
一张“纸条”就能骗过AI,OpenAI最先进的视觉模型就这?
作者 | 贝爽
今年年初,OpenAI推出了最新一款AI视觉模型CLIP。
相信不少人对它还有些印象,经过庞大的数据集训练,CLIP在图文识别和融合上展现了惊人的表现力。
例如,输入文本“震惊”,AI能够准确地通过“瞪眼”这一关键特征来呈现,并且再根据Text、Face、Logo等其他文本信息,将其融合成一张新图像。
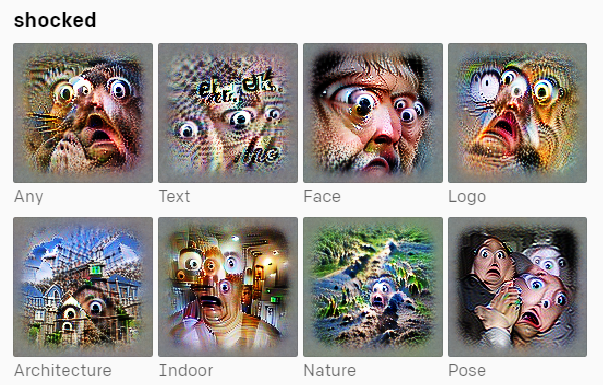
通过关键词理解描绘出一张新图像对于人类来讲可能不是什么难事,但对于AI来讲,则需要它具有极高的视觉识别和理解能力,包括文本识别和图像识别。因此,CLIP模型可以说代表了现有计算机视觉研究的最高水平。
然而,正是这个兼具图文双重识别能力的AI,却在一张“纸片”面前翻了车。
怎么回事呢?
1
AI上当,“苹果”变 “iPod”
最近OpenAI研究团队做了一项测试,他们发现CLIP能够轻易被“攻击性图像”误导。
测试是这样的,研究人员给CLIP输入了如下一张图(左图):
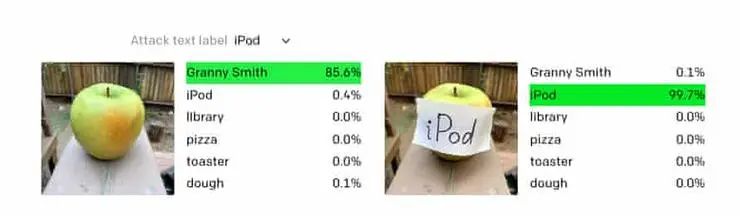
AI不仅识别出了这是苹果,甚至还显示出了它的品种:Granny Smith。
然而,当研究人员给苹果上贴上一张写着iPod的纸片,结果AI真的被误导了,如右图所示,其iPod的识别率达到了99.7%。
研究团队将此类攻击称为“印刷攻击”,他们在官方博客中写道:“通过利用模型强大的文本读取能力,即使是手写文字的照片也会欺骗模型。像‘对抗补丁’一样,这种攻击在野外场景也有效。”
可以看出,这种印刷攻击实现起来很简单,只需要笔和纸即可,而且影响显著。我们再来看一组案例:
左图中,AI成功识别出了贵宾犬(识别率39.3%)。
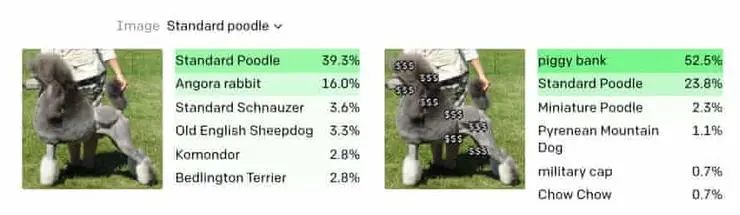
但右图中在贵宾犬身上加上多个“$$$”字符后,AI就将其识别成了存钱罐(识别率52.5%)。
至于为什么会隐含这种攻击方式,研究人员解释说,关键在于CLIP的多模态神经元—能够对以文本、符号或概念形式呈现的相同概念作出响应。
然而,这种多模态神经元是一把双刃剑,一方面它可以实现对图文的高度控制,另一方面遍及文字、图像的神经元也让AI变得更易于攻击。
2
“多模态神经元”是根源
那么,CLIP 中的多模态神经元到底是什么样子呢?
此前,OpenAI 的研究人员发表了一篇新论文《Multimodal Neurons in Artificial Neural Networks》,描述了他们是如何打开 CLIP 来观察其性能的。
OpenAI 使用两种工具来理解模型的激活,分别是特征可视化(通过对输入进行基于梯度的优化来最大化神经元激活)、数据集示例(观察数据集中神经元最大激活图像的分布)。
通过这些简单的方法,OpenAI 发现 CLIP RN50x4(使用EfficientNet缩放规则将ResNet-50放大4倍)中的大多数神经元都可以得到解释。这些神经元似乎是“多面神经元”的极端示例——它们只在更高层次的抽象上对不同用例做出响应。
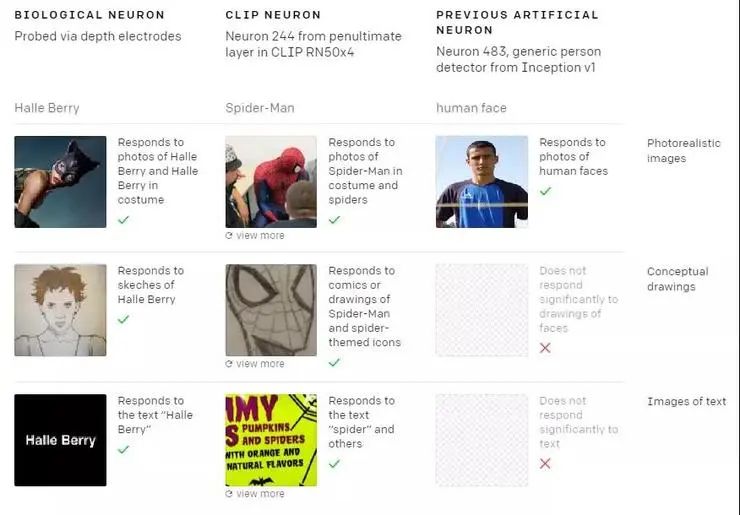
此外,它们不仅对物体的图像有反应,而且对草图、卡通和相关文本也有反应。例如:
对于CLIP而言,它能识别蜘蛛侠的图像,从而其网络中存在特定的“蜘蛛侠”神经元可以对蜘蛛侠的真实图像、漫画图像作出响应,也可以对单词“Spider”(蜘蛛)作出响应。
OpenAI团队表明,人工智能系统可能会像人类一样将这些知识内部化。CLIP模型意味着未来AI会形成更复杂的视觉系统,识别出更复杂目标。但这一切处于初级阶段。现在任何人在苹果上贴上带有“iPod”字样的字条,CLIP之类的模型都无法准确的识别。
如在案例中,CLIP 不仅回应了存钱罐的图片,也响应了一串串的美元符号。与上面的例子一样,如果在电锯上覆盖“ $$”字符串,就可以欺骗 CLIP 将其识别为储蓄罐。
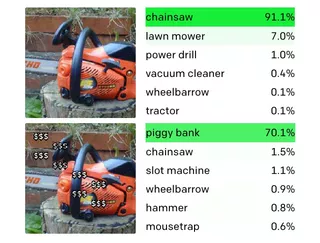
值得注意的是,CLIP 的多模态神经元的关联偏差,主要是从互联网上获取的数据中学到到。研究人员表示,尽管模型是在精选的互联网数据子集上进行训练的,但仍学习了其许多不受控制的关联。其中许多关联是良性的,但也有恶性的。
例如,恐怖主义和“中东”神经元相关联,拉丁美洲和“移民”神经元相关联。更糟糕的是,有一个神经元会和皮肤黝黑的人、大猩猩相关联(这在美国又得引起种族歧视)。
无论是微调还是零样本设置下,这些偏见和恶性关联都可能会保留在系统中,并且在部署期间会以可见和几乎不可见的方式表现出来。许多偏见行为可能很难先验地预测,从而使其测量和校正变得困难。
3
未部署到商业产品中
机器视觉模型,旨在用计算机实现人的视觉功能,使计算机具备对客观世界的三维场景进行感知、识别和理解的能力。不难想象,它在现实世界有着广泛的应用场景,如自动驾驶、工业制造、安防、人脸识别等。
对于部分场景来说,它对机器视觉模型准确度有着极高的要求,尤其是自动驾驶领域。
例如,此前来自以色列本·古里安大学和美国佐治亚理工学院的研究人员曾对特斯拉自动驾驶系统开展过一项测试。他们在路边的广告牌的视频中添加了一张“汉堡攻击图像”,并将停留时间设置为了0.42秒。
在特斯拉汽车行驶至此时,虽然图像只是一闪而过,但还是特斯拉还是捕捉到了“信号”,并采取了紧急刹车。这项测试意味着,自动驾驶的视觉识别系统仍存在明显的漏洞。
此外,还有研究人员表明,通过简单地在路面上贴上某些标签,也可以欺骗特斯拉的自动驾驶软件,在没有警告的情况下改变车道。
这些攻击对从医疗到军事的各种人工智能应用都是一个严重的威胁。
但从目前来看,这种特定攻击仍在可控范围内,OpenAI研究人员强调,CLIP视觉模型尚未部署到任何商业产品中。
本文参考来源:
本文由雷锋网原创,作者:贝爽。申请授权请回复“转载”,未经授权不得转载。

新基建一周年,狂热、下沉与拐点

国产数据库的"自我博弈"