
改善图形神经网络,提升GNN性能的三个技巧

来源:DeepHub IMBA 本文约2800字,建议阅读8分钟
本文总结了一些技巧来提高 GNN 模型的性能。
GNN 提供了一种在图结构化数据上使用深度学习技术的方法。图结构数据无处不在:从化学(例如分子图)到社交媒体(例如社交网络)以及金融投资(例如 VC 投资网络),GNN 在各种任务中显示出最先进的性能¹ ²。
在我的以前的一个实践:在投资者、初创公司和个人组成的投资网络上预测初创公司未来的融资轮次,其基线随机森林模型已经相当强大(AUC = 0.69)。但是GNN 模型(AUC = 0.66)一直落后于基线模型的性能,并且增加层数和隐藏维度并没有帮助。所以我开始研究,发现 GNN 并不简单。
为了解决这个问题,本文总结了一些技巧来提高 GNN 模型的性能。
什么是 GNN?
在讨论如何改进 GNN 之前,让我们快速回顾一下它们的工作原理。假设我们有一个简单的图表,如下所示:
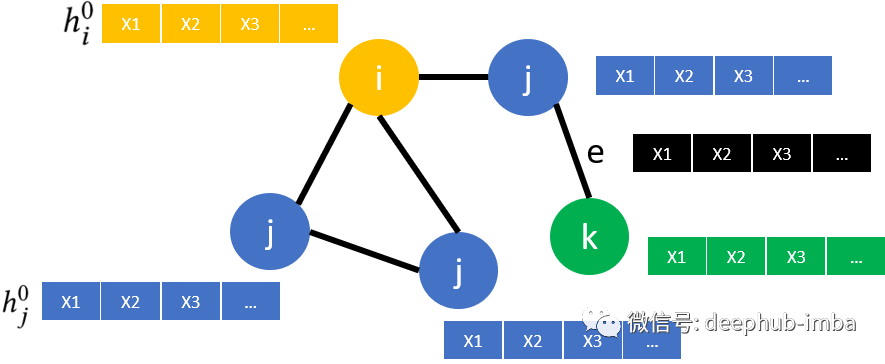
图
图包含节点(i、j 和 k)和连接这些节点的边(e)。此外,图还包括每个节点(X1,...)和可能的每条边(黑色)的节点特征。目标节点以黄色着色,其 1 跳邻居为蓝色,2 跳邻居以绿色表示。包括不同类型节点的图称为“异构”图,就像上面的例子一样。
消息传递
步骤 0 中节点的嵌入只是由其自身的特征向量(由特征 X1、X2……组成)。为了获得新的 (l + 1) 节点嵌入 h,对于目标节点 i(黄色),需要从其相邻节点 j(蓝色)中提取所有嵌入,提取其自身的表示以及潜在的边缘特征e(黑色)并聚合该信息。这具体步骤参考下面的公式。但是,目前大多数著名的 GNN 架构都没有使用边缘特征⁵。在提取特征之后就可以将这些新的节点嵌入用于各种任务,例如节点分类、链接预测或图分类。
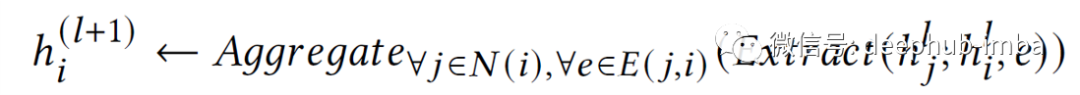
GNN 的问题
许多最近跨领域的研究发现 GNN 模型没有提供预期的性能⁵ ⁶ ⁷。当研究人员将它们与更简单的基于树的基线模型进行比较时,GNN 甚至无法超越基线的模型,例如我们上面提到的随机森林。
一些研究人员对 GNN 有时表现不佳提供了理论解释⁸。根据他们的实验,GNN 只进行特征去噪,无法学习非线性流形。因此他们主张将 GNN 视为图学习模型的一种机制(例如,用于特征去噪),而不是他们自己的完整的端到端模型。
为了解决这些问题并提升 GNN,本文总结了 3 个主要技巧/想法:
在 GNN 中利用边缘特征
GNN 的自我监督预训练
分离前置和下游任务
利用边缘特征
利用边缘特征的想法在很大程度上取决于正在使用的数据类型。如果数据包含(多维)边缘特征,则利用边缘特征可以对模型的性能产生影响。
但是很少有已建立的 GNN 模型架构支持多维边缘特征⁵。以我的经验,使用过并且效果很好的一个简单的解决方法是创建人造节点:
通过使用人造节点,可以继续使用以前使用的相同模型。而唯一要改变的是图本身,新增节点会使图变得更复杂。每条边都将成为连接到原始深蓝色节点的自身节点(浅蓝色),而不是保存边特征的边。
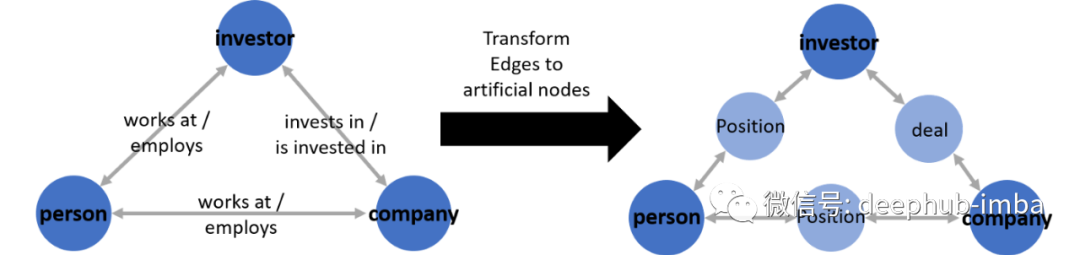
通过将边缘特征作为人造节点的节点特征传递给模型来间接利用边缘特征。如果边缘特征与任务相关,这可以提高模型的性能,但也会增加复杂性。并且需要考虑向模型中添加更多 GNN 层(以允许更多邻居跳)。人造节点可以使 AUC 增加约 2%(我的经验)。
除此以外还可以创建自己的 GNN 层实现。这听起来很难;但是如果使用 DGL 之类的图学习库,那绝对是可行的。
例如,下面根据 GAT¹⁰ 和 R-GCN¹ 的现有想法制定了自己的实现,称之为 Edge-GCN¹¹:
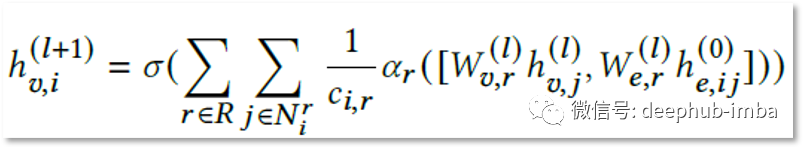
我自己的 Edge-GCN 公式(v 代表节点,e 代表边,sigma 是非线性激活函数 [在这种情况下为 RELU],alpha 是每个关系类型的学习注意力分数,c 是归一化常数)
Edge-GCN 使用注意力机制来学习边缘与节点特征对所有不同关系类型的重要性¹¹。E-GCN 架构在 AUC 中将 GNN 模型的结果提高了约 2%(人造节点也是如此)。
自监督预训练
这可能是提高 GNN 性能的最重要技巧。尽管预训练 GNN 已经在理论上进行了探索¹²,但在实践中的应用仍然很少⁶ ⁷ ⁸。
总体思路与计算机视觉和自然语言处理领域的概念非常相似。以语言模型 BERT¹³ 为例,该模型经过训练可预测句子中的掩蔽词(这是自监督的,因为它不依赖于标记数据)。我们通常不太关心预测掩蔽词的具体任务。但是生成的词嵌入对于许多不同的任务非常有用,因为模型真的了解特定词之间的关系。
使用自监督任务预训练 GNN 模型节点嵌入,这在有噪声标签的情况下尤其有益,因为自我监督过程提供了更多“标记”示例(因为我们不需要为预训练提供标签)并且可能也不太容易受到噪声干扰¹¹ ¹²。
如果我们的最终目标是对节点进行分类,可以在整个图上使用链接预测作为自我监督的预训练任务。在链接预测中,我们尝试预测两个节点之间是否存在边(=链接)。因此训练一个 GNN 来区分图中的真实边和人为引入的假边(“链接预测的负采样”)。由于我们只是在图中现有节点之间添加假边并删除真实边,因此可以不依赖任何标记数据。接下来的步骤就是使用来自链接预测 GNN 模型的结果节点嵌入作为另一个节点分类模型的输入。
向模型添加一个自我监督的预训练管道将其 AUC 分数增加了 14%,这可以说是目前最有效的技巧。
分离前置和下游任务
到目前为止,只讨论了在自监督任务(“前置”)上预训练 GNN 并为最终(“下游”)任务使用相同的 GNN 架构。但是其实可以为这两个任务使用不同的模型架构。甚至还可以组合出不同的 GNN 架构。
GNN 层可能无法在各种情况下有效地学习。因此可以使用 GNN 模型通过自监督预训练创建节点嵌入,并将这些嵌入传递给经典机器学习算法或全连接的神经网络层,以完成最终的下游任务。这种架构可用于许多不同的下游任务,例如图分类到节点分类还有回归。
该模型将受益于将访问图中包含的所有信息的能力与非线性流形学习属性相结合。该模型从更简单的机器学习算法中继承了一些好处,例如减少了训练时间和更好的可解释性。文章最初提到的基于树的模型(例如随机森林)在节点分类的下游任务¹¹中表现出特别强的性能,所以我们就从这里开始。
在下面,可以找到包含上面提出的三个想法的最终管道的概述:
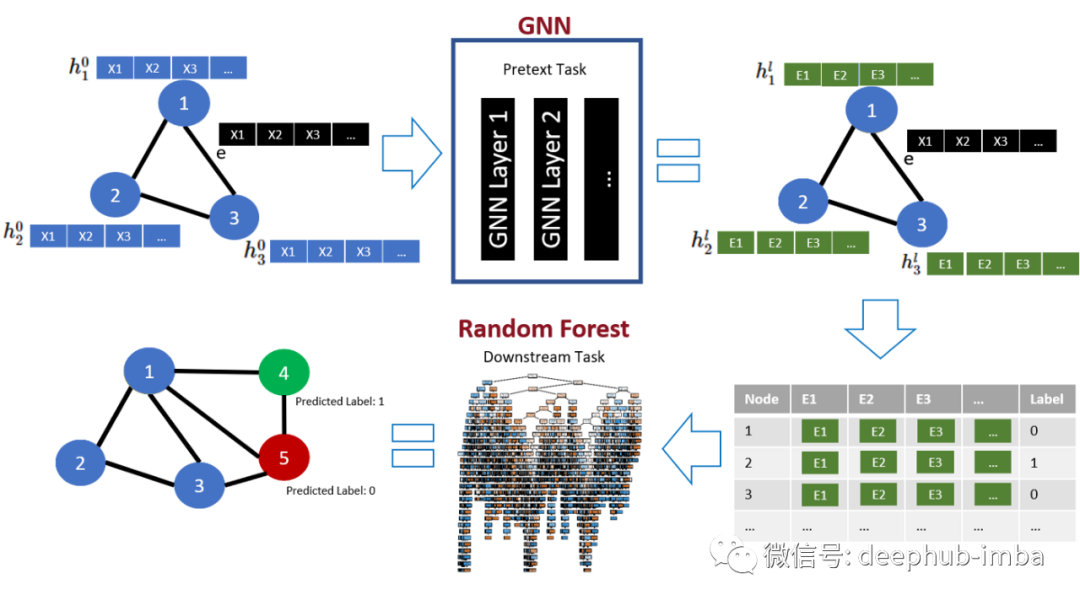
该架构代表了我们的最终模型,AUC 得分为 78.1(另一个 + 1.5%),通过 AUC 衡量的性能总提升 17%(基本 R-GCN 模型:AUC = 66.6)¹¹。
总结
在这篇文章中,我们讨论了图神经网络模型的缺点以及提高模型性能的三个主要技巧。结合这些技巧,能够将最终 GNN 模型的 AUC¹¹ 提高 17%(对于其他指标甚至更多)。下面我们再总结一下我们的步骤:
如果数据包含边缘特征,并且你认为它们对最终预测任务很有洞察力,可以尝试利用边缘特征。
其次,使用自监督目标对 GNN 模型进行预训练通常有利于最终模型的性能。它可以增加训练示例的数量,有时还可以减少固有噪声。
最后,为前置和最终预测任务测试不同的架构可以提高模型的预测能力。