
神经网络拟合能力的提升之路(Pyhton)
本文侧重于模型拟合能力的探讨。过拟合及泛化能力方面下期文章会专题讨论。
原理上讲,神经网络模型的训练过程其实就是拟合一个数据分布(x)可以映射到输出(y)的数学函数 f(x),而拟合效果的好坏取决于数据及模型。那对于如何提升拟合能力呢?我们首先从著名的单层神经网络为啥拟合不了XOR函数说起。
一、单层神经网络的缺陷
单层神经网络如逻辑回归、感知器等模型,本质上都属于广义线性分类器(决策边界为线性)。
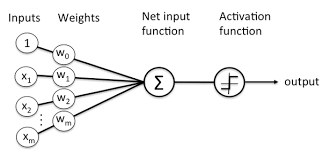
这点可以从逻辑回归模型的决策函数看出,决策函数Y=sigmoid(wx + b),当wx+b>0,Y>0.5;当wx+b<0,Y<0.5,以wx+b这条线可以区分开Y=0或1(如下图),可见决策边界是线性的。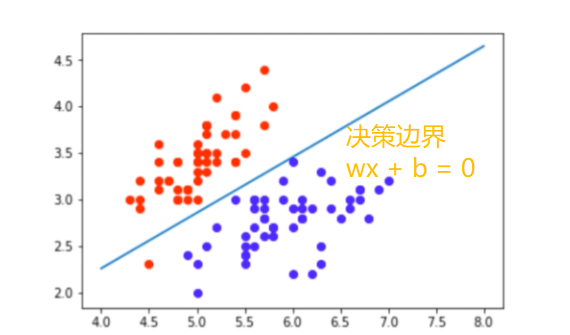
这也导致了历史上著名xor问题:
1969年,“符号主义”代表人物马文·明斯基(Marvin Minsky)提出XOR问题:
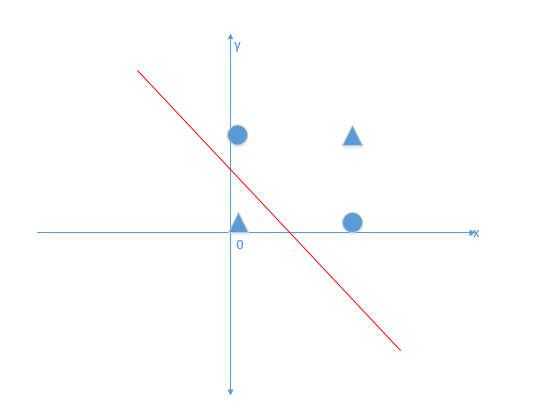
xor即异或运算的函数,输入两个bool数值(取值0或者1),当两个数值不同时输出为1,否则输出为0。如下图,可知XOR数据无法通过线性模型的边界正确的区分开
由于单层神经网络线性,连简单的非线性的异或函数都无法正确的学习,而我们经常希望模型是可以学习非线性函数,这给了神经网络研究以沉重的打击,神经网络的研究走向长达10年的低潮时期。

如下以逻辑回归代码为例,尝试去学习XOR函数:
# 生成xor数据
import pandas as pd
xor_dataset = pd.DataFrame([[1,1,0],[1,0,1],[0,1,1],[0,0,0]],columns=['x0','x1','label'])
x,y = xor_dataset[['x0','x1']], xor_dataset['label']
xor_dataset.head()
from keras.layers import *
from keras.models import Sequential, Model
np.random.seed(0)
model = Sequential()
model.add(Dense(1, input_dim=2, activation='sigmoid'))
model.summary()
model.compile(optimizer='adam', loss='binary_crossentropy')
x,y = xor_dataset[['x0','x1']], xor_dataset['label']
model.fit(x, y, epochs=100000,verbose=False)
print("正确标签:",y.values)
print("模型预测:",model.predict(x).round())
# 正确标签: [0 1 1 0] 模型预测: [1 0 1 0]
结果可见,lr线性模型的拟合能力有限,无法学习非线性的XOR函数。那如何解决这个问题呢?
这就要说到线性模型的根本缺陷———无法使用变量间交互的非线性信息。
二、 如何学习非线性的XOR函数
如上文所谈,学习非线性函数的关键在于:模型要使用变量间交互的非线性信息。
解决思路很清晰了,要么,我们手动给模型加一些非线性特征作为输入(即特征生成的方法)。
要不然,增加模型的非线性表达能力(即非线性模型),模型可以自己对特征x增加一些ф(x)非线性交互转换。假设原线性模型的表达为f(x;w),非线性模型的表达为f(x, ф(x), w)。
2.1 方法:引入非线性特征
最简单的思路是我们手动加入些其他维度非线性特征,以提高模型非线性的表达能力。这也反映出了特征工程对于模型的重要性,模型很大程度上就是复杂特征+简单模型与简单特征+复杂模型的取舍。
# 加入非线性特征
from keras.layers import *
from keras.models import Sequential, Model
from tensorflow import random
np.random.seed(5) # 固定随机种子
random.set_seed(5)
model = Sequential()
model.add(Dense(1, input_dim=3, activation='sigmoid'))
model.summary()
model.compile(optimizer='adam', loss='binary_crossentropy')
xor_dataset['x2'] = xor_dataset['x0'] * xor_dataset['x1'] # 非线性特征
x,y = xor_dataset[['x0','x1','x2']], xor_dataset['label']
model.fit(x, y, epochs=10000,verbose=False)
print("正确标签:",y.values)
print("模型预测:",model.predict(x).round())
# 正确标签: [0 1 1 0] 模型预测: [0 1 1 0]
正确标签:[0 1 1 0] ,模型预测:[0 1 1 0],模型预测结果OK!
2.2 方法2:深度神经网络(MLP)
搬出万能近似定理,“一个前馈神经网络如果具有线性输出层和至少一层具有任何一种‘‘挤压’’ 性质的激活函数的隐藏层,只要给予网络足够数量的隐藏单元,它可以以任意的精度来近似任何从一个有限维空间到另一个有限维空间的Borel可测函数。”简单来说,前馈神经网络有“够深的网络层”以及“至少一层带激活函数的隐藏层”,既可以拟合任意的函数。
这里我们将逻辑回归加入一层的隐藏层,升级为一个两层的神经网络(MLP):
from keras.layers import *
from keras.models import Sequential, Model
from tensorflow import random
np.random.seed(0) # 随机种子
random.set_seed(0)
model = Sequential()
model.add(Dense(10, input_dim=2, activation='relu')) # 隐藏层
model.add(Dense(1, activation='sigmoid')) # 输出层
model.summary()
model.compile(optimizer='adam', loss='binary_crossentropy')
x,y = xor_dataset[['x0','x1']], xor_dataset['label']
model.fit(x, y, epochs=100000,verbose=False) # 训练模型
print("正确标签:",y.values)
print("模型预测:",model.predict(x).round())
正确标签:[0 1 1 0] ,模型预测:[[0.][1.][1.][0.]],模型预测结果OK!
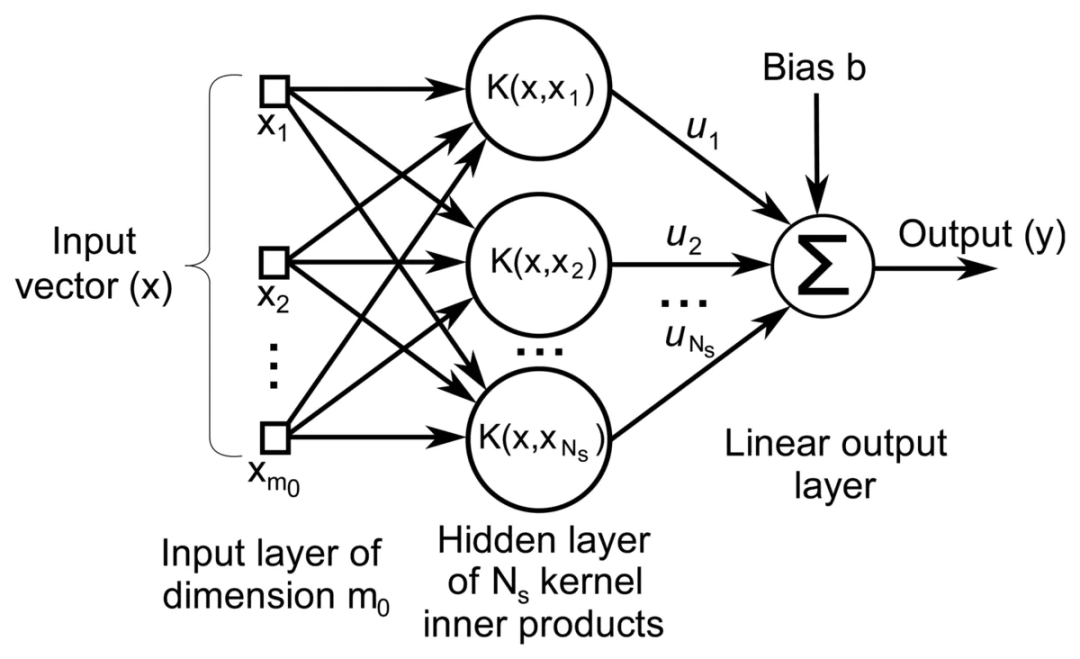
2.3 方法3:支持向量机的核函数
支持向量机(Support Vector Machine, SVM)可以视为在单隐藏层神经网络基础上的改进(svm具体原理可关注笔者后面的专题介绍),对于线性不可分的问题,不同于深度神经网络的增加非线性隐藏层,SVM利用非线性核函数,本质上都是实现特征空间的非线性变换,提升模型的非线性表达能力。
from sklearn.svm import SVC
svm = SVC()
svm.fit(x,y)
svm.predict(x)
正确标签:[0 1 1 0] 模型预测:[[0.][1.][1.][0.]],svm模型预测结果OK!
小结
归根结底,机器学习模型可以看作一个函数,本质能力是通过参数w去控制特征表示,以拟合目标值Y,最终学习到的决策函数f( x; w )。模型拟合能力的提升关键即是,能控制及利用特征间交互的非线性信息,实现特征空间的非线性变换。可以具体归结为以下两方面:
数据方面:通过特征工程 构造复杂特征。
模型方面:使用非线性的复杂模型。如:含非线性隐藏层的神经网络,非线性核函数svm,天然非线性的集成树模型。经验上讲,对这些异质模型做下模型融合效果会更好。
本文首发”算法进阶“,公众号阅读原文即访问文章相关代码