的网址,粉丝数量只显示了前20页,一页10个,总共才200个。手机端下的粉丝列表总共也只能显示5000个,对于5000个之后的粉丝信息,微博出于隐私保护,是爬取不了。详细的情况可参考新浪微博如何获取用户全部粉丝列表
1.微博用户URL说明:旧版网址用户首页的URL为:http://weibo.cn/u/用户ID手机端用户首页的URL为:https://m.weibo.cn/u/用户ID以邓紫棋为例,她的ID为1705586121,首页如下:
她的粉丝信息抓包结果如下: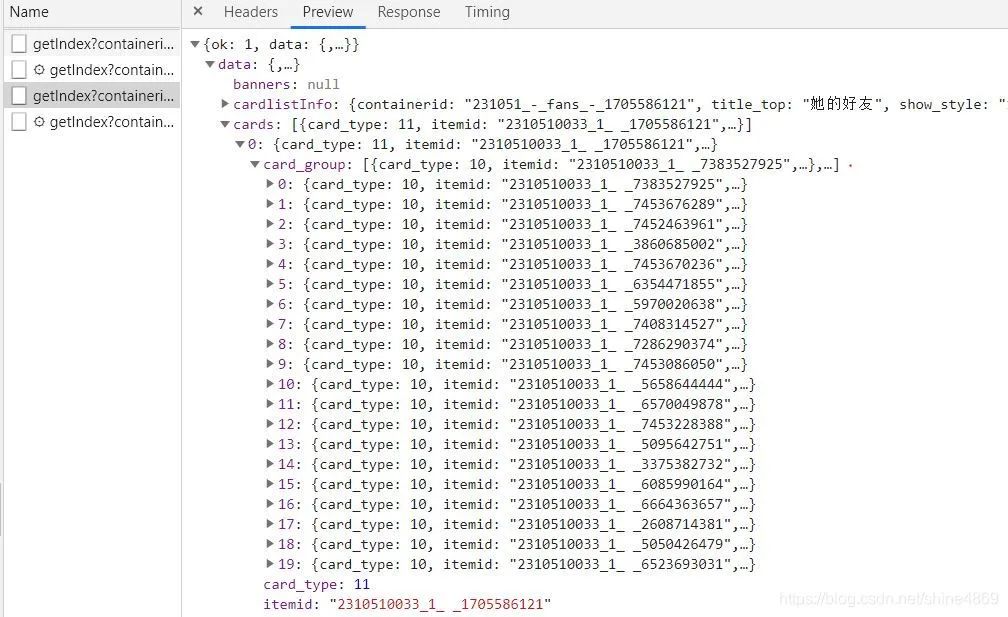
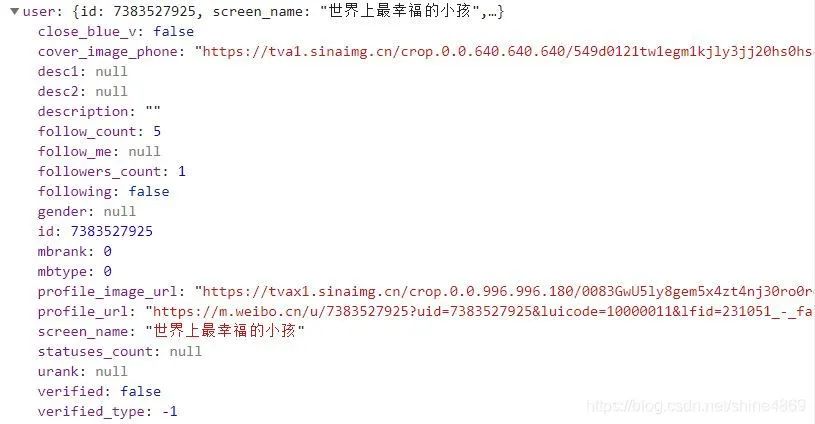 这里的用户信息只有用户的简介(screen_name)、关注数(follow_count)、粉丝数(follow_count),对应用户性别和地区是没有显示的。
这里的用户信息只有用户的简介(screen_name)、关注数(follow_count)、粉丝数(follow_count),对应用户性别和地区是没有显示的。
所以,考虑先用手机端爬取用户ID,再用旧版网址登录,提取信息。(旧版网址个人信息更全一些)
2.爬取邓紫棋粉丝所有的user_id考虑到部分用户可能是机器人,初步筛选条件为粉丝数大于等于20
import requests
import json
import random
import os
os.chdir('C:/Users/dell/Desktop')
import time
base_url='https://m.weibo.cn/api/container/getIndex?containerid=231051_-_fans_-_1705586121&since_id='
head=[
"Opera/12.0(Windows NT 5.2;U;en)Presto/22.9.168 Version/12.00",
"Opera/12.0(Windows NT 5.1;U;en)Presto/22.9.168 Version/12.00",
"Mozilla/5.0 (Windows NT 5.1) Gecko/20100101 Firefox/14.0 Opera/12.0",
"Opera/9.80 (Windows NT 6.1; WOW64; U; pt) Presto/2.10.229 Version/11.62",
"Opera/9.80 (Windows NT 6.0; U; pl) Presto/2.10.229 Version/11.62",
]
header={
'user-agent':random.choice(head)
}
with open('user_id.txt','w') as f:
for page in range(2,251): #注意是从2开始才是用户信息
try:
url=base_url+str(page)
r=requests.get(url,headers=header)
data=json.loads(r.text)
all_user=data['data']['cards'][0]['card_group']
for user in all_user:
fans=int(user.get('desc2').split(':')[1])
if fans >=20:
f.write(str(user.get('user')['id'])+'\n')
print('第{}页用户id爬取完毕'.format(page))
time.sleep(random.randint(1,3))
except:
print('未爬到数据')
爬取的部分用户ID如下:
3.以旧版微博网址,登录后获取cookie,如下图所示: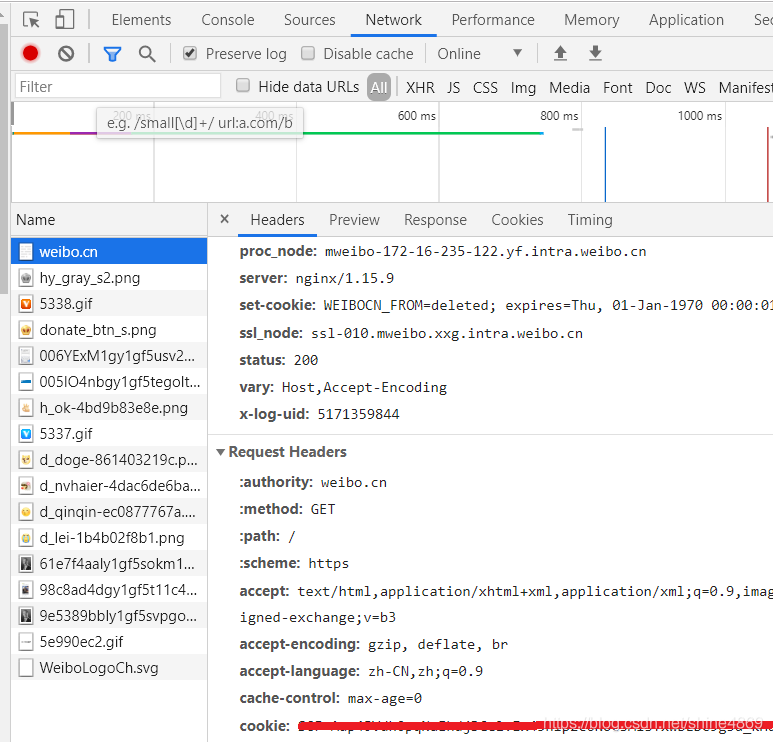 获取后将下述代码中的cookie改为你自己的cookie即可
获取后将下述代码中的cookie改为你自己的cookie即可
import numpy as np
import pandas as pd
import requests
from lxml import etree
import random
import time
header={'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36',
'cookie':'你自己的cookie',
'accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
}
url_new='https://weibo.cn/u/'
data=[]
count=0
def get_id(path):
with open(path,'r') as f:
user_list=f.readlines()
user_id=np.char.rstrip(user_list,'\n')
return user_id
def gethtml(url,header):
r=requests.get(url,headers=header)
if r.status_code==200:
return r.text
else:
print('网络连接异常')
for user_id in get_id('user_id.txt'):
try:
url=url_new+user_id
r_text=gethtml(url,header)
html=etree.HTML(r_text.encode('utf-8'))
user_name=html.xpath('//span[@class="ctt"]/text()')[0]
inf=html.xpath('//span[@class="ctt"]/text()')[1]
weibo_number=html.xpath('//div[@class="tip2"]/span[@class="tc"]/text()')[0].replace('微博','').strip('[]')
focus_number=html.xpath('//div[@class="tip2"]/a[1]/text()')[0].replace('关注','').strip('[]')
fan_number=html.xpath('//div[@class="tip2"]/a[2]/text()')[0].replace('粉丝','').strip('[]')
data.append([user_name,inf,weibo_number,focus_number,fan_number])
count+=1
print('第{}个用户信息写入完毕'.format(count))
time.sleep(random.randint(1,2))
except:
print('用户信息不完全')
df=pd.DataFrame(data,columns=['user_id','inf','weibo_num','focus_num','fans_num'])
df.to_csv('weibo_user.csv',index=False,encoding='gb18030')
最终爬取到粉丝数量大于等于20的用户共10647个(多次爬取的结果),清洗后的部分数据如下: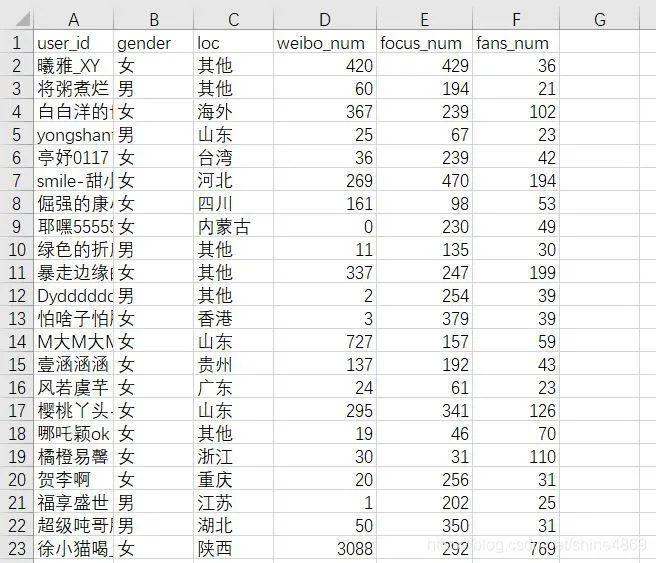
三、可视化
(1) 粉丝性别占比
import matplotlib.pyplot as plt
import pandas as pd
plt.style.use('ggplot')
plt.rcParams['font.sans-serif']=['kaiti']
%config InlineBackend.figure_format='svg'
df=pd.read_csv('weibo_user.csv',encoding='gbk')
gender=pd.DataFrame(df['gender'].value_counts())
plt.pie(gender['gender'],
labels=['女','男'],
startangle=90,
shadow=False,
autopct='%1.1f%%',
textprops={'fontsize': 13, 'color': 'w'},
colors=['#f26d5b','#2EC4B6']
)
plt.legend(loc='best')
plt.title('邓紫棋粉丝性别占比')
plt.axis('equal')
plt.tight_layout()
plt.show()
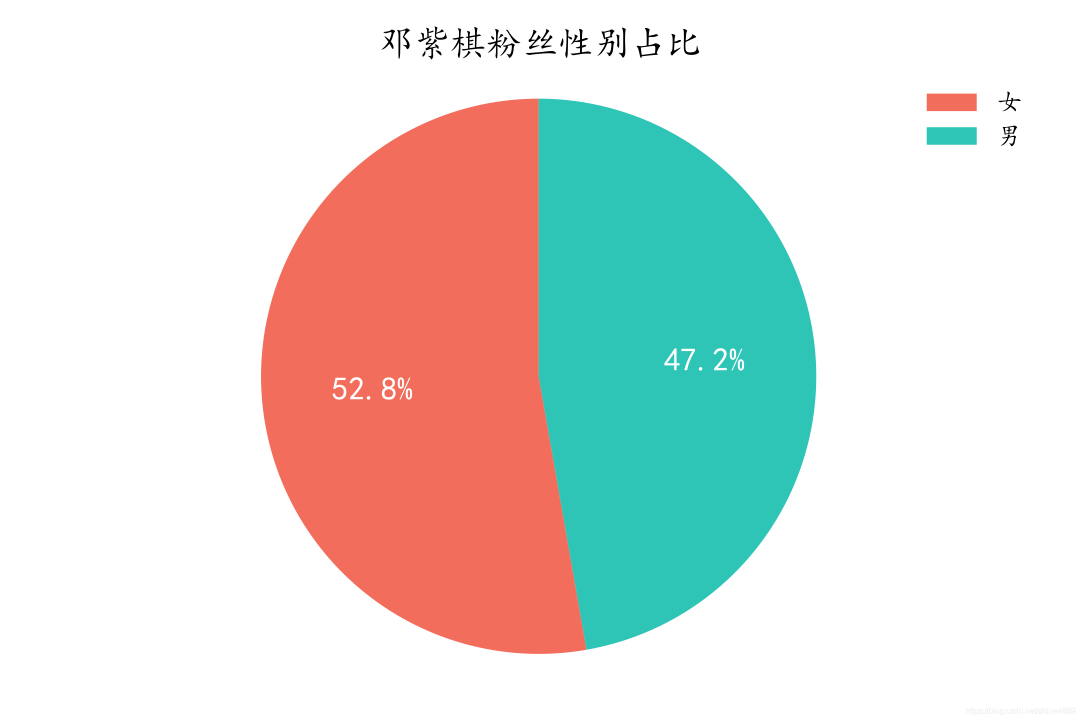
从性别分布来看,女粉较男粉稍多一些
(2) 全国粉丝分布情况注意:使用的是pyecharts最新版本
from pyecharts.charts import Map
from pyecharts import options as opts
import numpy as np
df=df[~df['loc'].isin(['其他'])]
loc=pd.DataFrame(df['loc'].value_counts())
city=np.char.rstrip(list(loc.index))
map1=Map(init_opts=opts.InitOpts(width="1200px",height="800px"))
map1.set_global_opts(
title_opts=opts.TitleOpts(title="邓紫棋粉丝地区分布"),
visualmap_opts=opts.VisualMapOpts(max_=1500, is_piecewise=True, #最大值由max_设置
pieces=[
{"max": 1500, "min": 1000, "label": ">1000", "color": "#754F44"},
{"max": 999, "min": 600, "label": "600-999", "color": "#EC7357"},
{"max": 599, "min": 200, "label": "200-599", "color": "#FDD692"},
{"max": 199, "min": 1, "label": "1-199", "color": "#FBFFB9"},
{"max": 0, "min": 0, "label": "0", "color": "#FFFFFF"},
], )) #最大数据范围,分段
map1.add("",[list(z) for z in zip(city,loc['loc'])],
maptype='china',is_roam=False,
is_map_symbol_show=False)
map1.render('fans_loc.html')
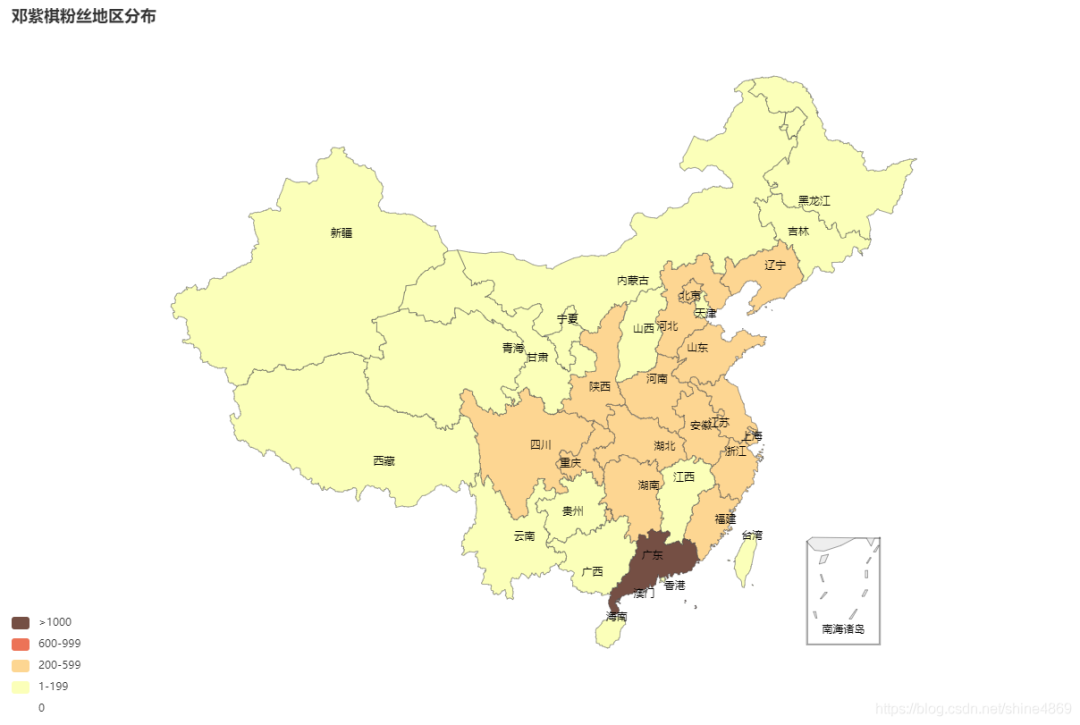
从地区分布来看,广东粉最多(毕竟紫棋是香港歌手嘛),其次四川、湖北、河南、山东、江苏、浙江等省份粉丝也较多,内陆偏远地区粉丝分布较少如新疆、云南、贵州等
(3) 性别与地区交叉分布情况
import seaborn as sns
df_new=df[~df['loc'].isin(['其他'])]
index=df_new.groupby('loc').count().sort_values(by='gender',ascending=False).index
plt.figure(figsize=(15,6))
sns.countplot(data=df_new,x='loc',hue='gender',order=index,palette=['#f26d5b','#2EC4B6'])
plt.xticks(rotation=90)
plt.legend(loc='upper right')
plt.title('邓紫棋男女粉丝全国分布情况')
plt.xlabel('地区')
plt.ylabel('人数')
plt.show()
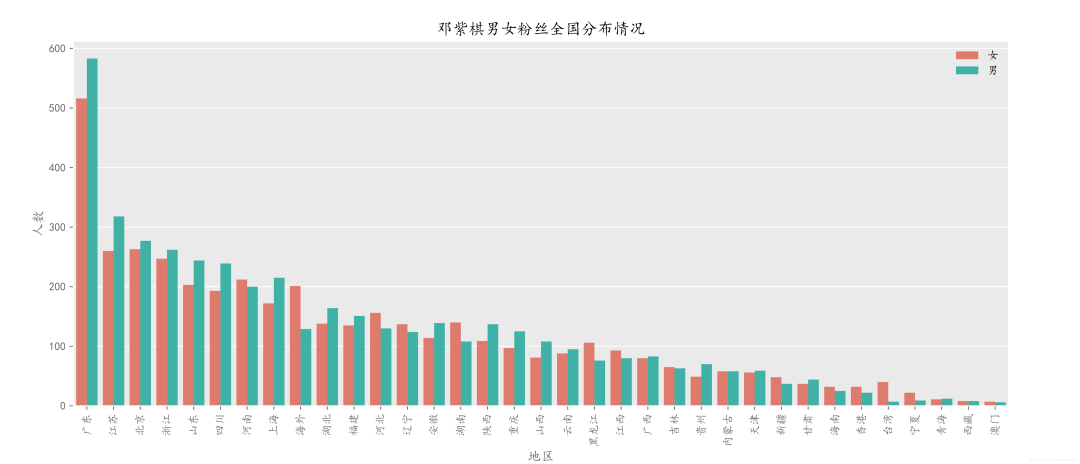
男粉多于女粉的地区有:广东、北京、江苏、四川、上海等
女粉多于男粉的地区有:、河北、海外、辽宁、湖南等
(4) 地区与粉丝类型交叉情况对用户粉丝量以0,100,500,1000,10000,100000为分隔点,划分为五种类型的用户:小透明、常驻博主,资深博主,微博红人,微博大V。并与地区进行交叉作图,如下所示
df=pd.read_csv('weibo_user.csv',encoding='gbk')
label=['小透明','常驻博主','资深博主','微博红人','微博大V']
df['fans_label']=pd.cut(df['fans_num'],bins=[0,100,500,1000,10000,100000],
labels=label)
df_new=df[~df['loc'].isin(['其他'])]
plt.figure(figsize=(15,6))
sns.countplot(x='loc',hue='fans_label',data=df_new,palette=['#754F44','#EC7357','#FDD692',
'#8FBC94','#000000'],order = df_new['loc'].value_counts().index)
plt.legend(loc='upper right',frameon=False)
plt.xticks(rotation=90)
plt.ylabel('人数')
plt.xlabel('地区')
plt.title('不同粉丝类型在全国分布情况')
plt.show()
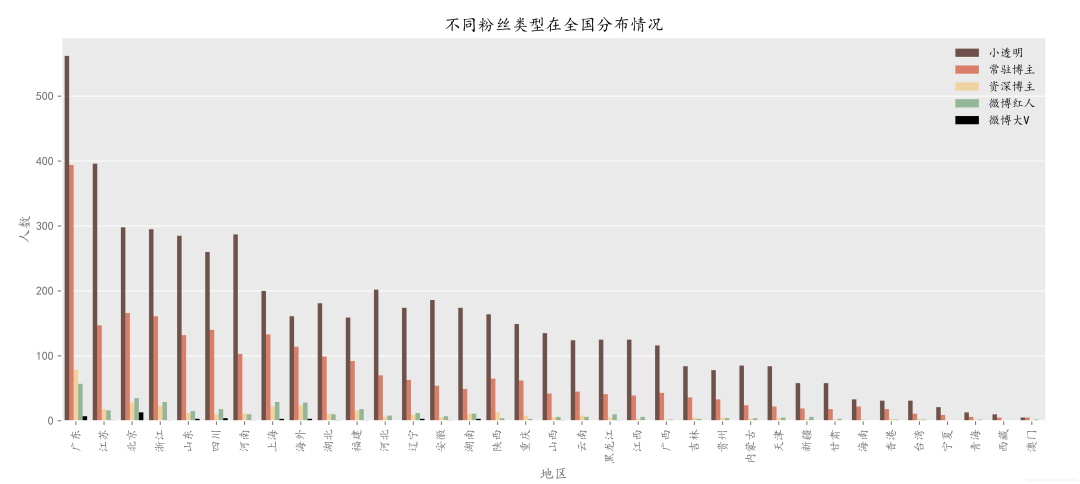
从上图可以得出以下三条结论:1.全国地区大部分用户的粉丝量都是低于100的
2.广东粉不仅多,而且他们的粉丝人数也很多,具体表现为常驻博主、资深博主、微博红人均列全国第一。
3.一千粉至一万粉的用户除广东外,主要分布在海外、浙江、北京、上海等地区。其中,北京一万粉至十万粉(微博大V)的数量位居全国第一。此外,微博大V还分布在广东、海外、四川、上海、湖南
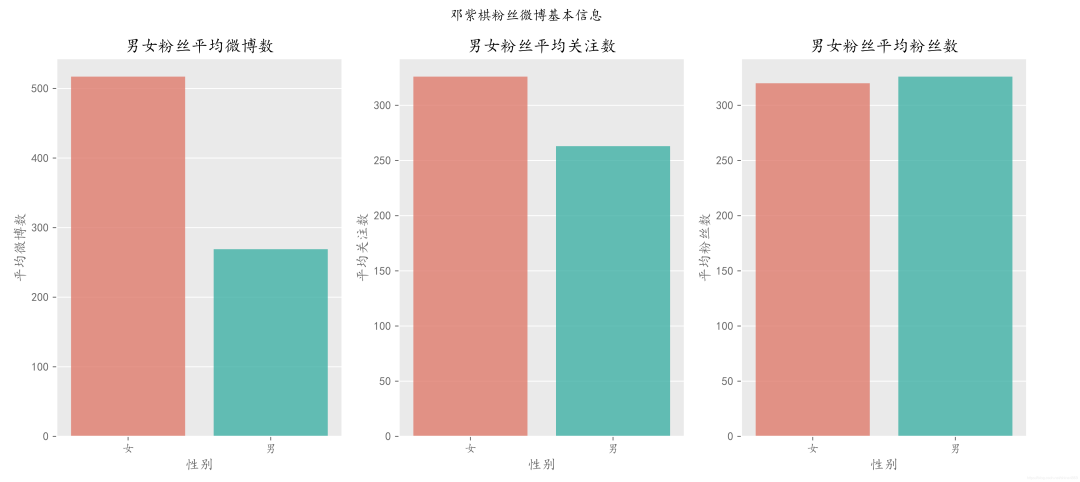
(5) 用户微博数、关注数、粉丝量基本情况
gender_group=df.pivot_table(aggfunc=np.mean,
index=df['gender'],
values=df[['weibo_num','focus_num','fans_num']]).round(0)
f,ax=plt.subplots(1,3,figsize=(15,6))
sns.barplot(x=gender_group.index,y=gender_group['weibo_num'],
palette=['#f26d5b','#2EC4B6'],alpha=0.8,ax=ax[0])
ax[0].set_title('男女粉丝平均微博数')
ax[0].set_xlabel('性别')
ax[0].set_ylabel('平均微博数')
sns.barplot(x=gender_group.index,y=gender_group['focus_num'],
palette=['#f26d5b','#2EC4B6'],alpha=0.8,ax=ax[1])
ax[1].set_title('男女粉丝平均关注数')
ax[1].set_xlabel('性别')
ax[1].set_ylabel('平均关注数')
sns.barplot(x=gender_group.index,y=gender_group['fans_num'],
palette=['#f26d5b','#2EC4B6'],alpha=0.8,ax=ax[2])
ax[2].set_title('男女粉丝平均粉丝数')
ax[2].set_xlabel('性别')
ax[2].set_ylabel('平均粉丝数')
plt.suptitle('邓紫棋粉丝微博基本信息') #子图添加总标题
plt.show()
在这里插入图片描述
从饼图可知,男女粉丝数量相差不大。但平均微博数、关注数都要大于男粉丝,特别是平均微博数大致为男粉丝的两倍,由此可得出结论:相比男粉丝,女粉丝在微博活跃度会更高(原因可能在于女粉经常转发爱豆的动态、为爱豆打榜之类的)
(6) 微博数、关注量、粉丝量相关性
plt.figure(figsize=(10,6))
sns.heatmap(df[['weibo_num','focus_num','fans_num']].corr(),cmap='YlGn',annot=True)
plt.title('微博数、关注数、粉丝数相关热力图')
plt.show()
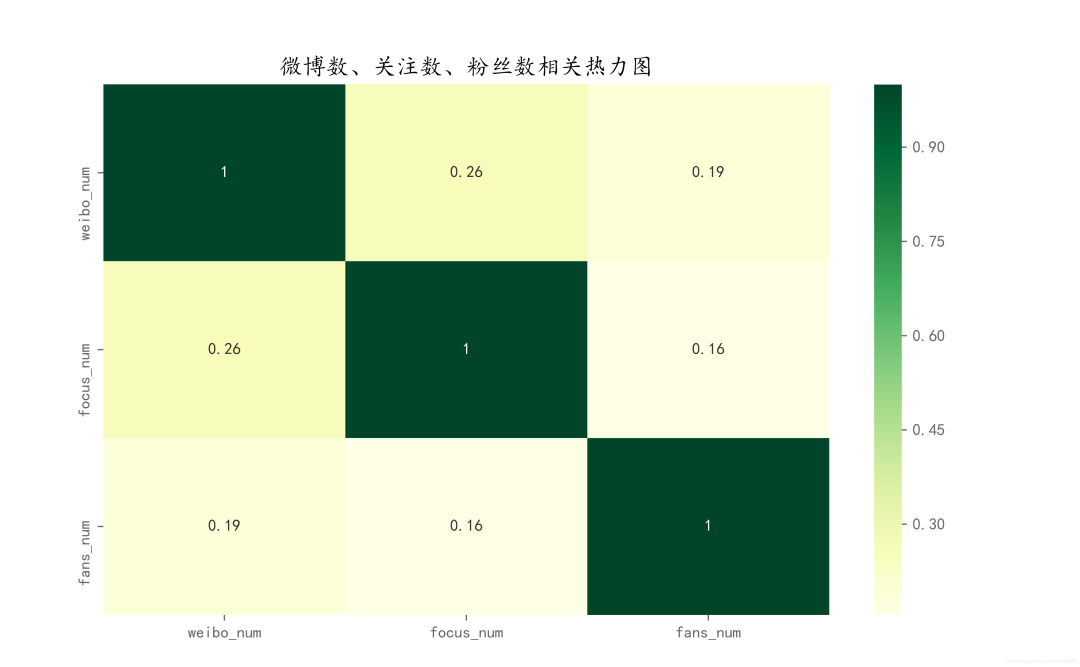
相关系数的范围在-1到1之间。越接近1,正相关性越强,越接近-1,负相关性越强。(当然这里的相关性仅指线性相关性) 从上图来看,基本上三者之间的相关性还是很弱的,也就微博数与关注数相关性相对较高一点,但仅有0.26。
我们的文章到此就结束啦,如果你喜欢今天的Python 实战教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应红字验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
点击下方阅读原文可获得更好的阅读体验
Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典