
DIGIX全球算法精英大赛-视频推荐任务亚军方案分享
今天老肥和大家分享的是DIGIX全球算法精英大赛赛题三-基于多目标优化的视频推荐的亚军方案,主要使用的是特征工程为主的树模型和深度模型的融合方案。
赛题任务
本赛题的目标是基于用户前十四天的行为信息以及用户侧信息表、视频侧信息表对用户第十五天的视频观看时长以及是否分享进行预测(其中视频时长的评价指标为加权分桶AUC)。
数据分析
通过对两个预测目标进行分析,我们发现发生分享行为的用户大部分都是存在观看行为的,观看视频时长越长分享的概率越高,这些也符合直观的理解,观看视频之后进行视频的分享,但是当我们对这两个任务进行联合建模,也就是多任务学习发现效果较差,我们推测是两个任务稀疏程度差距较大,很难通过调节loss权重的方法同时将两个任务学得好,所以对于本赛题我们还是采用分开建模的方法。
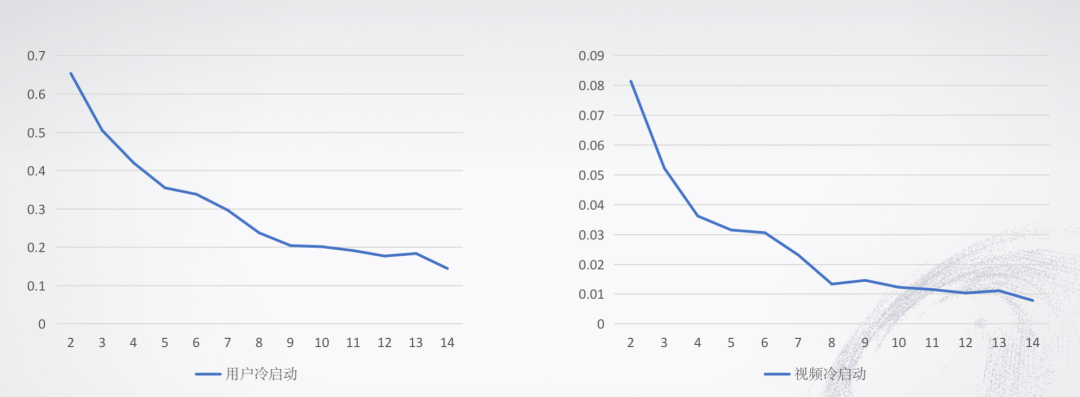
通过分析数据,我们发现该赛题存在着用户冷启动的问题(非完全冷启动,只是在用户行为表历史中未出现),而冷启动用户的平均观看时长要高于非冷启动用户,冷启动视频也存在相似情况。第十二天的异常我们也发现了原因,说来也很有意思,4月30日也就是出现这个异常的前一天,我国空间站天和核心舱成功发射,而这个异常的冷启动视频之一正是《太空救援》,应该是来源于时事相关的影片强力推送。
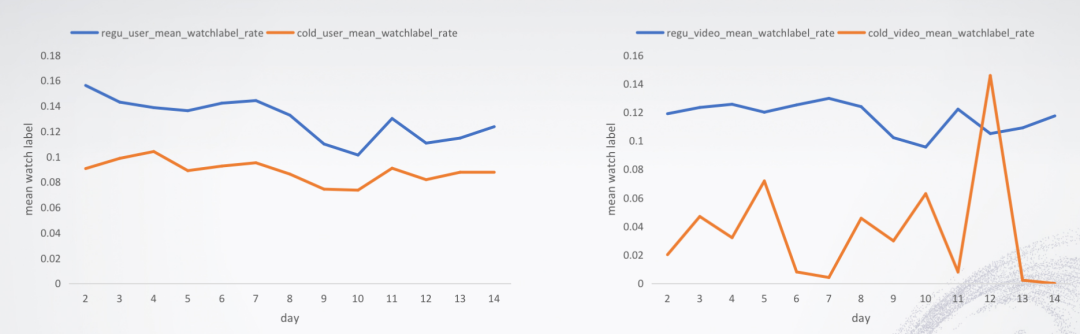
所以我们在做CTR类型的时候对冷启动用户做填充采用的是冷启动用户的CTR均值。另外我们还通过观察数据发现,由于是长视频场景下的推荐任务,不少用户存在着看不完视频的情况,发生这种情况后用户很有可能在后续的日子里继续对该视频进行观看,针对该现象,我们也做了相应的特征提取。
特征工程
特征部分的话首先是统计特征部分,统计特征包括曝光特征、交叉特征、CTR特征,CTR特征主要是用户侧以及视频侧id类特征的历史观看比率、分享比率等等。
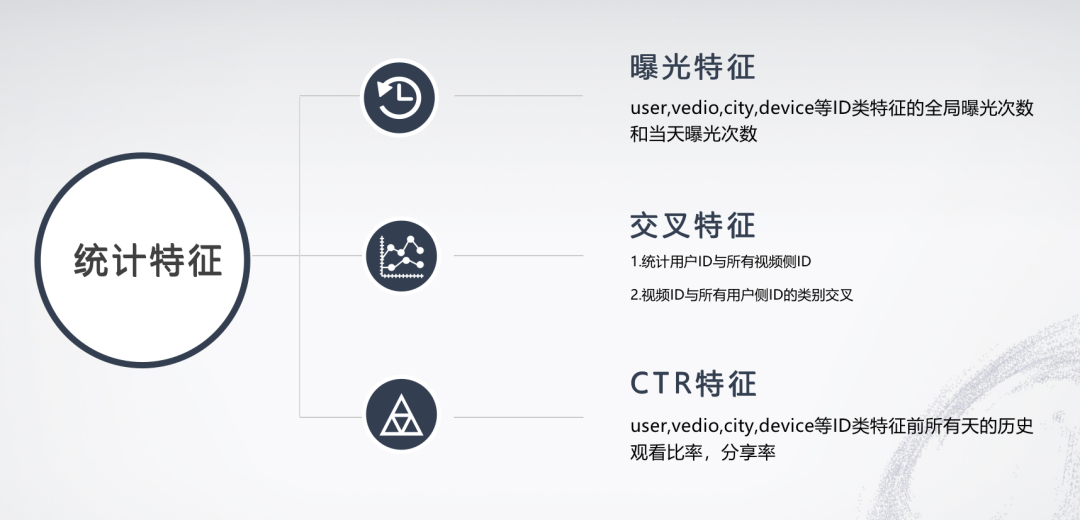
对于序列特征以及多标签特征,我们直接采用word2vec来做embedding表征。衍生特征主要就是上述数据分析所提到的对用户曾经观看过的视频做count计数统计等。

损失函数
因为正样本过于稀疏,我们保留所有正样本,采用负样本的10%随机采样。这里对NN模型采用了Focal Loss作为损失函数,α参数的话通过样本标签的比例确定。树模型的损失函数还是使用交叉熵,对各个类别的样本做加权处理,加权的方式为分数权重/样本分布比例。
权重搜索
对于视频时长预测的目标,我们可以对测试样本的类别预测权重进行搜索,以期得到更高的加权AUC值。我们这里直接采用基于贪心的权重搜索方法,先对类别一搜索最佳的权值,然后固定类别一的权值,对类别二进行搜索,直至完成所有类别的权值搜索。
实验过程
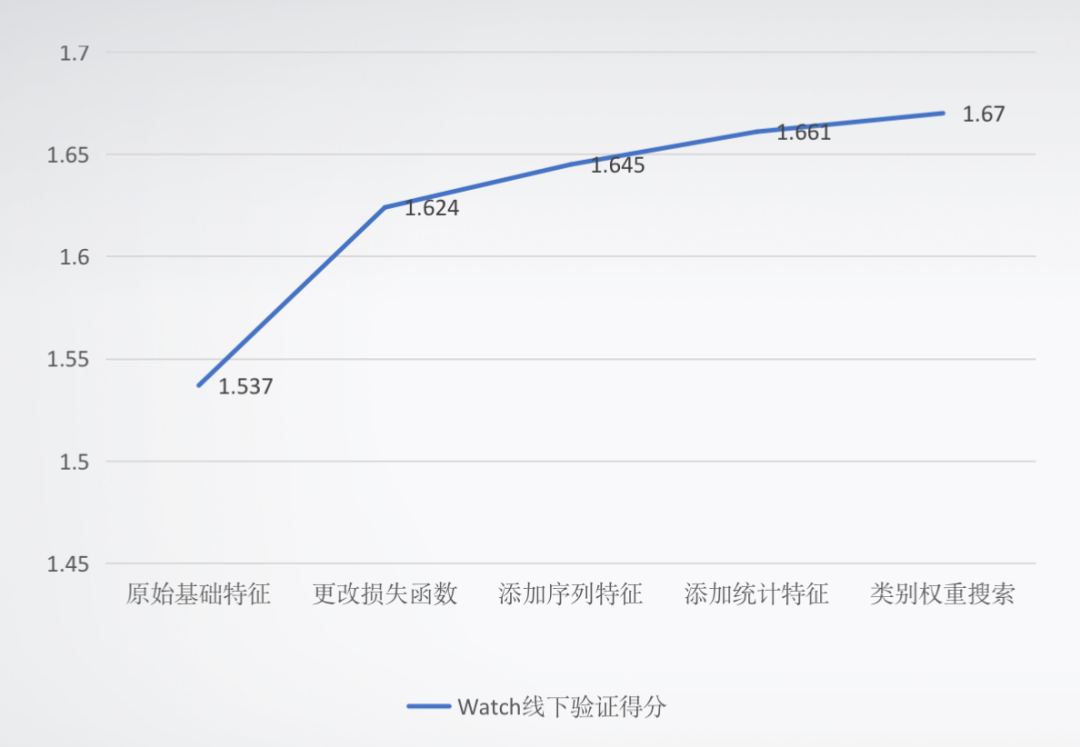
这里给出我们比赛期间进行上分的一个总结,NN模型对视频时长预测进行单独建模,树模型使用同一套特征同时对视频时长和是否分享进行建模。
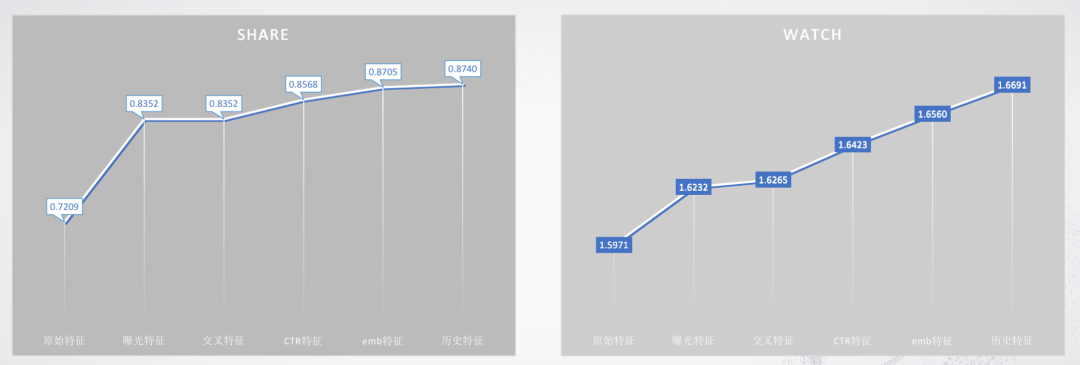
以上就是我所分享的全部内容啦,代码我会在整理后开源到GitHub(阅读原文),感谢两位大腿带我@汪兔摸鱼、@Ernnnn,大家感兴趣也可以关注@Ernnnn的同名b站,不定时更新硬核视频哟。
——END——