
【NLP】博士笔记 | 深入理解深度学习语义分割
作者:王博Kings、Sophia
本文内容概述王博Kings最近的语义分割学习笔记总结
引言:最近自动驾驶项目需要学习一些语义分割的内容,所以看了看论文和视频做了一个简单的总结。笔记思路是:机器学习-->>深度学习-->>语义分割
目录:
机器学习回顾
深度学习回顾
语义分割简介
语义分割代表算法
一、回顾机器学习


二、深度学习回顾

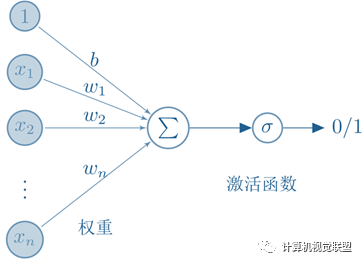
激活函数



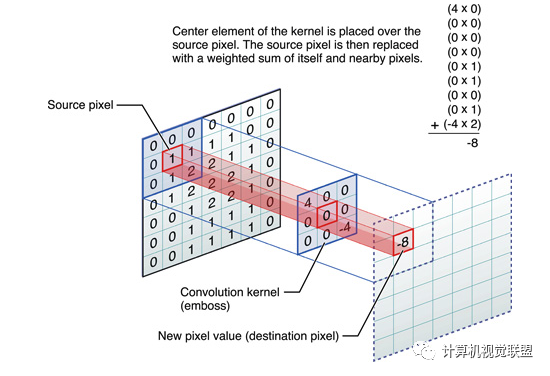
这些卷积是语义分割的一个核心内容!

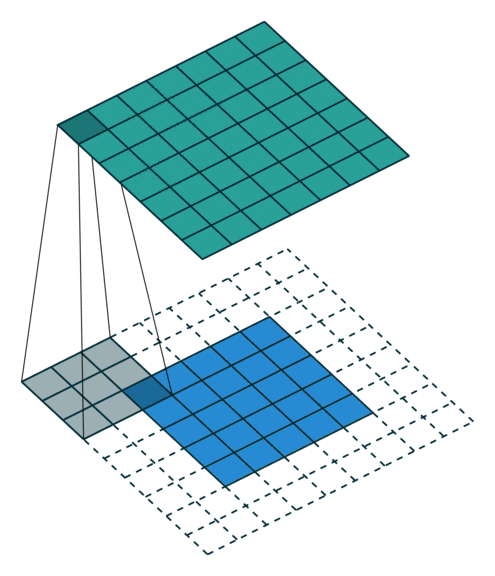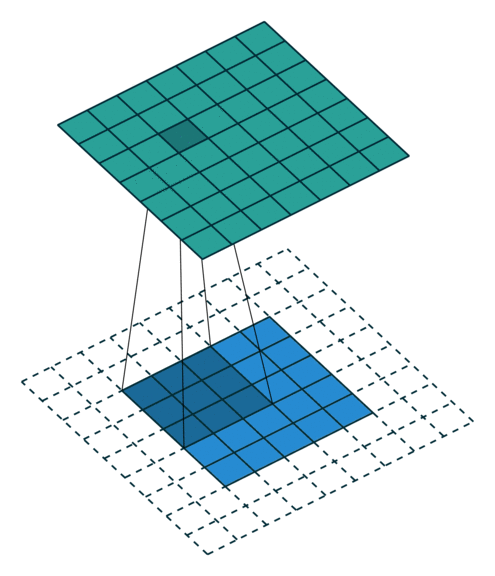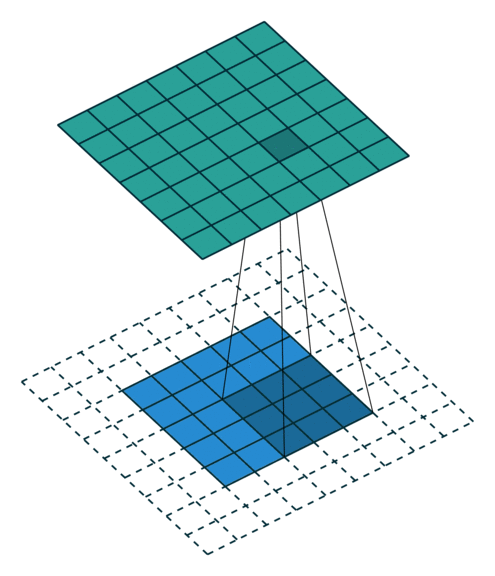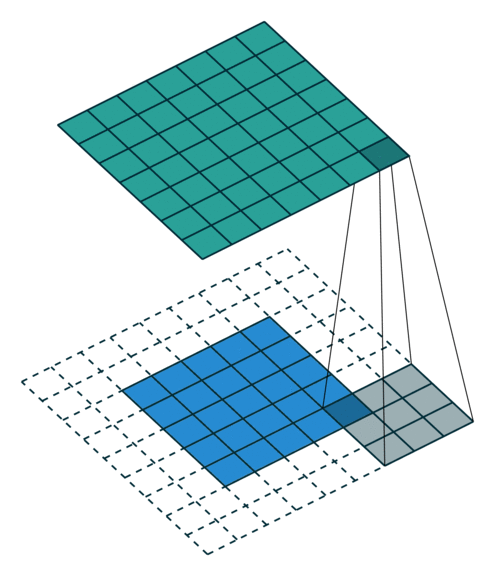
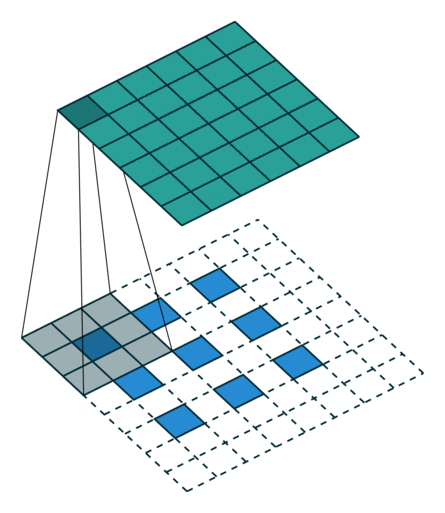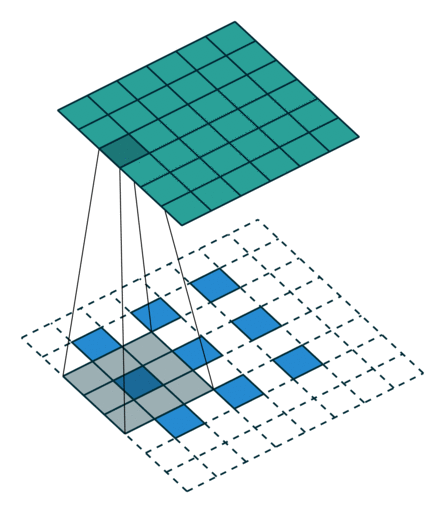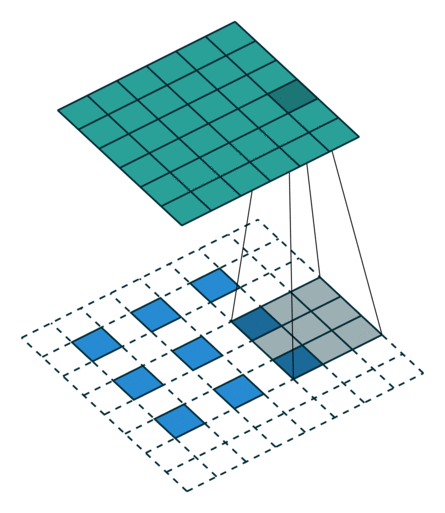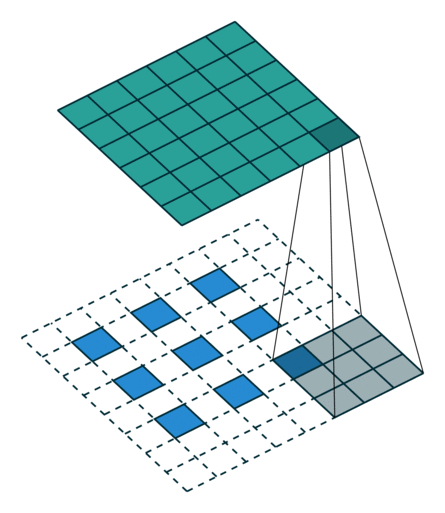
三、语义分割简介
什么是语义分割?
ü语义分割(semantic segmentation):按照“语义”给图像上目标类别的每一个点打一个标签,使得不同种类的东西在图像上区分开,可以理解为像素级别的分类任务。

语义分割有哪些评价指标?
ü1.像素精度(pixel accuracy ):每一类像素正确分类的个数/ 每一类像素的实际个数。
ü2.均像素精度(mean pixel accuracy ):每一类像素的精度的平均值。
ü3.平均交并比(Mean Intersection over Union):求出每一类的IOU取平均值。IOU指的是两块区域相交的部分/两个部分的并集,如figure2中 绿色部分/总面积。
ü4.权频交并比(Frequency Weight Intersectionover Union):每一类出现的频率作为权重
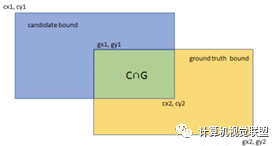
四、语义分割代表算法
全卷积网络 FullyConvolutional Networks
2015年《Fully Convolutional Networks for SemanticSegmentation》
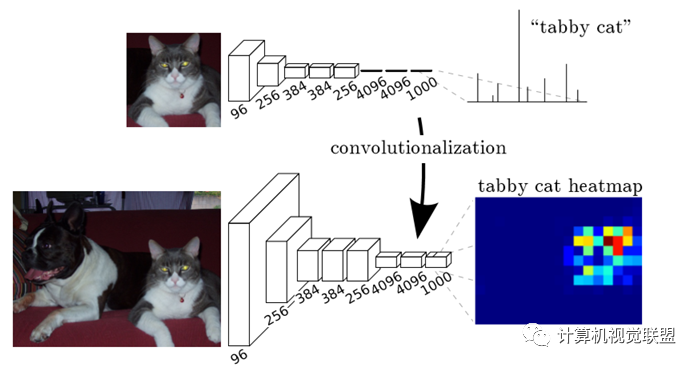
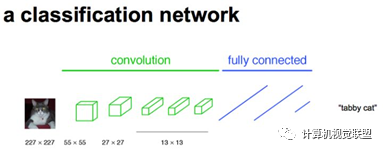
通常CNN网络在卷积层之后会接上若干个全连接层, 将卷积层产生的特征图(feature map)映射成一个固定长度的特征向量。
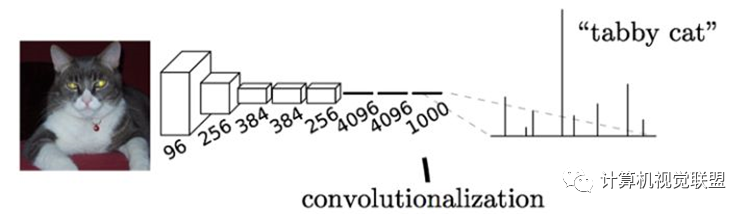
输入AlexNet, 得到一个长为1000的输出向量, 表示输入图像属于每一类的概率, 其中在“tabby cat”这一类统计概率最高。
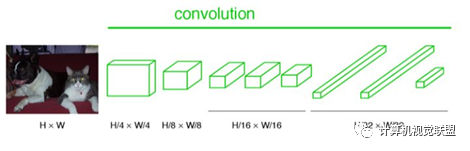
与经典的CNN在卷积层之后使用全连接层得到固定长度的特征向量进行分类(全联接层+softmax输出)不同,FCN可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的feature map进行上采样, 使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 最后在上采样的特征图上进行逐像素分类。
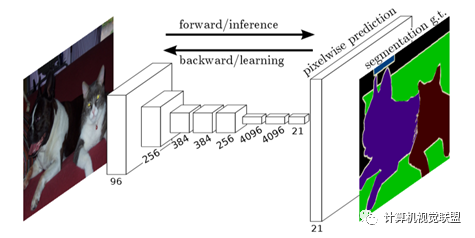
简单的来说,FCN与CNN的区域在把于CNN最后的全连接层换成卷积层,输出的是一张已经Label好的图片。


有没有缺点?
是得到的结果还是不够精细。进行8倍上采样虽然比32倍的效果好了很多,但是上采样的结果还是比较模糊和平滑,对图像中的细节不敏感。
是对各个像素进行分类,没有充分考虑像素与像素之间的关系。忽略了在通常的基于像素分类的分割方法中使用的空间规整(spatialregularization)步骤,缺乏空间一致性。
对于任何的分类神经网络我们都可以用卷积层替换FC层,只是换了一种信息的分布式表示。如果我们直接把Heatmap上采样,就得到FCN-32s。
三种模型FCN-32S,FCN-16S, FCN-8S
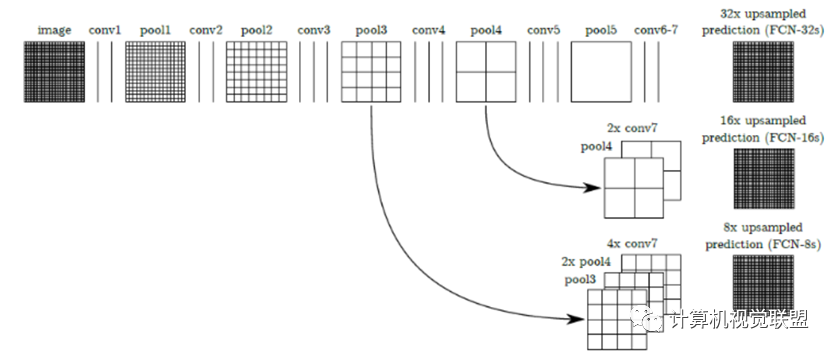
主要贡献:
ü不含全连接层(fc)的全卷积(fully conv)网络。可适应任意尺寸输入。
ü增大数据尺寸的反卷积(deconv)层。能够输出精细的结果。
ü结合不同深度层结果的跳级(skip)结构。同时确保鲁棒性和精确性。
缺点:
Ø得到的结果还是不够精细。进行8倍上采样虽然比32倍的效果好了很多,但是上采样的结果还是比较模糊和平滑,对图像中的细节不敏感。
Ø是对各个像素进行分类,没有充分考虑像素与像素之间的关系。忽略了在通常的基于像素分类的分割方法中使用的空间规整(spatial regularization)步骤,缺乏空间一致性。
SegNet
2015年《SegNet: A DeepConvolutionalEncoder-Decoder Architecture for Image Segmentation》
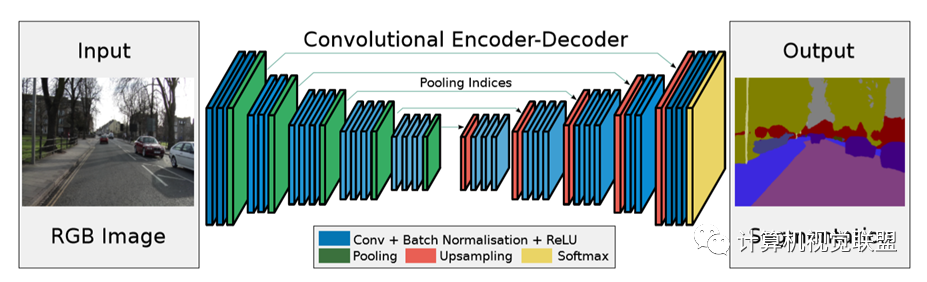
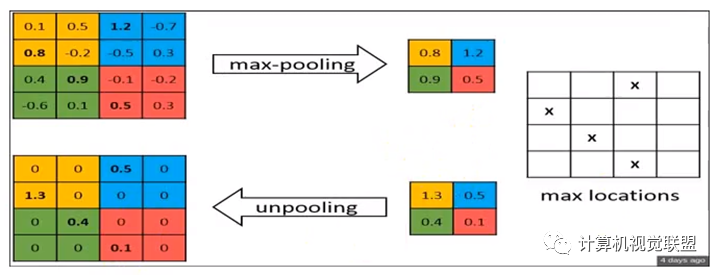
最大池化:反卷积
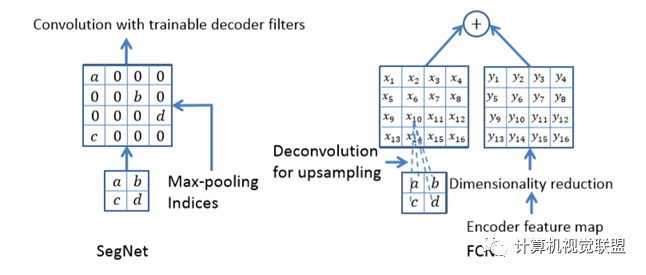
与FCN对比,SegNet的差别就在于上采样反卷积
U-Net
2015年《U-Net:Convolutional Networks for Biomedical ImageSegmentation》
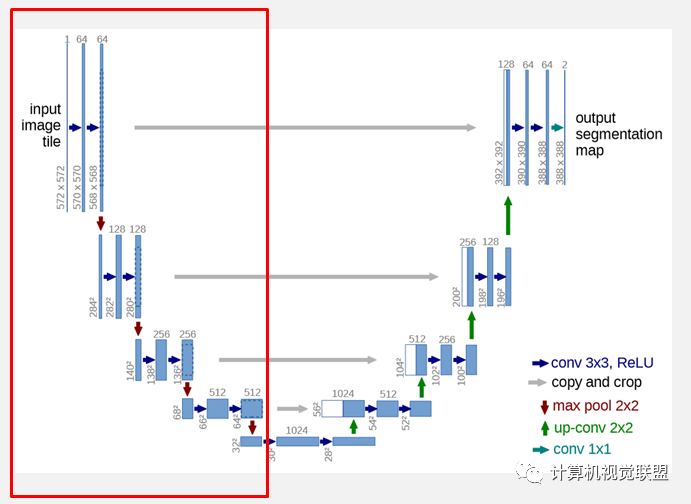
网络的左侧(红色虚线)是由卷积和Max Pooling构成的一系列降采样操作,论文中将这一部分叫做压缩路径(contracting path)。压缩路径由4个block组成,每个block使用了3个有效卷积和1个Max Pooling降采样,每次降采样之后Feature Map的个数乘2,因此有了图中所示的Feature Map尺寸变化。最终得到了尺寸为 的Feature Map。
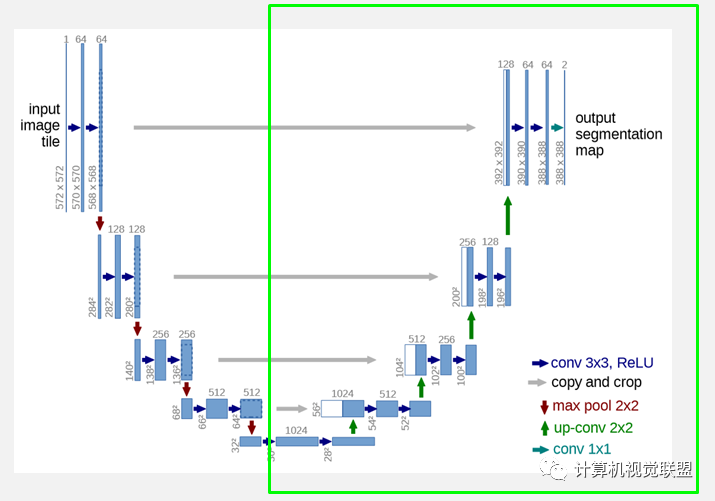
网络的右侧部分(绿色虚线)在论文中叫做扩展路径(expansive path)。同样由4个block组成,每个block开始之前通过反卷积将Feature Map的尺寸乘2,同时将其个数减半(最后一层略有不同),然后和左侧对称的压缩路径的Feature Map合并,由于左侧压缩路径和右侧扩展路径的Feature Map的尺寸不一样,U-Net是通过将压缩路径的Feature Map裁剪到和扩展路径相同尺寸的Feature Map进行归一化的(即图1中左侧虚线部分)。扩展路径的卷积操作依旧使用的是有效卷积操作,最终得到的Feature Map的尺寸是 。由于该任务是一个二分类任务,所以网络有两个输出Feature Map。
U-Net没有利用池化位置索引信息,而是将编码阶段的整个特征图传输到相应的解码器(以牺牲更多内存为代价),并将其连接,再进行上采样(通过反卷积),从而得到解码器特征图。
DeepLabV1
2015年《Semantic image segmentation withdeep convolutional nets and fully connected CRFs》

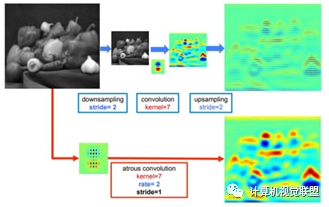

感受野变大
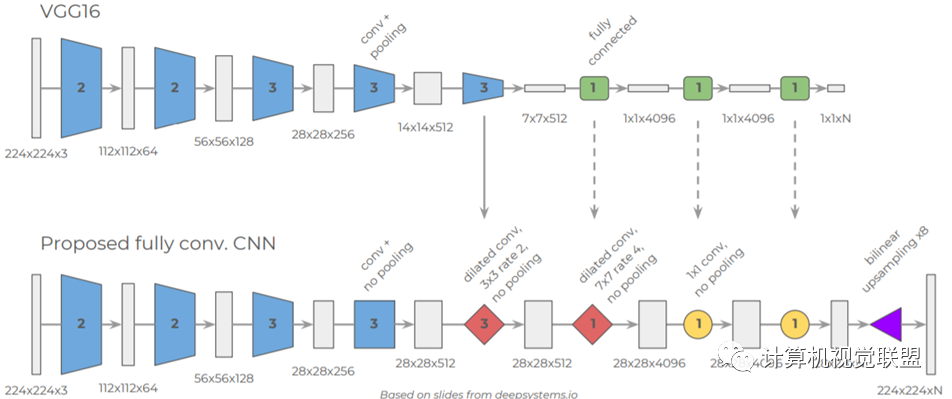
DeepLabV2
2015年《DeepLab-v2: Semantic ImageSegmentation 》

ASPP,空洞卷积池化金字塔;VGG改为ResNet
DeepLabv2是采用全连接的CRF来增强模型捕捉细节的能力。
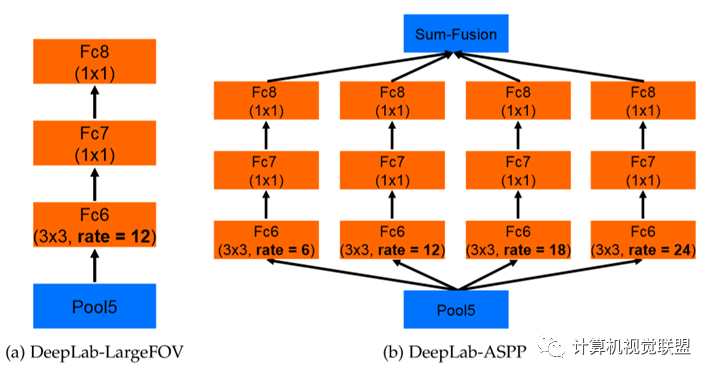
DeepLabv2在最后几个最大池化层中去除了下采样的层,取而代之的是使用空洞卷积
DeepLabV3
2017年《Rethinking Atrous Convolution for Semantic ImageSegmentation》
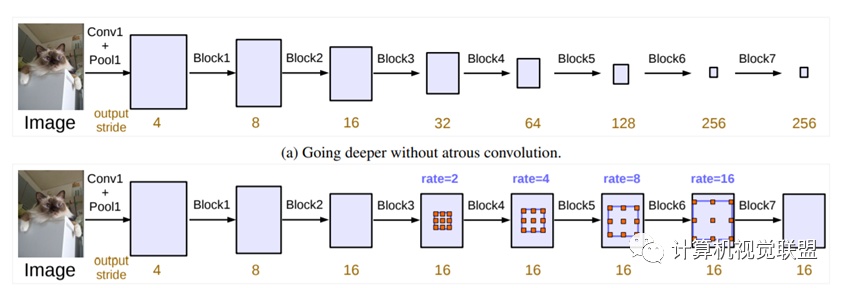

DeepLabV3+
2018年《Encoder-Decoder with Atrous Separable Convolution for SemanticImage Segmentation》
使用了两种类型的神经网络,使用空间金字塔模块和encoder-decoder结构做语义分割。
ü空间金字塔:通过在不同分辨率上以池化操作捕获丰富的上下文信息
üencoder-decoder架构:逐渐的获得清晰的物体边界

Encoder
Encoder就是原来的DeepLabv3,注意点有2点:
输入尺寸与输出尺寸比(outputstride = 16),最后一个stage的膨胀率rate为2
AtrousSpatial Pyramid Pooling module(ASPP)有四个不同的rate,额外一个全局平均池化
Decoder
明显看到先把encoder的结果上采样4倍,然后与resnet中下采样前的Conv2特征concat一起,再进行3x3的卷积,最后上采样4倍得到最终结果
需要注意点:
融合低层次信息前,先进行1x1的卷积,目的是降通道(例如有512个通道,而encoder结果只有256个通道)
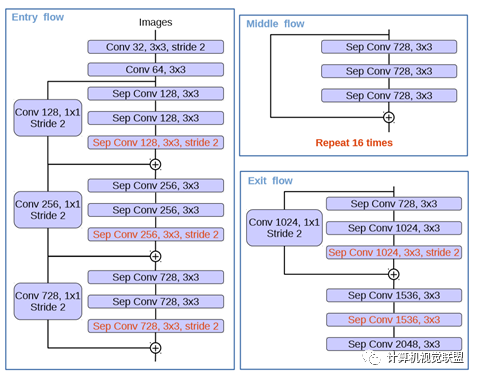
红色部分为修改
(1)更多层:重复8次改为16次(基于MSRA目标检测的工作)。
(2)将原来简单的pool层改成了stride为2的deepwishseperable convolution。
(3)额外的RELU层和归一化操作添加在每个 3 × 3 depthwise convolution之后(原来只在1*1卷积之后)
DeepLabv1:https://arxiv.org/pdf/1412.7062v3.pdf
DeepLabv2:https://arxiv.org/pdf/1606.00915.pdf
DeepLabv3:https://arxiv.org/pdf/1706.05587.pdf
DeepLabv3+:https://arxiv.org/pdf/1802.02611.pdf
代码:https://github.com/tensorflow/models/tree/master/research/deeplab
还有一个Transformer学习笔记总结:
end
往期精彩回顾
获取本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/qFiUFMV
本站qq群704220115。
加入微信群请扫码: