
前沿技术 | 自动机器学习综述
点击下方卡片,关注“新机器视觉”公众号
视觉/图像重磅干货,第一时间送达
来源:小金博士公众号 本文约5000字,建议阅读10分钟 本文将探索目前可用于自动化过程的框架,以帮助读者了解在自动化机器学习方面可能出现的情况。
自动机器学习综述
自动化工程特点 自动的模型选择和超参数调优 自动神经网络架构选择(NAS) 自动部署
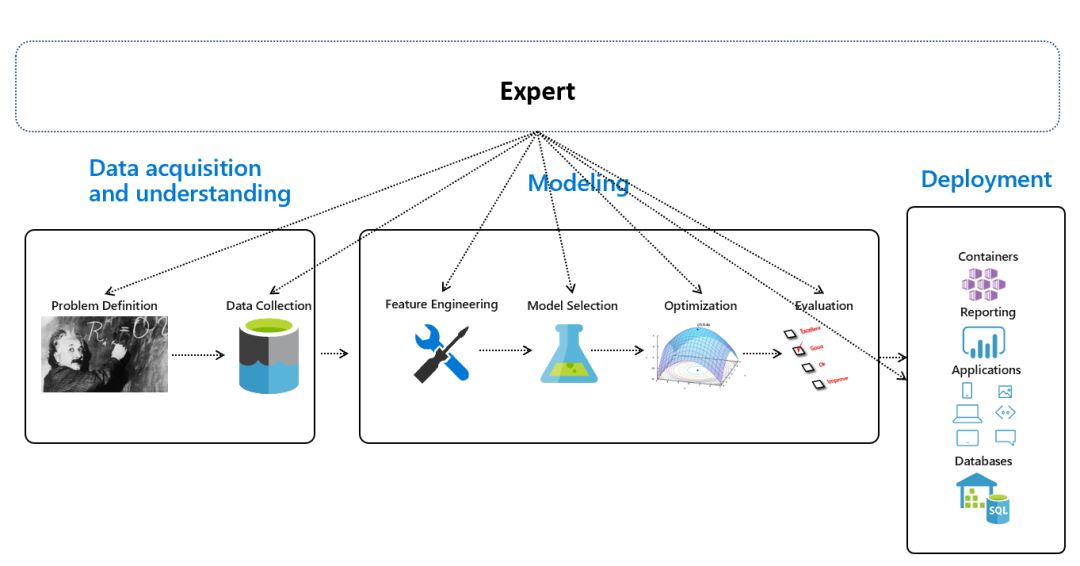
自动特征工程
“客户下单的频率” “上次购买后的天数或小时数” “顾客通常购买的商品类型”
框架
「数据科学机器」是由麻省理工学院的Max Kanter和Kalyan Verramachaneni进行的一个研究项目。他们的研究论文概述了深度特征合成算法的内部工作原理,该算法使用原语的概念来为实体(数据中唯一的观察)和实体之间的关系生成特征。基本类型本质上是应用于数据的数学函数(sum、mean、max、min、average等),这些函数返回不区分大小写的数字结果,并且可以由人类解释为表示不同的东西。在我们的电子商务示例中,sum可用于计算针对特定客户的所有订单所花费的美元金额。以飞机票务平台为例,它可用于计算客户已购买的当年机票的数量。不同的用例但是相同的数学原语。这是在Featuretools Python库下开源的,可以尝试下载并试用它。Featuretools是由Feature Labs开发的,它将数据科学机器研究论文中的工作进行了操作化。Feature Labs是数据科学机器的创造者Max和Kalyan创建的一家公司。 DataRobot使用一个称为模型蓝图的概念来实现自动化特征工程,该概念在机器学习管道中堆叠了不同的预处理步骤。特性工程部分不像在Featuretools中那样利用原语的概念。然而,它确实对数据应用了一些标准的预处理技术(基于所使用的ML算法,例如随机森林、逻辑回归等),如单热编码、输入、类别计数、在自由文本列中出现的n个字符标记、比率等。 H2O的无人驾驶人工智能是一个自动机器学习的平台。它可以用于自动化特性工程、模型验证、模型调优、模型选择和模型部署。在这一部分,我们将只讨论无人驾驶AI的自动特性工程部分。无人驾驶智能支持一系列的所谓的“transformers”,可以应用于一个数据集。 tsfresh是一个用于从时间序列数据中计算和提取特征的Python库。它提取了中位数、均值、样本熵、分位数、偏度、方差、值计数、峰数等特征。它没有泛化所有类型的数据集。它更针对于时间序列数据。但是,它可以与上面提到的其他工具一起使用。
自动选择模型和超参数调整
auto-sklearn是由Mathias Feurer, Aaron Klein, Katharina Eggensperger等人创建的Python库。这个库主要处理机器学习中的两个核心过程:从分类和回归算法的广泛列表中选择算法和超参数优化。这个库不执行特性工程,因为数据集特性是通过组合使用数学原语(如Featuretools)来创建新特性的。Auto-sklearn类似于Auto-WEKA和Hyperopt-sklearn。下面是auto-sklearn可以从决策树、高斯朴素贝叶斯、梯度增强、kNN、LDA、SVM、随机森林和线性分类器(SGD)中选择的一些分类器。在预处理步骤上,它支持以下几个方面:内核主成分分析,选择百分位数,选择率,一热编码,归位,平衡,缩放,特征聚集,等等。同样,从通过组合现有特性来丰富数据集的角度来看,这些都不能理解为特性工程步骤。 有些算法会自动地通过一系列不同的变量配置来优化某些指标。这类似于寻找可变的重要性。通常,通过理解变量存在的上下文和域,人们可以很好地完成这项工作。例如:“夏季销量增加”或“最昂贵的商品来自西伦敦居民”。这些变量可以由人类领域专家自然地暗示出来。然而,还有另一种方法来理解一个变量的重要性,那就是看这个变量在统计上有多重要。这是由决策树(使用所谓的基尼指数或信息增益)等算法自动完成的。随机森林也这样做,但与决策树不同,随机森林运行多个决策树,以创建引入了随机性的多个模型。 对于时间序列数据,我们倾向于讨论汽车。R中的arima包使用AIC作为优化指标。自动生成的算法。arima在后台使用Hyndman-Khandakar来实现这一点,在下面的OText书中有详细的解释。 如前所述,H2O无人驾驶AI可以用于自动化特征工程。它还可以用来自动训练多个算法在同一时间。这是由h2o实现的。automl包。它可以自动训练您的数据使用多种不同的算法与不同的参数,如GLM, Xgboost随机森林,深度学习,集成模型,等等。 DataRobot还可以用于同时自动训练多个算法。这是通过使用经DataRobot科学家调整过的模型实现的,因此能够使用预先设置的超参数运行几十个模型。它最终会选择一个准确率最高的算法。它还允许数据科学家手动干预和调整模型,以提高准确性。 微软在9月宣布了自己的自动化机器学习工具包。事实上,该产品本身被称为automatic ML,属于Azure机器学习产品。微软的自动ML利用协同过滤和贝叶斯优化来搜索机器学习的空间。Microsoft指的是数据预处理步骤、学习算法和超参数配置的组合。在上面讨论的许多模型选择技术中,ML学习过程中自动化的典型部分是超参数设置。微软的研究人员发现,只调优超参数有时可以与随机搜索相媲美,因此理想情况下,整个端到端流程应该是自动化的。

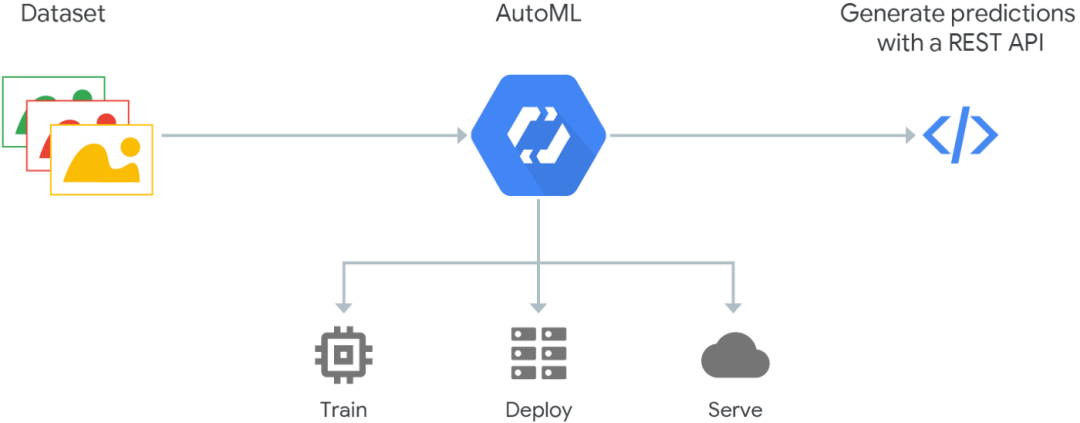
谷歌也在这个领域进行了创新,推出了谷歌云自动化。在Cloud AutoML谷歌中,通过只从用户获取标记数据并自动构建和训练算法,数据科学家能够训练计算机视觉、自然语言处理和翻译的模型。
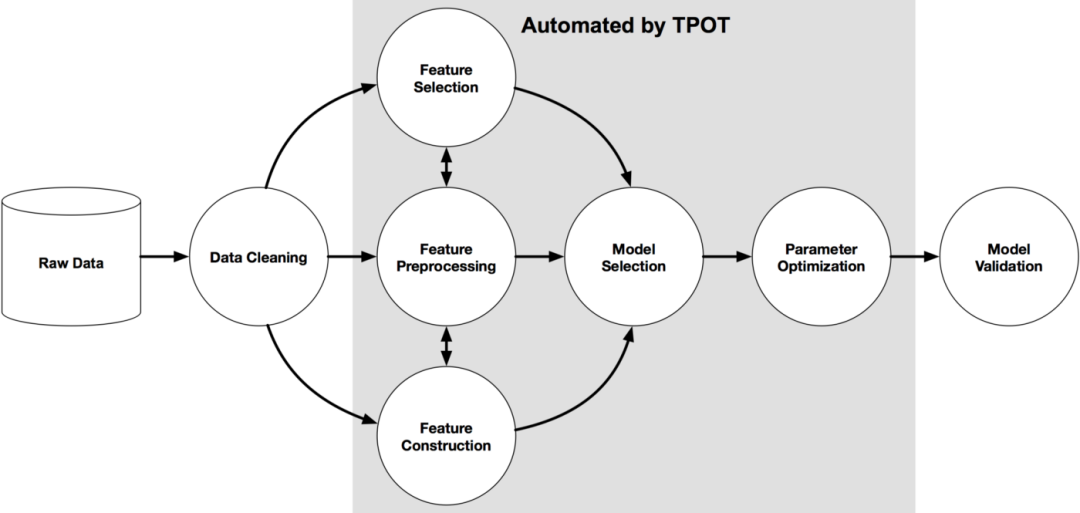
TPOT是用于自动化机器学习的Python库,它利用遗传编程优化机器学习管道。ML管道包括数据清理、特征选择、特征预处理、特征构建、模型选择和参数优化。TPOT库利用了scikit-learn中可用的机器学习库。
Amazon Sage Maker提供了建模、培训和部署的能力。它可以自动调整算法,为了做到这一点,它使用了一种叫做贝叶斯优化的技术 HyperDrive是微软的产品,是为全面的超参数探索而建立的。超参数搜索空间可以用随机搜索、网格搜索或贝叶斯优化来覆盖。它实现了一个调度器列表,您可以选择通过联合优化质量和成本来提前终止探索阶段。
神经网络结构选择
NASNet-学习可扩展的图像识别的可转移的体系结构
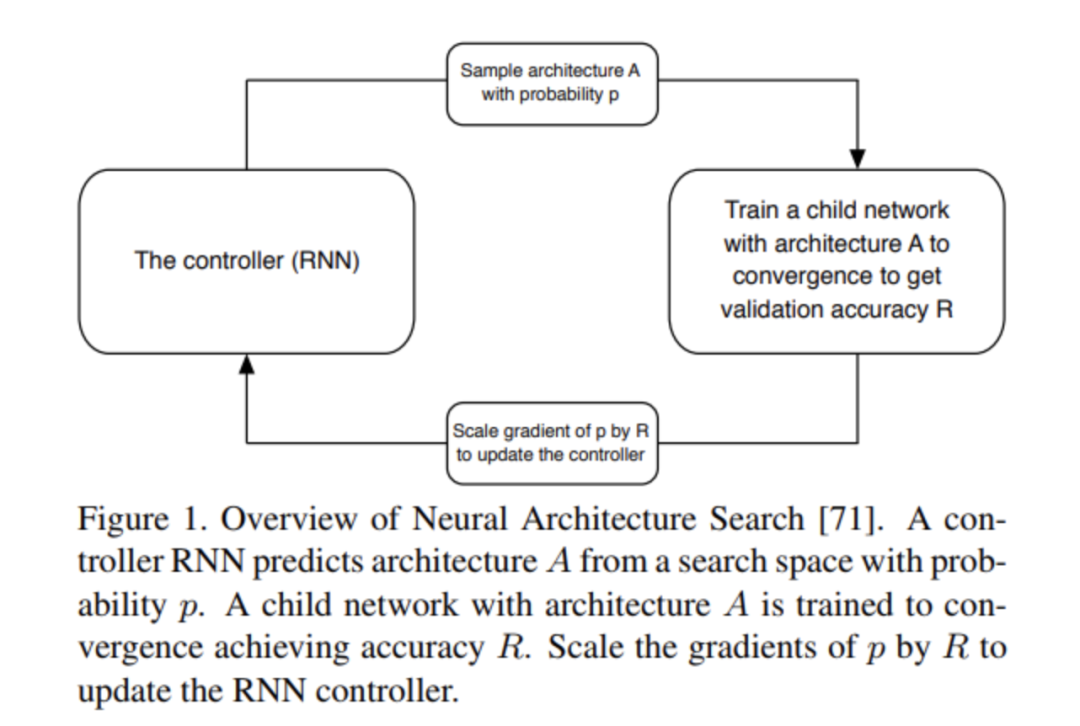
AmoebaNet-基于AmoebaNet正则化演化的图像分类器体系结构搜索 ENAS-高效的神经结构搜索
自动部署
Seldon-提供了一些方法来包装用R、Python、Java和NodeJS构建的模型,并将其部署到Kubernetes集群中。它提供与kubeflow、IBM用于深度学习的fabric、NVIDIA TensorRT、DL推理服务器、Tensorflow服务等的集成。 Redis-ML-是Redis(内存中分布式键值数据库)中的一个模块,它允许将模型部署到生产环境中。它目前只支持以下算法:随机森林(分类和回归)、线性回归和逻辑回归。 Apache MXNet的模型服务器用于服务从MXNet或Open Neural Network Exchange (ONNX)导出的深度学习模型。 Microsoft机器学习服务允许您将模型作为web服务部署在可伸缩的Kubernetes集群上,并且可以将模型作为web服务调用。 可以使用Amazon SageMaker将模型部署到HTTPS端点,应用程序利用该端点对新数据观察进行推断/预测。 谷歌云ML还支持模型部署和通过对托管模型的web服务的HTTP调用进行推断。默认情况下,它将模型的大小限制为250 MB。 H2O通过利用Java mojo(优化的模型对象)的概念来支持模型的部署。mojo支持自动、深度学习、DRF、GBM、GLM、GLRM、K-Means、堆栈集成、支持向量机、Word2vec和XGBoost模型。它与Java类型环境高度集成。对于非java编程模型(如R或Python),可以将模型保存为序列化对象,并在推断时加载。 TensorFlow服务用于将TensorFlow模型部署到生产环境中。在几行代码中,您就可以将tensorflow模型用作预测的API。 如果您的模型已经被训练并导出为PMML格式,那么Openscoring可以帮助您将这些PMML模型作为推断的REST api提供服务。 创建GraphPipe的目的是将ML模型部署与框架特定的模型实现(例如Tensorflow、Caffe2、ONNX)解耦。
编辑:黄继彦
—版权声明—
仅用于学术分享,版权属于原作者。
若有侵权,请联系微信号:yiyang-sy 删除或修改!
评论